高效大规模矩阵乘法映射技术研究:基于NoC多核系统的探索
版权申诉
80 浏览量
更新于2024-02-22
收藏 656KB DOCX 举报
基于NoC多核系统的矩阵乘法映射技术是研究领域中的一个重要课题。矩阵乘法在数字信号处理、工程控制、神经网络以及图像处理等领域中有着重要的应用。随着待计算矩阵规模的不断扩大,实现一个大规模且有较高运算性能的矩阵乘法器具有重大的工程意义。脉动阵列算法将矩阵乘法自身良好的运算并行性和硬件的并行特性结合在一起,为后续利用硬件结构实现复杂的运算奠定了基础。在FPGA上实现脉动阵列矩阵乘法已经取得了一些研究成果。在浮点矩阵乘法方面,文献提出了一个基于FPGA的Systolic乘法,保留了脉动阵列的运算速度。但随着矩阵规模的增大,该算法需要的运算资源和I/O带宽成比例增长,限制了该设计的可扩展性,导致实用性较低。上述研究虽然在特定规模下的矩阵乘法中获得了优越的加速性能,但随着矩阵规模的变化,上述方案的性能优势难以体现,对不同维度的矩阵乘法通用性不高。
本文针对上述问题,提出了一种基于NoC多核系统的矩阵乘法映射技术,该技术能够有效地实现大规模且高性能的矩阵乘法计算。通过利用NoC多核系统的并行计算能力和通信能力,将矩阵乘法任务映射到多个处理核心上进行并行计算,从而提高了系统整体的计算性能。与传统的脉动阵列算法相比,该技术在处理大规模矩阵乘法时能够更好地发挥并行计算的优势,同时也有效地降低了I/O带宽的消耗,提高了系统的可扩展性和实用性。
在本文的研究中,我们首先分析了目前矩阵乘法算法在大规模矩阵计算方面存在的瓶颈问题,重点讨论了传统脉动阵列算法和基于FPGA的Systolic乘法存在的局限性。随后,我们详细介绍了基于NoC多核系统的矩阵乘法映射技术的设计原理和实现方法。通过在多核系统上动态划分矩阵乘法任务,并利用网络通信实现不同核心间的数据传输和协作计算,该技术能够更加高效地完成大规模矩阵乘法运算。同时,我们还设计了相应的调度算法和通信机制,以保证系统能够在不同规模的矩阵计算下获得稳定的性能表现。
为了验证该技术的有效性,我们针对不同规模和稀疏度的矩阵乘法进行了大量的仿真实验。通过与传统基于FPGA的算法进行性能对比,实验结果表明,基于NoC多核系统的矩阵乘法映射技术在大规模矩阵乘法计算中具有较高的计算性能和可扩展性,能够在保证计算精度的前提下显著提高计算效率。同时,该技术还在处理稀疏矩阵乘法时表现出良好的性能,能够更好地满足实际应用中对稀疏矩阵计算的需求。
总之,基于NoC多核系统的矩阵乘法映射技术在大规模矩阵计算方面具有重要的工程意义。该技术能够有效地利用多核系统的并行计算和通信能力,实现高效的矩阵乘法计算。未来,我们将进一步完善该技术的设计和实现,在更多的应用场景中进行验证,并探索其在其他计算密集型任务中的应用潜力。相信随着该技术的不断发展和应用,将为大规模矩阵计算和相关领域的研究带来新的机遇和挑战。
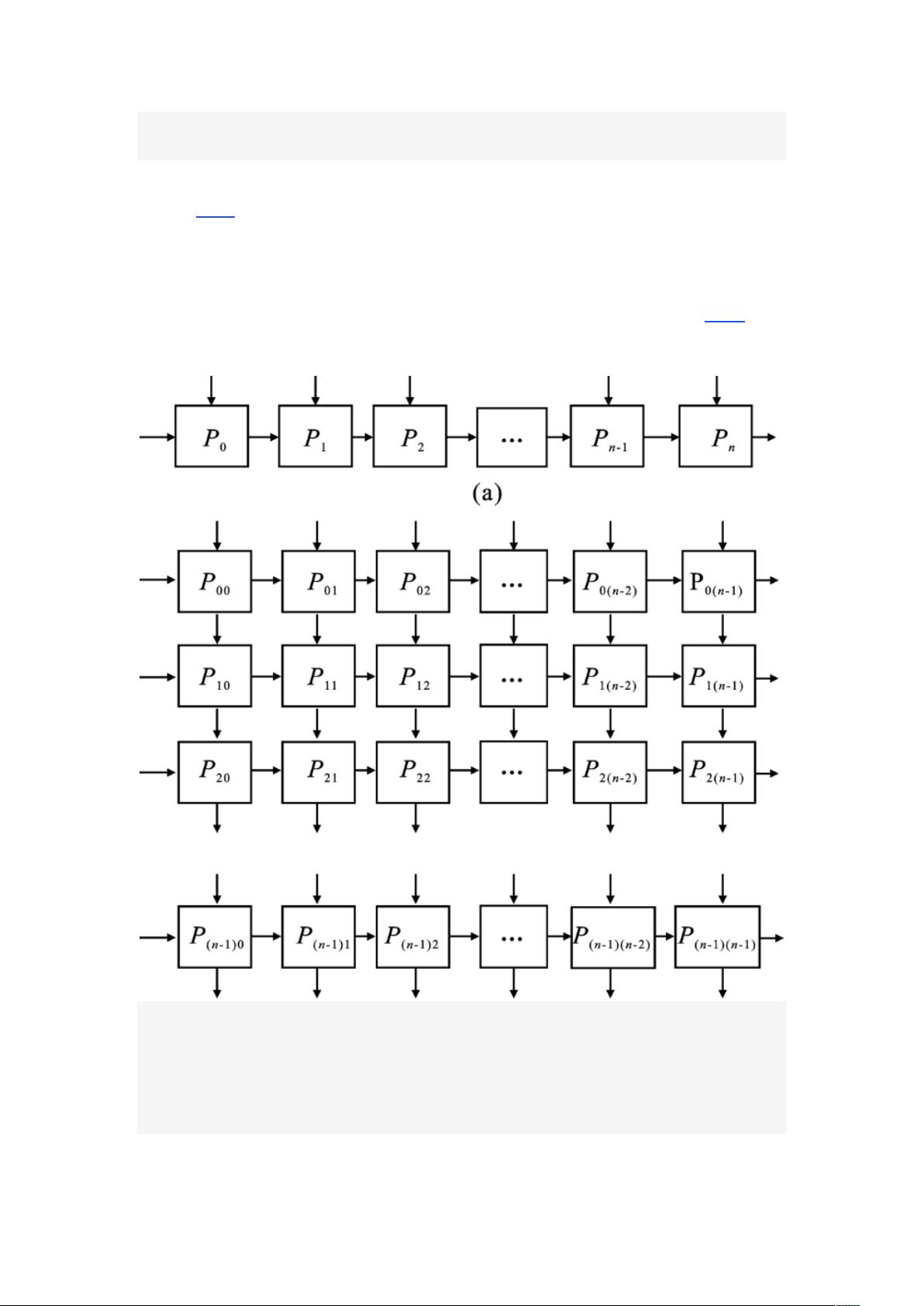
图 2 矩阵乘法的依赖图
Figure 2. RGD of matrix multiplication
由图 2 可知,迭代的标准输出形式可以表示为式(3)。
a(i,j,k)=a(i-1,j,k)b(i,j,k)=b(i,j-1,k)c(i,j,k)=c(i,j,k-1)+a(i,j,k)b(i,j,k)
(3)
用于矩阵运算的脉动阵列主要分为一维、二维脉动阵列结构,如图 3 所示。
图 3
图 3 脉动阵列结构图
(a)一维脉动阵列 (b)二维脉动阵列
Figure 3. Systolic array structure
(a) One dimensional systolic array (b) Two dimensional systolic array
剩余15页未读,继续阅读
2019-07-23 上传
2022-12-01 上传
2021-07-26 上传
2019-08-16 上传
2021-08-10 上传
2021-07-13 上传
2021-08-10 上传

罗伯特之技术屋
- 粉丝: 4418
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
