Python爬虫实战:模拟浏览器请求解决网站校验问题
需积分: 9 21 浏览量
更新于2024-07-06
收藏 2.38MB DOCX 举报
"无敌python爬虫(四)"
在这一部分的学习中,我们将深入探讨Python爬虫的基础,特别是使用requests库来发送HTTP请求。requests是一个非常流行的Python库,用于简化HTTP请求过程。在本文中,我们将学习如何安装requests,以及如何使用它来获取网页内容并处理可能出现的问题。
首先,让我们讨论如何安装requests。在Python环境中,你可以通过以下两种方法来安装这个库:
1. 使用命令行工具pip。在终端或命令提示符中输入`pip install requests`,然后按回车,pip会自动下载并安装requests库。
2. 在PyCharm等集成开发环境(IDE)中,你可以在设置或首选项里管理Python解释器的库。找到添加新库的选项,输入requests,然后应用更改。
接下来,我们看一个基础的使用案例,即通过requests库获取搜狗搜索引擎的结果。以下代码展示了如何向搜狗发送GET请求,获取关于“徐志胜”的搜索结果:
```python
import requests
url = 'https://www.sogou.com/web?query=徐志胜'
response = requests.get(url)
print(response)
print(response.text)
```
当运行这段代码时,requests库会向指定的URL发送GET请求,然后返回一个Response对象。Response对象包含了服务器的响应,包括状态码、头部信息和实际的响应内容。`response.text`属性则可以获取到响应的文本内容,即网页的HTML源代码。
然而,有些网站会检测到非浏览器发起的请求,可能会返回不同的内容或拒绝服务。在搜狗的例子中,它可能检测到我们的请求没有包含正确的User-Agent头部,这通常标识了用户使用的浏览器类型。为了模拟浏览器行为,我们需要在请求头中添加User-Agent字段。这样,服务器就更可能将我们视为正常用户:
```python
import requests
url = 'https://www.sogou.com/web?query=徐志胜'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edge/98.0.1108.62"
}
response = requests.get(url, headers=headers)
print(response)
print(response.text)
```
在这个改进的版本中,我们添加了一个标准的User-Agent字符串,模拟的是Microsoft Edge浏览器的请求。这样,我们就可以成功地获取到与浏览器相同的内容。
总结一下,Python爬虫的关键步骤包括:
1. 导入requests库。
2. 定义目标URL。
3. 发送HTTP请求(通常是GET),并指定任何必要的请求头。
4. 接收并处理响应,例如打印响应内容或解析HTML。
在实际的爬虫项目中,你可能还需要处理其他问题,如登录验证、反爬虫策略、数据解析(例如使用BeautifulSoup或lxml库)以及错误处理。随着技能的提升,你还可以探索更高级的主题,如多线程、异步请求和分布式爬虫。
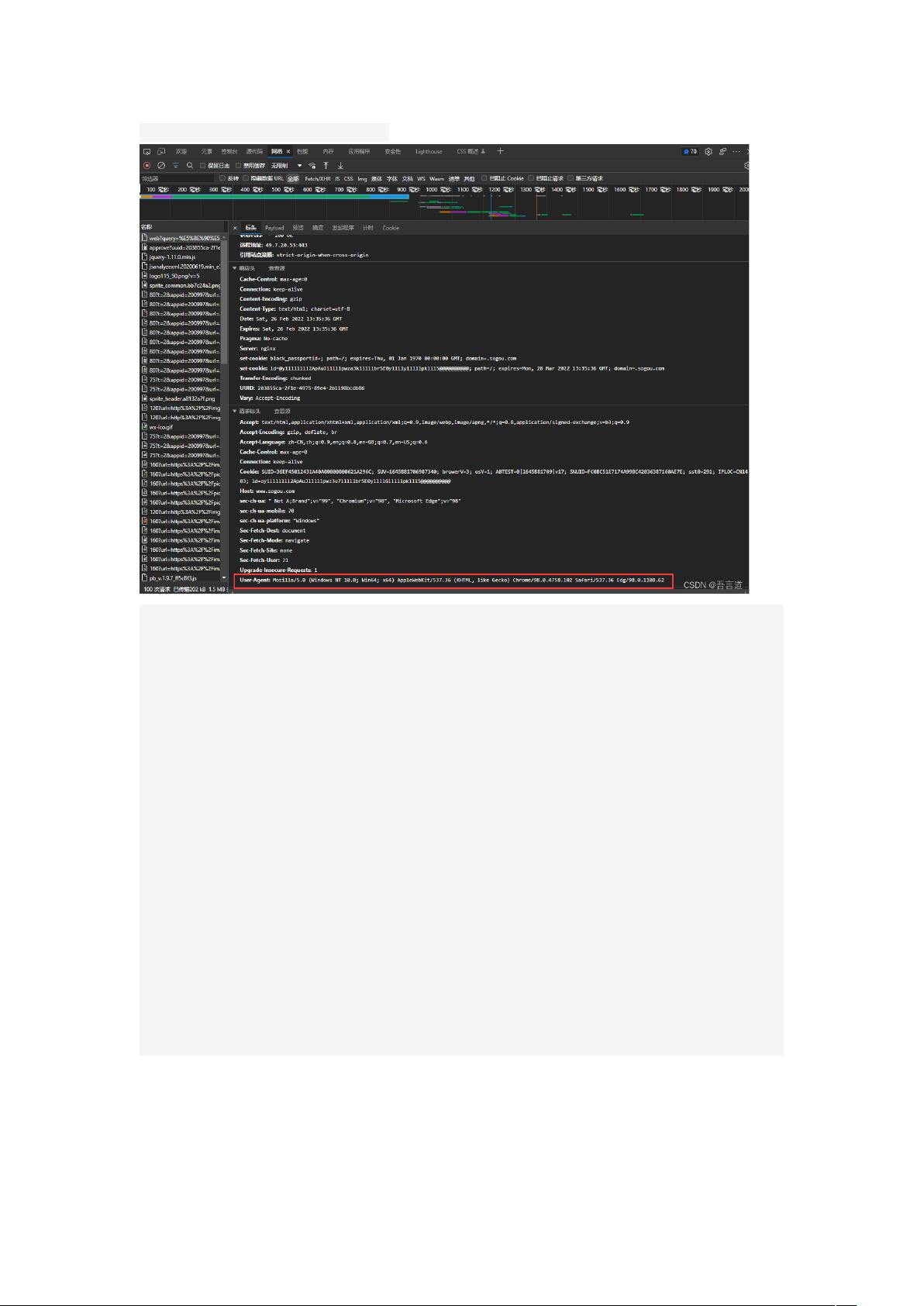
“ ” “ ”我们打开网页点击 检查 , 网络 。
在请求头中,有一个 User Agent,它是来描述当前的请求是通过那个设备发出的。我们把
它复制到 headers 中。
```python
import requests
url = 'https://www.sogou.com/web?query=徐志胜'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}
resp=requests.get(url,headers=headers)
print(resp)
print(resp.text)#拿到页面源代码
```
我们成功请求,并且拿到了源代码,在这里也是处理了一个小小的反 pa。
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-06-07 上传
2021-02-14 上传
2022-06-13 上传

yyysec
- 粉丝: 738
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
