SpringCloud Sleuth与Zipkin整合实现服务追踪
99 浏览量
更新于2024-08-27
收藏 369KB PDF 举报
"本文主要介绍了如何使用SpringCloud Sleuth与Zipkin实现服务追踪,以便于在分布式系统中快速定位问题。Sleuth提供了基于Span、Trace和Annotation的概念,以构建服务间的跟踪信息。通过理解这些核心概念,我们可以更好地监控和诊断微服务架构中的性能瓶颈。在实际应用中,我们将展示如何在订单服务和商品服务中集成Sleuth,并配置Zipkin以可视化跟踪数据。"
在分布式系统中,服务追踪是解决复杂调用链路问题的关键。SpringCloud Sleuth提供了一个强大的工具,它集成了 Brave 和 Zipkin,使得追踪服务间交互变得简单。Sleuth的核心概念如下:
1. **Span**:Span 是基本的工作单元,代表一次操作或服务间的通信。每个 Span 包含一个唯一的 64 位 ID(span id),一个 64 位的 trace id 用于标识整个调用链,描述信息,时间戳,以及 key-value 形式的注解(tags)。根 Span 是链路的起点,它的 span id 和 trace id 相同。
2. **Trace**:一组相关 Span 的集合,它们按照时间顺序组成树形结构,共同构成一个完整的调用流程。
3. **Annotation**:用于记录关键事件的时间点,比如 cs(ClientSent)、sr(ServerReceived)、ss(ServerSent)和 cr(ClientReceived),它们分别标记了请求的发送、接收、处理完成和服务响应接收的时间,有助于分析服务间的延迟。
了解了这些基本概念后,我们可以通过以下步骤在微服务中集成 SpringCloud Sleuth 和 Zipkin:
1. **添加依赖**:在每个需要追踪的服务的 `pom.xml` 文件中,引入 `spring-cloud-starter-sleuth` 依赖。
2. **配置日志级别**:为了获取更详细的追踪日志,可以将 OpenFeign 的日志级别设置为 `DEBUG`。
3. **配置 Zipkin**:在项目中配置 Zipkin 服务器的地址,以便 Sleuth 可以将收集到的追踪数据发送到 Zipkin 进行存储和可视化展示。
4. **启动 Zipkin**:运行 Zipkin 服务器,用户可以通过浏览器访问 Zipkin UI 来查看服务间的调用链路图,从而快速定位问题。
5. **测试与监控**:通过发起实际的业务请求,观察 Zipkin UI 中生成的追踪图,分析不同服务间的调用关系和时间消耗,以优化服务性能。
SpringCloud Sleuth 和 Zipkin 的结合使用,为分布式系统提供了强大的服务追踪能力,帮助开发者在复杂的微服务环境中,有效地定位问题,提高系统的可维护性和稳定性。在实际开发中,结合日志和监控工具,可以进一步提升问题排查效率。
SpringCloudSleuth+zipkin实现服务追踪实现服务追踪
服务追踪
Spring Cloud Sleuth实现了一种分布式的服务链路跟踪解决方案,通过使用Sleuth可以让我们快速定位某个服务的问题。
官方文档地址
一些概念:
1.Span,Span是基本的工作单元。Span包括一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-value 注解
(tags),span处理者的ID(通常为IP)。
最开始的初始Span称为根span,此span中span id和 trace id值相同。
2.Trance,包含一系列的span,它们组成了一个树型结构
3.Annotation,用于及时记录存在的事件。常用的Annotation如下:
cs - Client Sent:客户端发送一个请求,表示span的开始
sr - Server Received:服务端接收请求并开始处理它。(sr-cs)等于网络的延迟
ss - Server Sent:服务端处理请求完成,开始返回结束给服务端。(sr-ss)表示服务端处理请求的时间
cr - Client Received:客户端完成接受返回结果,此时span结束。(cr-cs)表示客户端接收服务端数据的时间
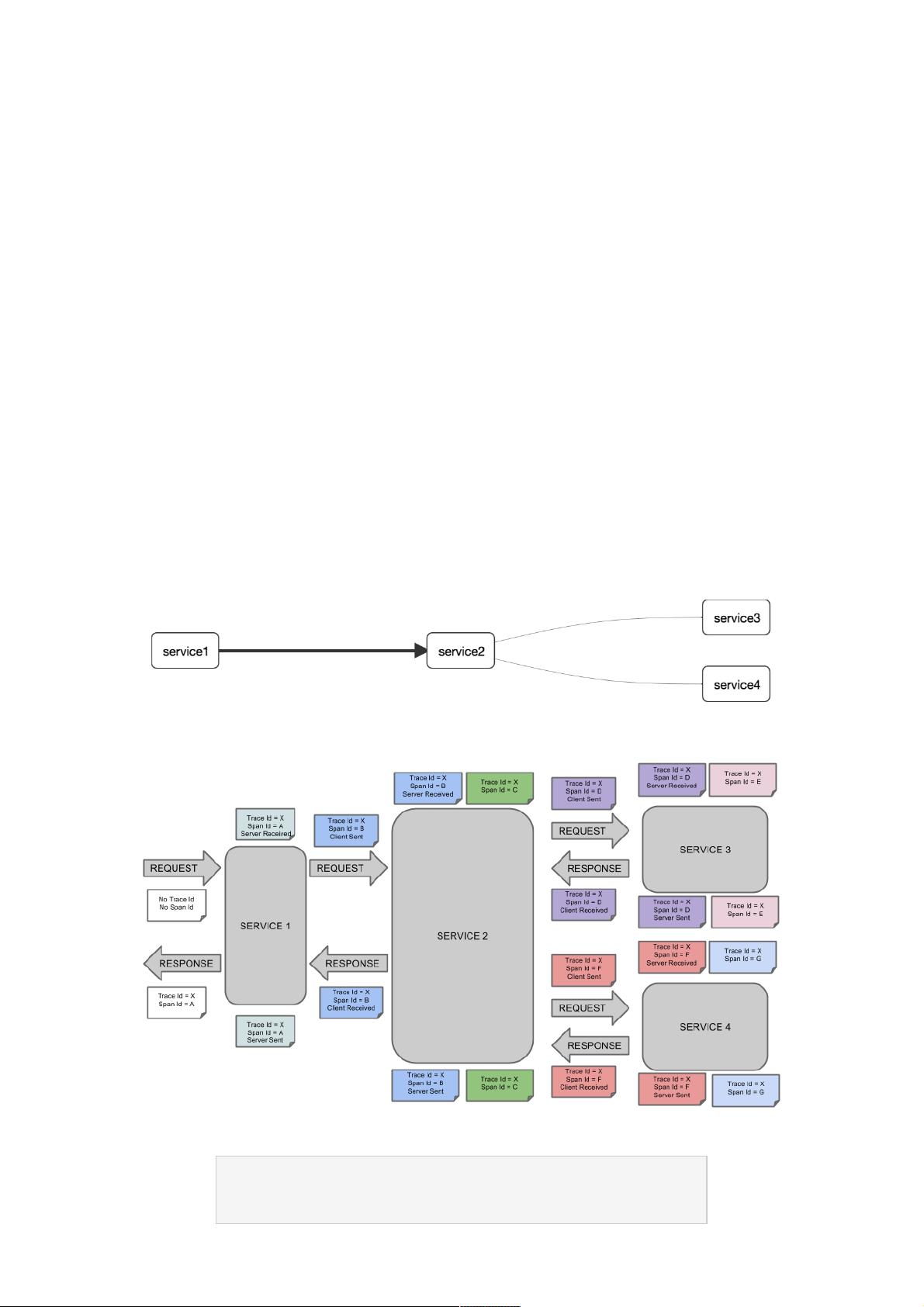
如果一个服务的调用关系如下:
那么此时将Span和Trace在一个系统中使用Zipkin注解的过程图形化如下:
每个颜色的表明一个span(总计7个spans,从A到G),每个span有类似的信息
Trace Id = X
Span Id = D
Client Sent
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-27 上传
2022-08-04 上传
2021-01-27 上传
2021-01-27 上传
点击了解资源详情
点击了解资源详情

weixin_38717896
- 粉丝: 4
- 资源: 885
 我的内容管理
展开
我的内容管理
展开







最新资源
- C/C++语言贪吃蛇小游戏
- BeInformed_Backend:与covid-19相关新闻的网站
- python实例-11 根据IP地址查对应的地理信息.zip源码python项目实例源码打包下载
- 【Java毕业设计】【厦门大学毕业设计】蚁群算法实现vrp问题java版本.zip
- shippo:ねこのしっぽ∧_∧
- Graficacion-de-vientos-usando-NCL:NCL库用于从http中提取的grib2文件中提取数据的项目
- 洞洞板简易制作电压、电容表(原理图、程序及算法讲解)-电路方案
- Rainydays
- push-bot:PubSubHubbub 到 XMPP 网关
- XPL compiler:XPL到C转换器-开源
- 【Java毕业设计】java web 毕业设计.zip
- Fruitopia
- iaagofelipe
- 毕业设计论文-源码-ASP人事处网站的完善(设计源码.zip
- TwoLevelExpandableRecyclerView:用于创建两级可扩展回收站视图的库
- 新唐M451 PWM 控制电机弦波(源码)-电路方案
