Python实战:数据预处理与 FIFA_2018 球员数据分析
30 浏览量
更新于2024-08-29
收藏 674KB PDF 举报
在Python案例实战中,我们将探讨如何对 FIFA_2018_player.csv 数据集进行初步的数据分析和清理。首先,理解分析的目标是关键步骤,这将指导我们后续的操作流程。
1. **数据导入与初步探索**:
- 导入必要的库:`numpy`用于数值计算,`pandas`用于数据处理,`matplotlib.pyplot`用于数据可视化。这些库在数据分析过程中扮演了核心角色。
- 加载数据:使用 `pd.read_csv()` 函数加载CSV文件,存储在变量df中,以便后续操作。
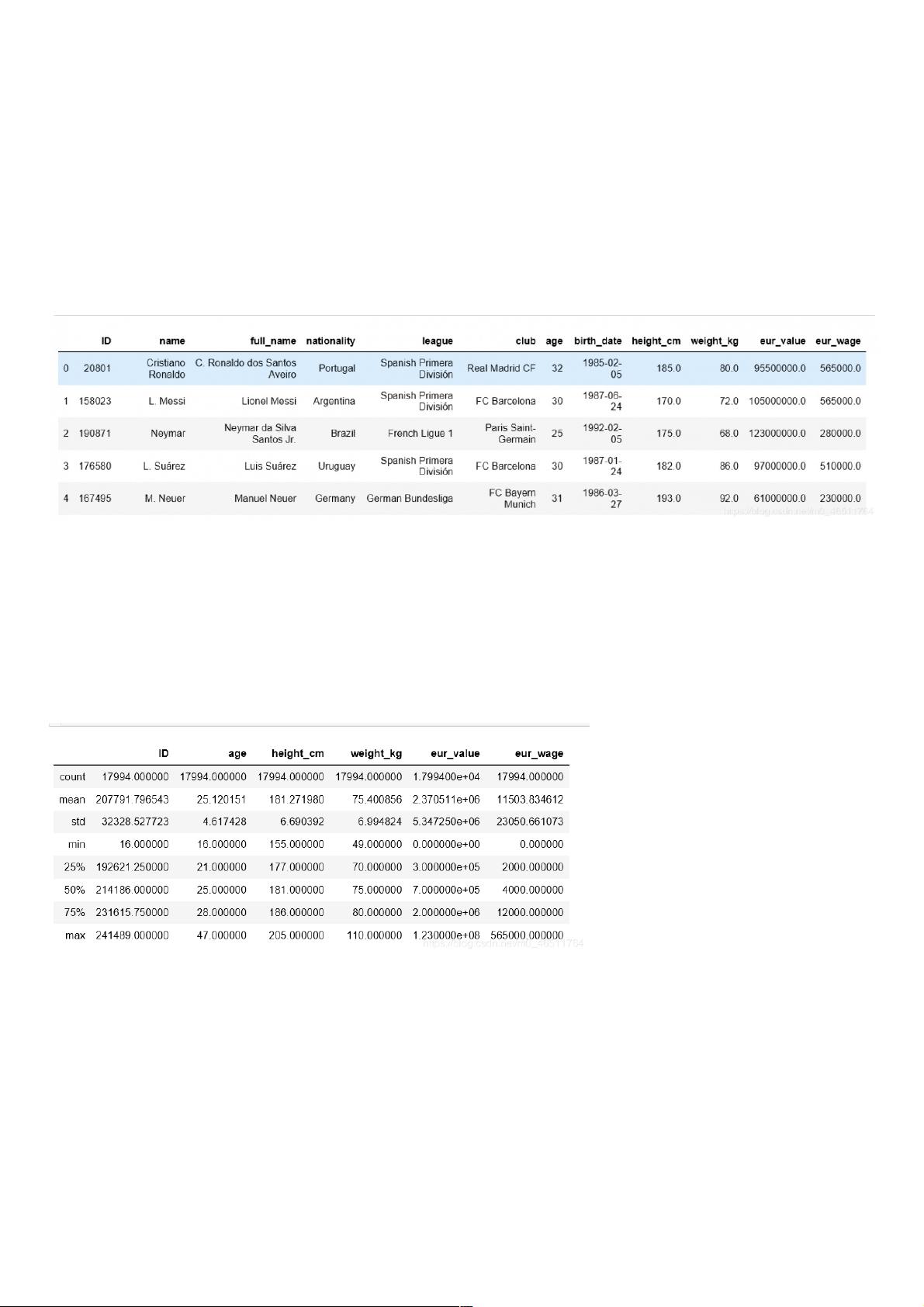
- 数据预览:通过`df.head()`快速查看数据前几行,了解数据的基本结构和格式,包括球员姓名(name)、全名(full_name)、国籍(nationality)等信息。
2. **数据清洗与质量检查**:
- 数据清洗是确保分析准确性的重要环节。首先,通过`df.describe()`获取数值型数据的统计摘要,如均值、最大值、最小值等,以识别潜在异常值或缺失值。
- 数据量检查:利用`df.count()`查看每列数据的数量,确认是否存在缺失值。
- 处理缺失值:在这个案例中,发现`league`和`club`字段有253个缺失值。尽管数量不多,但为了保持数据一致性,可以决定删除这些行。执行`df.drop()`函数,然后再次检查数据量是否一致。
3. **异常值检测与处理**:
- 发现一个异常现象,即有些球员的身价(eur_value)为0,而工资(eur_wage)却为1000,这可能是数据录入错误。处理方式有三种:一是逐一查找并修正;二是用平均值替换异常值;三是删除异常数据。由于数据集较大,本案例选择平均值替换法,即使用`df['eur_value'].replace(0, df['eur_value'].mean(), inplace=True)`来处理。
在整个过程中,数据分析的步骤从数据的导入、初步查看到数据清洗和异常值处理,都是为了确保数据的质量,从而能进行准确和有意义的分析。通过这个案例,学习者将掌握Python中的pandas库在实际项目中的应用,包括数据加载、数据预览、数据质量控制以及基本的数据清洗策略。
python案例实战之一案例实战之一
分析思路:
1
、明确分析目标;
2
、导入库、导入数据;
3
、简单查看下数据行列、整体情况;
4
、数据清洗;
5
、确定维度和指标;
6
、分析并作图
1、查看整体数据情况、查看整体数据情况
1.1引入使用的库引入使用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
1.2加载数据文件加载数据文件
df = pd.read_csv('./FIFA_2018_player.csv')
1.3简单查看数据整体情况简单查看数据整体情况
df.head()
数据表头说明:
ID:编号
name:球员姓名
full_name:球员全名
nationality:国籍
league:联赛
club:所属俱乐部
age:年龄
birth_date:出生日期
height_cm:身高
weight_kg:体重
eur_value:身价
eur_wage:周薪
df.describe()
2、开始清理数据、开始清理数据
数据清理-所有需要分析的数据都需要看下。
对于数值型,可以看下describe方法输出的信息,重点关注最大值,最小值,平均值,行数等。
2.1、查看整体数据量、查看整体数据量
f.count()
下载后可阅读完整内容,剩余4页未读,立即下载
2020-12-31 上传
2023-07-15 上传
2023-04-29 上传
2023-06-01 上传
2023-08-16 上传
2023-09-17 上传
2023-10-10 上传

weixin_38670707
- 粉丝: 9
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
