HPE Vertica与Spark集成:大数据批量与流式分析
需积分: 9 190 浏览量
更新于2024-07-17
收藏 4.23MB PDF 举报
“HPE Vertica and Spark架构:Myles Collins在SPARK SUMMIT 2016上的分享,探讨了如何结合Apache Kafka、Spark和HPE Vertica进行批量与流式分析。”
在2016年的SPARK SUMMIT大会上,Myles Collins详细介绍了HPE Vertica和Spark的集成,以及如何利用Apache Kafka构建一个高效的数据处理架构。这个演讲主要关注了大数据分析领域中的三个关键组件:Apache Kafka、Spark和HPE Vertica,并阐述了它们在批量处理和实时流式分析中的协同工作。
HPE Vertica是一个高性能的分析型数据库,其特性包括:
1. 快速:通过优化能够提升性能500%或更多,适合处理大规模数据集。
2. 可扩展:能以高速度处理大型工作负载,适用于高并发环境。
3. 标准化:支持ANSI SQL和ACID事务,用户无需学习新语言或引入复杂性。
4. 低成本:相较于传统平台,拥有显著更低的运营成本。
在大数据分析场景中,Apache Kafka作为一个分布式消息系统,用于收集和传输实时数据,如应用程序日志、Web流量和设备数据。Spark则作为处理引擎,可以进行实时流处理和批处理任务,提供低延迟和高吞吐量的数据处理能力。
HPE Vertica在这个架构中扮演了数据分析和报告的角色,接收经过Spark处理后的数据,进行深度分析和存储。数据的生命周期通常如下:
1. 数据生成:来自各种源头(如OLTP/ODS系统、用户行为跟踪、操作指标)的数据进入系统。
2. 分布式消息系统:Apache Kafka接收并传递这些原始数据。
3. ETL(抽取、转换、加载)和流处理:Spark对原始数据进行清洗、转换,并处理实时流数据。
4. 存储:处理后的数据被写入HPE Vertica,以供进一步分析或报告。
HPE Vertica的核心技术包括列式存储、压缩、MPP(大规模并行处理)扩展和分布式查询等。列式存储只读取必要的数据,降低了昂贵的I/O操作,提高了整体性能;MPP架构允许在无名称节点或单点故障的集群上实现高可扩展性;分布式查询机制使得任何节点都能发起查询,并利用其他节点进行计算,增强了系统的容错能力。
通过将Apache Kafka的实时数据处理能力、Spark的批处理与流处理功能与HPE Vertica的强大分析能力相结合,企业能够构建一个既能处理批量历史数据,又能实时响应新数据流的综合分析平台,满足现代大数据环境下的多元化需求。这种架构尤其适合对实时性要求高的行业,例如石油天然气行业的客户分析,能够快速响应市场变化,做出明智的业务决策。
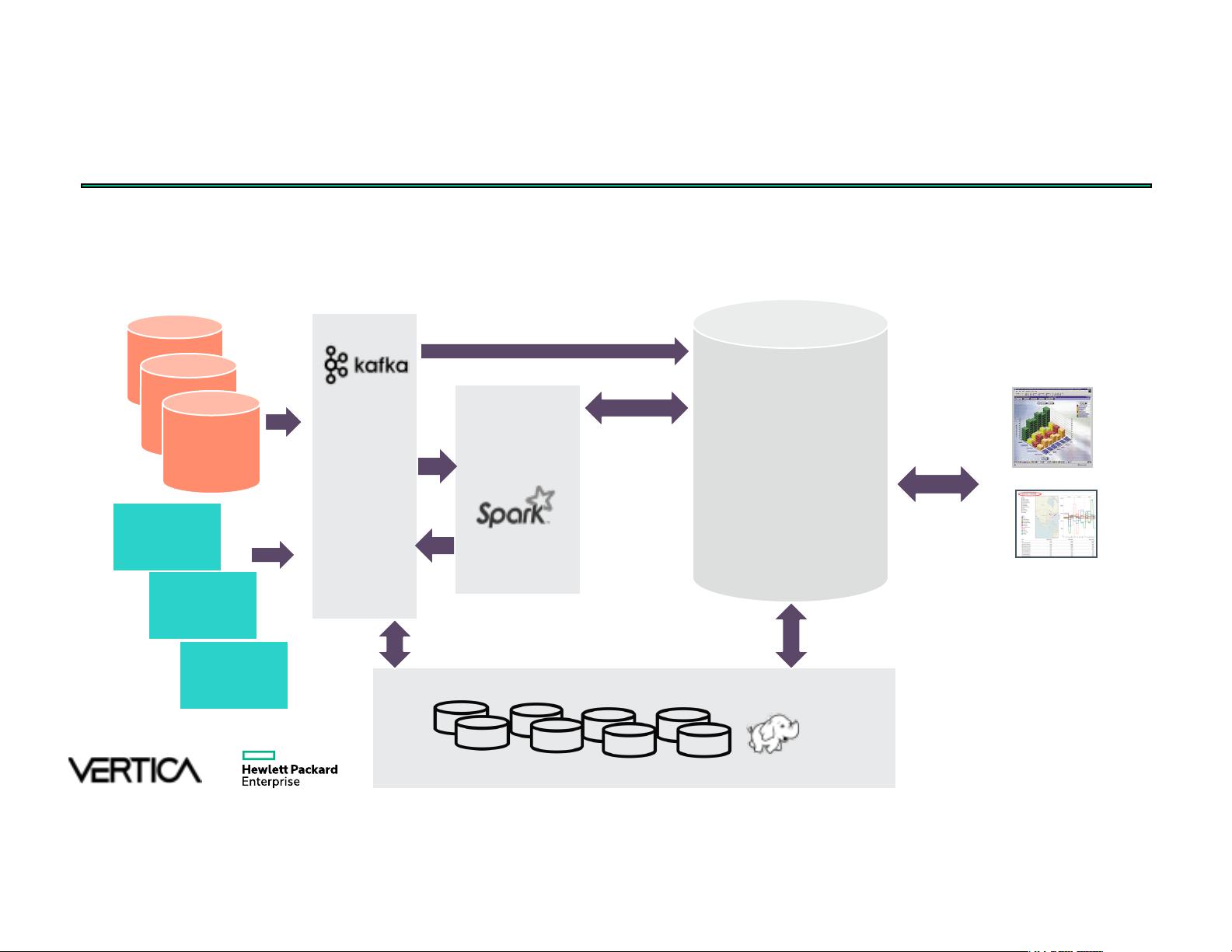
Apache Kafka + Spark + HPE Vertica for both Batch and Streaming Analytics
HPE Vertica
Analytics Platform
Analytics / Reporting
Data
Generation
OLTP/ODS
Logs
(Apps, Web,
Devices)
User
tracking
Operational
Metrics
Distributed
Messaging
System
ETL
Stream
processing
SQL on Hadoop
Hive
ORC
Parquet
Raw Data Topics
JSON, AVRO
Processed
Data Topics
剩余14页未读,继续阅读
2024-10-25 上传
2024-10-25 上传
2024-10-25 上传
2024-10-25 上传

weixin_38743602
- 粉丝: 395
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
