Lucene全文检索技术解析及其应用
需积分: 3 159 浏览量
更新于2024-07-23
收藏 1.08MB DOC 举报
“Lucene课件全文检索”
Lucene是一个开源的全文检索库,由Apache软件基金会开发,广泛应用于各种全文检索需求。它提供了一个高级的、灵活的、可扩展的索引和搜索机制,使开发者能够轻松地在应用程序中实现全文检索功能。
1. 全文检索的基本概念
- **快速、准确地查找信息**:全文检索系统旨在从海量数据中迅速定位到用户所需的具体信息。
- **文本信息搜索**:主要处理的是文本数据,而非图像、音频或视频等多媒体内容。
- **关键词匹配**:搜索基于关键词,而不考虑语义理解。比如搜索“2012年的春晚有赵本山吗”,系统会查找包含“2012年”、“春晚”和“赵本山”的文档。
- **不区分英文大小写**:在搜索时,英文关键词不区分大小写。
- **相关度排序**:返回的结果会按照与查询关键词的相关度进行排序。
2. 全文检索的应用场景
- **站内搜索**:如论坛的关键字搜索、电子商务网站的商品搜索、文件管理系统的文件查找等。
- **垂直搜索**:针对特定行业的搜索引擎,如购物、房产、招聘等,它们更专业、深入且聚焦。
3. 全文检索与数据库搜索的区别
- **数据库搜索**:通常使用SQL语句,如`SELECT * FROM 表名 WHERE 字段名 LIKE '%关键字%'`,它基于结构化数据,适合精确匹配和条件过滤。
- **全文检索**:强调文本内容的模糊匹配,能够处理更复杂的查询表达式,如短语、近义词、拼写纠错等,并提供相关性排序。
Lucene通过构建倒排索引实现高效检索。它将每个文档拆分成单词(分词),然后为每个单词创建一个索引,记录哪些文档包含了这个单词及其出现的位置。当用户输入查询时,Lucene会解析查询语句,生成查询向量,然后与索引进行匹配,从而找到最相关的文档。
此外,Lucene还支持多种增强功能,如停用词过滤、词干提取、同义词处理、评分算法等,以提高搜索质量和用户体验。在实际应用中,开发者可以结合其他工具,如Solr或Elasticsearch,构建分布式全文检索解决方案,以处理更大规模的数据和高并发的查询需求。
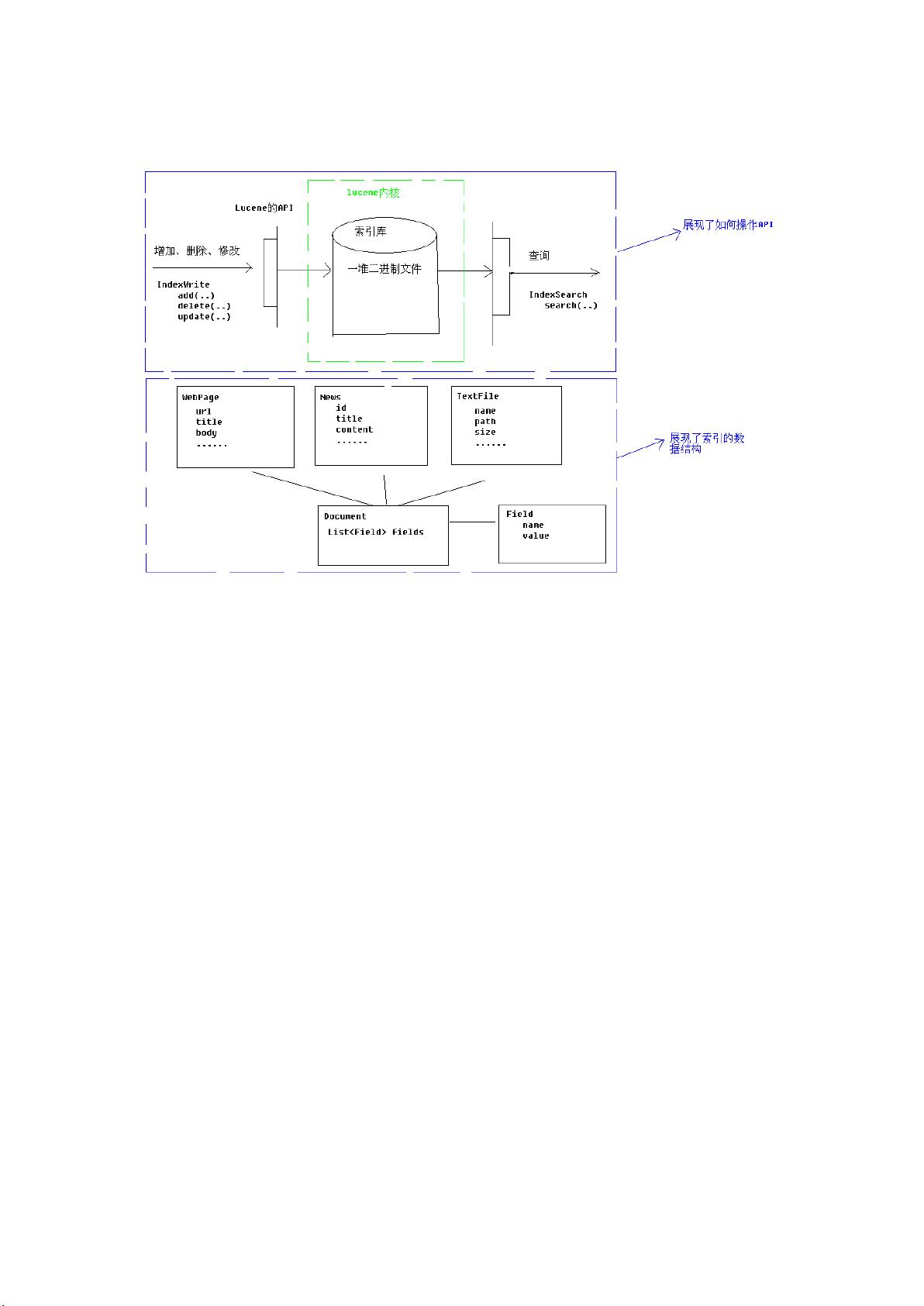
2.2 lucene 的大致结构框图
说明:
1) 在数据库中,数据库中的数据文件存储在磁盘上。索引库也是同样,
索引库中的索引数据也在磁盘上存在,我们用 Directory 这个类来
描述。
2) 我们可以通过 API 来实现对索引库的增、删、改、查的操作。
3) 在数据库中,各种数据形式都可以概括为一种:表。在索引库中,
各种数据形式也可以抽象出一种数据格式为 Document。
4) Document 的结构为:Document(List<Field>)
5) Field 里存放一个键值对。键值对都为字符串的形式。
6) 对索引库中索引的操作实际上也就是对 Document 的操作。
3. 第一个 lucene 程序
3.1 准备 lucene 的开发环境
搭建 lucene 的开发环境,要准备 lucene 的 jar 包,要加入的 jar 包至少有:
1) lucene-core-3.1.0.jar (核心包)
2) lucene-analyzers-3.1.0.jar (分词器)
3) lucene-highlighter-3.1.0.jar (高亮器)
4) lucene-memory-3.1.0.jar (高亮器)
剩余33页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-04-29 上传
点击了解资源详情
点击了解资源详情
2024-12-27 上传
2024-12-27 上传
2024-12-27 上传

毅个混蛋
- 粉丝: 63
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- angular-prism:在Angular应用程序中使用Prism语法荧光笔
- FriendList:该Web应用程序可以下载您的Facebook朋友列表,并允许您对它们进行排序
- 实用程序_1fdp:程序基础知识1
- 灰色按钮克星源码例程.zip易语言项目例子源码下载
- docker-traefik::mouse:使用Traefik代理Docker容器进行* .localhost开发
- lidlab:Lidstrom 实验室@华盛顿大学共享代码
- savagejsx:将svg转换为React成分的实用程序
- Leetcode-optimized-solution-in-java-with-clear-explanation
- A_CNS_API:HIMS CNS API代码
- laas:从数据驱动的角度出发,基于指令库的逻辑汇编和分发
- Media XW-开源
- Java资源 javaeasycms-v2.0.zip
- Lab7_WhoWroteIt
- 烟花newyearFireworks-master.zip
- JanChaMVC
- Maliwan-开源
