BloomFilter在大数据中的应用与实现
需积分: 0 164 浏览量
更新于2024-08-05
收藏 801KB PDF 举报
"该文档是关于大数据存储系统与管理的课程报告,主要探讨了Bloom Filter数据结构,包括其基本描述、BitSet结构与哈希函数的使用,以及多维数据处理的设计与实现。报告中还提到了MultiSimpleHash和MultiBloomFilter类的实现,以及False Positive现象和测试结果。"
在大数据处理中,有效的数据存储和检索是关键。Bloom Filter是一种用于高效空间存储的随机数据结构,特别适用于大数据场景。它由一个大型位数组和多个哈希函数组成,用于判断元素是否可能存在某一集合中,而不会占用过多的存储空间。在Bloom Filter中,初始位数组的所有位都设为false。当新元素被添加时,通过k个不同的哈希函数计算出的k个位被设置为1,形成一个均匀的分布。
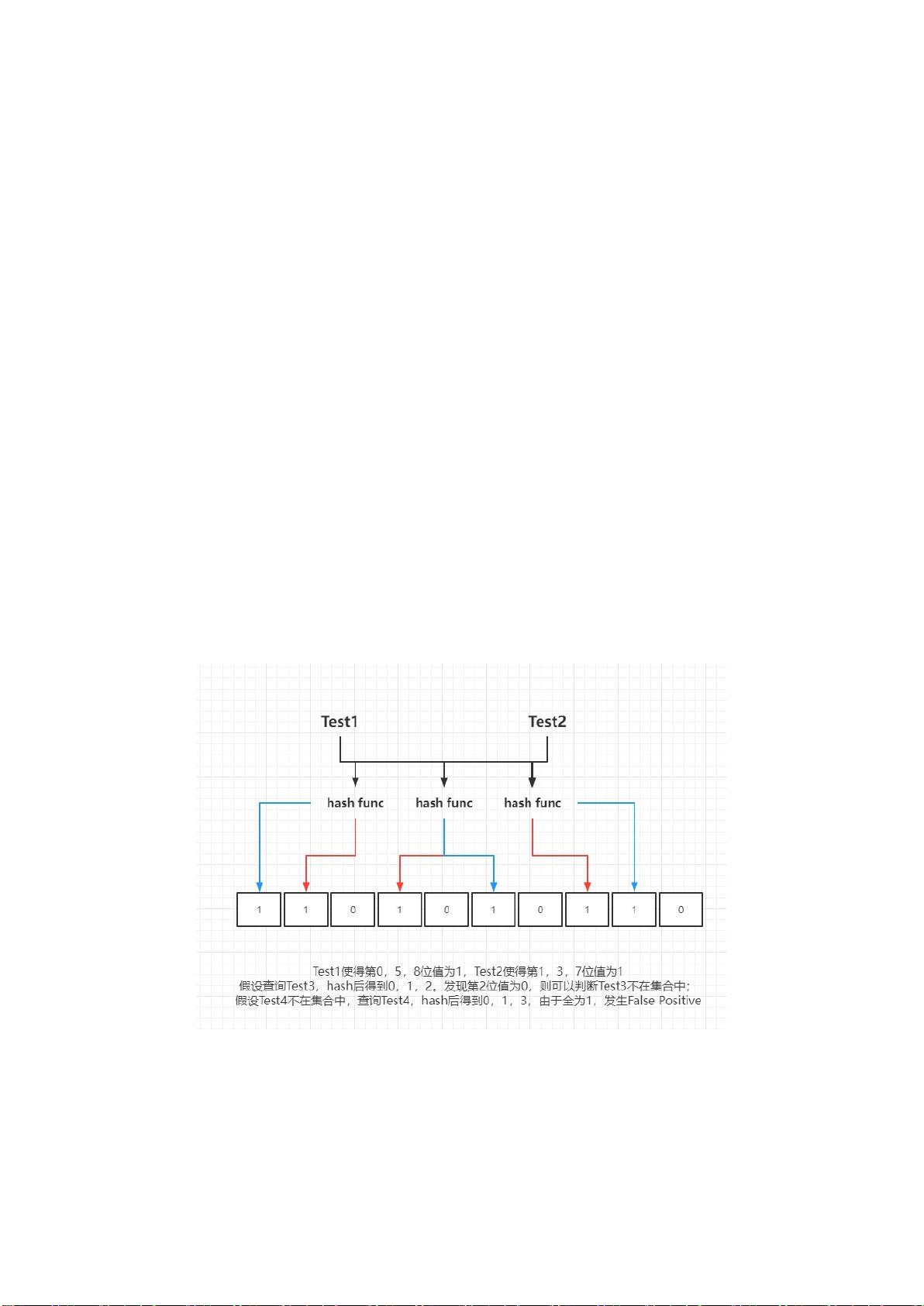
在基本描述中,Bloom Filter的判断机制是:如果待查元素经过k个哈希函数后,对应位数组的k个位置都是1,那么元素可能存在于集合中;如果有任何一位是0,那么元素肯定不在集合中。这种机制可能导致False Positive,即误判为元素存在的概率,但绝不会产生False Negative(误判为元素不存在)。
Bloom Filter的BitSet结构可以使用一维或二维数组来实现。对于多维数据,每个维度可以对应一个BitSet,使用多组不同的哈希函数对每一维进行处理。每组内包含若干个不同的哈希函数,确保处理的多样性,将处理结果映射到相应的BitSet。这种设计提高了Bloom Filter处理复杂数据结构的能力。
在设计与实现部分,报告提到了两个类:MultiSimpleHash和MultiBloomFilter。MultiSimpleHash类专注于初始化哈希函数,可能包含多个哈希函数实例,以便对多维数据进行处理。而MultiBloomFilter类则可能是实现Bloom Filter的容器,它整合了多个哈希函数和BitSet结构,以适应多维数据的存储和查询需求。
此外,报告中还涉及False Positive现象,这是Bloom Filter的一个固有特性,即在某些情况下,可能会错误地判断一个未添加到集合中的元素为已存在。False Positive的发生概率与位数组的大小、哈希函数的数量以及添加的元素数量有关,可以通过优化这些参数来降低其发生率。
最后,测试结果部分可能展示了不同参数配置下Bloom Filter的性能,包括False Positive的频率、存储效率等关键指标。通过这样的测试,可以评估和调优Bloom Filter在实际应用中的表现。
这份报告深入探讨了Bloom Filter在大数据存储系统中的应用,特别是针对多维数据的处理策略,对理解大数据环境下高效存储与检索机制具有重要意义。
1
1 Bloom Filter 结构
1.1 基本描述
Bloom Filter 是一种空间效率很高的随机数据结构,它利用位数组很简洁地
表示一个集合,并能判断一个元素是否属于这个集合。其核心实现是一个超大的
位数组和几个哈希函数。
默认情况下,初始化比特数组 BitSet 时,集合中的所有位最初都为值 false 。
然后需要引入 k 个不同的哈希函数,新增元素通过这 k 个哈希函数处理之后,把
BitSet 中命中映射的 k 个比特位设置为 1,产生一个均匀的随机分布。
这个时候如果需要判断一个元素是否存在于 Bloom Filter 中,只需要通过 k
个散列函数处理得到比特数组的 k 个下标,然后判断比特数组对应的下标所在比
特是否为 1。如果这 k 个下标所在比特中至少存在一个 0,那么这个需要判断的
元素必定不在 Bloom Filter 代表的集合中;如果这 k 个下标所在比特全部都为 1,
那么这个需要判断的元素可能存在于布隆过滤器代表的集合中或者出现失误定
位(False Positive)。具体过程如图 1 所示;
图 1 Bloom Filter 原理
1.2 BitSet 结构与 hash 函数
对于简单的 Bloom Filter,其 BitSet 可以使用一维数组实现。为了能够满足
剩余10页未读,继续阅读
2022-08-03 上传
2024-11-10 上传
2022-04-05 上传
2021-10-15 上传
2019-04-30 上传
2021-07-18 上传

赵伊辰
- 粉丝: 70
- 资源: 313
 我的内容管理
展开
我的内容管理
展开







最新资源
- 7290d51source,c语言吃豆人源码,c语言项目
- async-lock:锁定Node.js的异步代码
- 圆圈
- xpnsqt-开源
- CSES_Problem_Set
- Crizx Stream Notifier-crx插件
- bem-detach-test
- Cinema-Room-Manager:Java项目
- 2按键加减操作_单片机C语言实例(纯C语言源代码).zip
- GREEDSNAKE,c语言库源码下载,c语言项目
- 罗德与施瓦茨 CMU200 K53 选件:罗德与施瓦茨 CMU200 K53 选件 MATLAB 仪器驱动程序-matlab开发
- Goliath:Goliath是具有用户帐户,身份验证和加密功能的ASP.NET Core 5(基于MVC)密码和秘密管理器
- 养牛365源码前端+后端
- passphrase_dice_roller:chrome扩展程序,可创建一个随机的五个单词的密码短语
- 一个简单的蓝牙应用
- 百度Android工程师面试题.zip
