ApacheFlink命脉:批是流的特例
63 浏览量
更新于2024-08-27
收藏 655KB PDF 举报
ApacheFlink漫谈系列-概述
一、ApacheFlink的核心理念
ApacheFlink是一个高度优化的分布式流处理框架,它的核心理念在于“批是流的特例”这一思想。这意味着在设计之初,Flink就考虑到了流处理的普遍性和批处理的特殊性,将流处理作为基础,批处理作为流处理的一种特殊情况来处理。这种设计理念使得Flink在实时计算中能够提供极低的延迟,适应快速变化的数据流。
二、“唯快不破”的流式计算
在实时计算领域,速度至关重要,ApacheFlink以其独特的Native Streaming(纯流式)计算引擎,实现了低延时处理。相较于Apache Spark的MicroBatching(微批式)模式,Flink能够做到微秒级的延迟,而Spark的最低延迟通常在0.5到2秒之间。Flink的高速处理能力源于其流式处理的内核,数据一到达就能立即触发计算,无需等待批次积累,从而在架构上确保了速度优势。
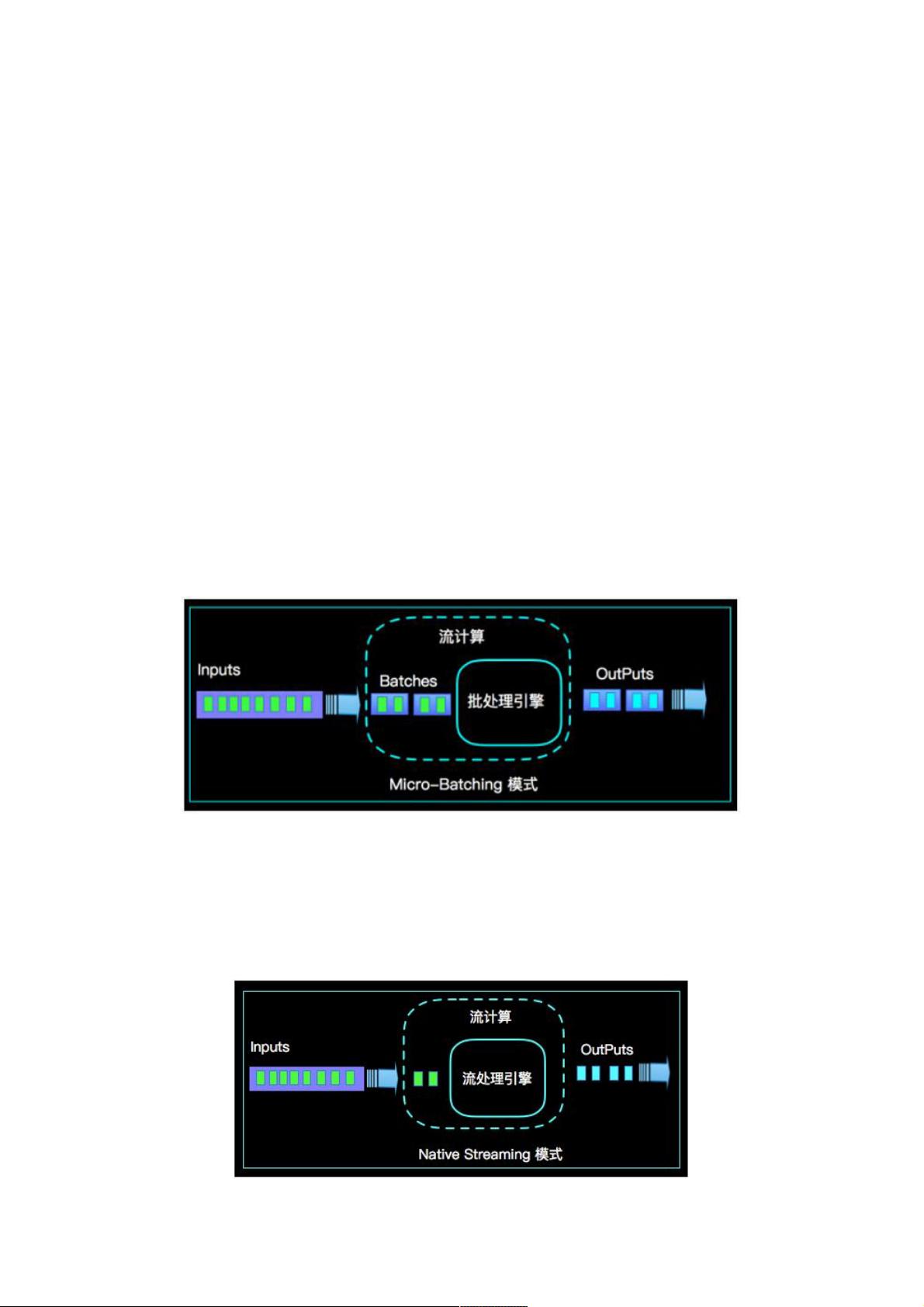
三、MicroBatching模式解析
MicroBatching模式基于“流是批的特例”的理论,将连续的数据流分割成小批次进行处理,以此实现接近实时的效果。然而,由于存在数据积累和批处理的步骤,这不可避免地引入了额外的延迟。如下图所示,数据必须等待形成一定大小的批次才能开始计算,这限制了其在极低延迟需求场景下的应用。
四、流计算的两种模式对比
流计算的两种模式——纯流式和微批式,分别反映了不同的计算哲学。Flink的纯流式强调连续无间断的处理,适用于需要快速响应的实时场景,如实时监控、异常检测等。而Spark的微批式则兼顾了批量处理的效率和实时处理的需求,适用于大部分实时分析但对延迟容忍度较高的情况。
五、Apache Flink的优势与挑战
Apache Flink的低延迟和高吞吐量使其在实时计算中脱颖而出,特别是在事件驱动和实时数据分析的应用中表现出色。然而,这也带来了一些挑战,例如复杂状态管理、容错机制的优化以及与现有批处理系统的集成。尽管如此,Flink通过不断迭代和改进,如State Backend的优化、Checkpoints的实现,已经逐步完善了这些功能,提升了整体的稳定性和可靠性。
总结,Apache Flink以其独特的设计理念和高性能的流处理能力,正在实时计算领域扮演越来越重要的角色。随着大数据技术的不断发展,理解并掌握Flink的内在原理和技术优势,对于开发者和数据工程师来说,显得尤为重要。
ApacheFlink漫谈系列漫谈系列-概述概述
一、Apache Flink 的命脉
"命脉" 即生命与血脉,常喻极为重要的事物。系列的首篇,首篇的首段不聊Apache Flink的历史,不聊Apache Flink的架构,
不聊Apache Flink的功能特性,我们用一句话聊聊什么是 Apache Flink 的命脉?我的答案是:Apache Flink 是以"批是流的特
例"的认知进行系统设计的。
二、唯快不破
我们经常听说 "天下武功,唯快不破",大概意思是说 "任何一种武功的招数都是有拆招的,唯有速度快,快到对手根本来不及
反应,你就将对手KO了,对手没有机会拆招,所以唯快不破"。 那么这与Apache Flink有什么关系呢?Apache Flink是Native
Streaming(纯流式)计算引擎,在实时计算场景最关心的就是"快",也就是 "低延时"。
就目前最热的两种流计算引擎Apache Spark和Apache Flink而言,谁最终会成为No1呢?单从 "低延时" 的角度看,Spark是
Micro Batching(微批式)模式,最低延迟Spark能达到0.5~2秒左右,Flink是Native Streaming(纯流式)模式,最低延时能达到微
秒。很显然是相对较晚出道的 Apache Flink 后来者居上。 那么为什么Apache Flink能做到如此之 "快"呢?根本原因是Apache
Flink 设计之初就认为 "批是流的特例",整个系统是Native Streaming设计,每来一条数据都能够触发计算。相对于需要靠时间
来积攒数据Micro Batching模式来说,在架构上就已经占据了绝对优势。
那么为什么关于流计算会有两种计算模式呢?归其根本是因为对流计算的认知不同,是"流是批的特例" 和 "批是流的特例" 两种
不同认知产物。
1. Micro Batching 模式
Micro-Batching 计算模式认为 "流是批的特例", 流计算就是将连续不断的批进行持续计算,如果批足够小那么就有足够小的
延时,在一定程度上满足了99%的实时计算场景。那么那1%为啥做不到呢?这就是架构的魅力,在Micro-Batching模式的架构
实现上就有一个自然流数据流入系统进行攒批的过程,这在一定程度上就增加了延时。具体如下示意图:
很显然Micro-Batching模式有其天生的低延时瓶颈,但任何事物的存在都有两面性,在大数据计算的发展历史上,最初
Hadoop上的MapReduce就是优秀的批模式计算框架,Micro-Batching在设计和实现上可以借鉴很多成熟实践。
2. Native Streaming 模式
Native Streaming 计算模式认为 ""批是流的特例",这个认知更贴切流的概念,比如一些监控类的消息流,数据库操作的
binlog,实时的支付交易信息等等自然流数据都是一条,一条的流入。Native Streaming 计算模式每条数据的到来都进行计
算,这种计算模式显得更自然,并且延时性能达到更低。具体如下示意图:
很明显Native Streaming模式占据了流计算领域 "低延时" 的核心竞争力,当然Native Streaming模式的实现框架是一个历史先
河,第一个实现Native Streaming模式的流计算框架是第一个吃螃蟹的人,需要面临更多的挑战,后续章节我们会慢慢介绍。
当然Native Streaming模式的框架实现上面很容易实现Micro-Batching和Batching模式模式的计算,Apache Flink就是Native
下载后可阅读完整内容,剩余8页未读,立即下载
2008-08-22 上传
2009-01-07 上传
110 浏览量
2022-11-01 上传
2022-11-14 上传
2023-07-25 上传
229 浏览量
160 浏览量

weixin_38516491
- 粉丝: 6
- 资源: 950
 我的内容管理
展开
我的内容管理
展开







最新资源
- LINUX-1.2.13内核网络栈实现源代码分析
- EXT 中文手册.pdf
- see mips run 2nd edition(CN)
- 制造业常用英语词汇.pdf
- Spoon_User_Guide_3_0
- Apress - The.Definitive.Guide.to.SOA.BEA.AquaLogic.Service.Bus.May.2007.pdf
- 管理信息系统分析与设计—图书馆管理信息系统
- oracle体系结构
- 计算机等级考试(pc技术)
- after effect 插件应用指南(英文).pdf
- linux 网络编程笔记
- 测试知识文件(软件测试背景)
- IBM Ratioal技术白皮书_软件测试自动化技术
- spring struts hibernate 自己整理的 很不错 收集了许多题型
- sql 笔试题包含了sql的基础知识 有好几种题型 有答案
- sql 笔试题包含了sql的基础知识 有好几种题型 有答案
