集成学习算法在推荐系统重排序中的应用
122 浏览量
更新于2024-08-28
收藏 532KB PDF 举报
"集成学习算法(EnsembleMethod)在个性化推荐系统的重排序阶段扮演着重要角色,通过结合多个机器学习模型提升推荐准确性。"
集成学习算法(EnsembleMethod)是机器学习领域的一种策略,它利用多个学习算法的结果来创建一个更强大的预测模型。这种方法能够有效地减少过拟合,提高模型的稳定性和准确性。在个性化推荐系统中,尤其是重排序阶段,集成学习被广泛采用以优化用户体验。
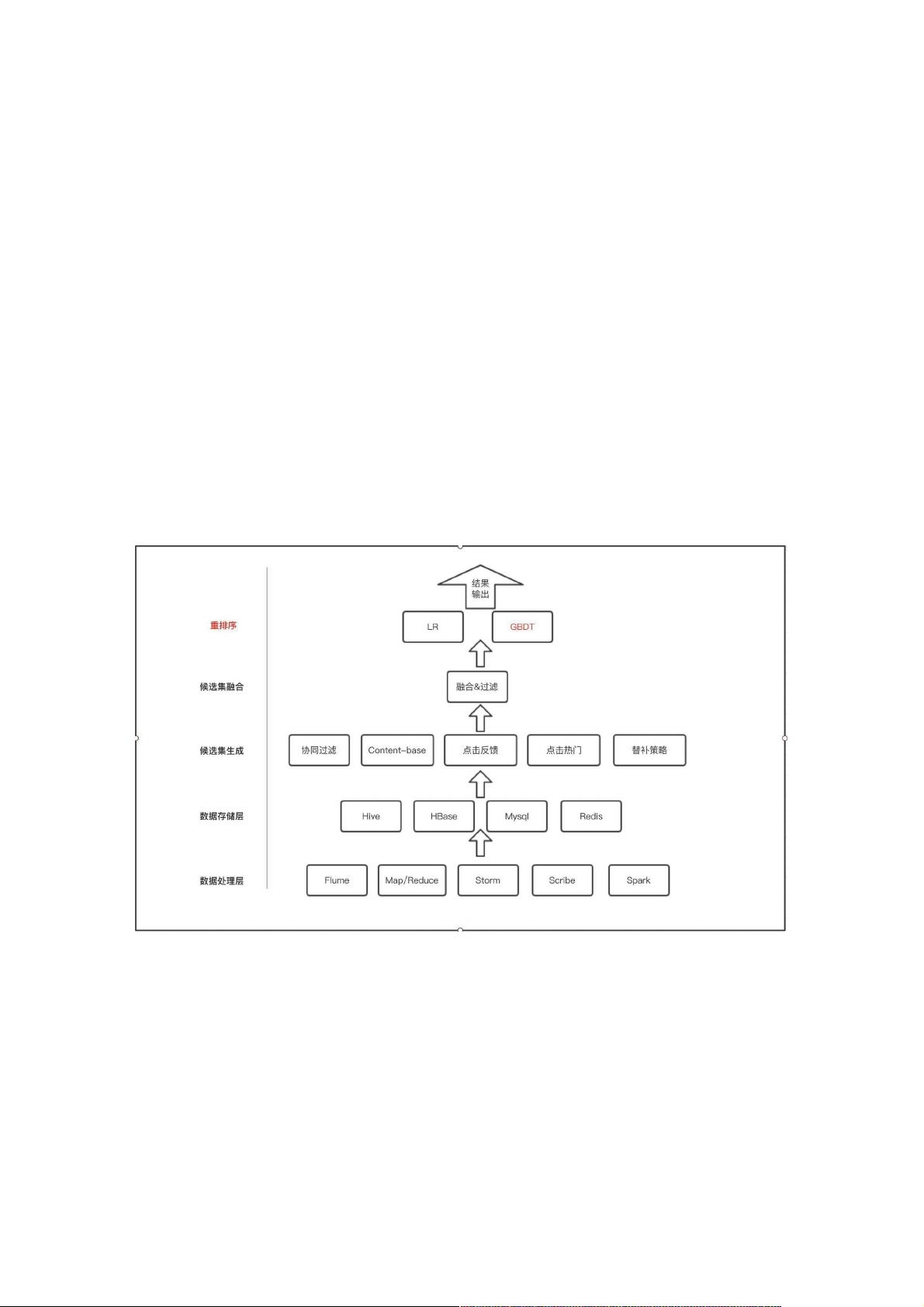
推荐系统通常分为五个层次:数据处理层、数据存储层、生成候选集、融合候选集和重排序。在数据处理层,系统会清除噪声数据并将有用信息存入数据存储层,这里可能会使用MySQL、HBase或Hive等不同数据库来适应不同的数据规模和需求。随着数据量的增长,像HBase这样的分布式数据库和Hive用于离线分析的工具成为更好的选择。
在重排序阶段,集成学习算法起着关键作用。例如,逻辑回归(LR)和梯度提升决策树(GBDT)等机器学习模型被用来对经过融合的候选集进行重新排序,以提供最符合用户偏好的推荐。集成学习中的两种主要方法是基于Bagging和Boosting。
基于Bagging的算法,如随机森林,其核心思想是通过对原始训练集进行有放回的抽样生成多个子集,用每个子集训练独立的模型,然后对所有模型的预测结果进行平均或投票,以获得最终的预测。随机森林就是这一方法的典型应用,它通过构建多棵决策树并综合其预测来增强整体的分类或回归性能。
另一方面,基于Boosting的算法,如Adaboost、GBDT和XGBoost,它们通过迭代方式逐步调整训练数据的权重,使得每次迭代都能聚焦于之前模型预测错误的数据。GBDT(Gradient Boosting Decision Tree)是一种常用的Boosting方法,它通过最小化残差来逐步构建决策树,每一棵树都试图修正前一棵树的错误。
集成学习的优势在于能够结合多种模型的优点,减少单一模型可能存在的偏差,提高整体预测的准确性和鲁棒性。然而,其缺点是训练过程可能较为复杂,计算资源需求较高。在实际应用中,根据推荐系统的需求和资源限制,选择合适的集成学习策略至关重要,以达到最优的推荐效果。
集成学习算法(集成学习算法(EnsembleMethod)浅析)浅析
个性化推荐系统是达观数据在金融、电商、媒体、直播等行业的主要产品之一。在达观数据的个性化推荐系统架构中,可以简
单地分为5层架构,每层处理相应的数据输出给下一层使用,分别是:
数据处理层
作为推荐系统最低端的数据处理层,主要功能是首先将客户上传上来的一些无用的噪声数据进行清理过滤,将推荐系统所需要
用到的数据导入到数据存储层中;
数据存储层
对于item的数据一般存入在Mysql中,随着数据量越来越大的item的数据,相比Mysql的扩展性来说,HBase和Hive 是一个更
好的选择,Hive可以方便离线分析时操作。而对于实时模块,以及一些用进程同步相关的模块,实时性要求比较高的,redis
就可以派上用场了,作为缓存,生产者生产数据写入redis供消费者读取;
生成候选集
通过一系列的基础算法如协同过滤,content-base,点击反馈,热门等数据给每个用户生成个性化的候选集;
融合候选集
将各个算法生成的候选集的item按照一系列规则进行融合过滤。
重排序
将融合过滤后的item集合用一定的算法重新排序,将排序后的结果输出到用户,这边主要常用到机器学习相关模型和算法,如
LR和GBDT。
本文将着重浅析一下重排序用到的集成学习算法(Ensemble Method)。
集成学习概述
集成学习算法本身不算一种单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。可以说是集百家 之
所长,能在机器学习算法中拥有较高的准确率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。目前常见的集成
学习算法主要有2种:基于Bagging的算法和基于Boosting的算法,基于Bagging的代表算法有随机森林,而基于Boosting的代
表算法则有Adaboost、GBDT、XGBOOST等。
基于Bagging算法
Bagging算法(装袋法)是bootstrap aggregating的缩写,它主要对样本训练集合进行随机化抽样,通过反复的抽样训练新的模
型,最终在这些模型的基础上取平均。
基本思想
1.给定一个弱学习算法,和一个训练集;
2.单个弱学习算法准确率不高;
下载后可阅读完整内容,剩余4页未读,立即下载
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传
2024-12-02 上传

weixin_38735570
- 粉丝: 5
- 资源: 934
 我的内容管理
展开
我的内容管理
展开







