深入解析Hadoop源代码:分布式云计算基石
需积分: 10 7 浏览量
更新于2024-07-23
1
收藏 6.06MB PDF 举报
"Hadoop源代码分析完整版,涵盖了MapReduce项目的整体架构和依赖关系,以及Hadoop在分布式云计算中的核心组件。"
在深入探讨Hadoop源代码之前,我们需要理解Hadoop的基本概念。Hadoop是一个开源的分布式计算框架,最初由Apache软件基金会开发,其设计灵感来源于Google的五篇论文,包括Google Cluster、Chubby、GFS、BigTable和MapReduce。这些技术构成了Google强大的计算基础,而Hadoop则实现了类似的功能,但开放给公众使用。
Hadoop主要由两个核心组件构成:Hadoop Distributed File System (HDFS) 和 MapReduce。HDFS是一个分布式文件系统,类似于Google的GFS,提供了高容错性和高吞吐量的数据存储。MapReduce是一种编程模型,用于处理和生成大规模数据集,模仿了Google的MapReduce计算模型。
在Hadoop的源代码分析中,首先会遇到的是复杂的包依赖关系。例如,HDFS不仅提供了API供应用程序访问,还能够透明地处理本地文件系统、分布式文件系统甚至云存储服务,如Amazon S3。这种设计导致了不同功能间的相互引用,形成了复杂的依赖结构。
在图中,蓝色部分是Hadoop的关键组件,是我们关注的重点。这部分通常包括:
1. `hadoop-common`: 包含了Hadoop的基本工具和公用模块,如配置管理、网络通信等。
2. `hadoop-hdfs`: 实现了HDFS,负责数据的存储和分布。
3. `hadoop-mapreduce`: 提供了MapReduce计算框架,支持大规模数据处理任务的并行执行。
`hadoop-tools`包提供了许多命令行工具,如`DistCp`用于数据复制,`archive`用于创建Hadoop档案文件等,这些都是开发和维护Hadoop集群时的实用工具。
在源代码分析过程中,理解每个包的功能及其依赖关系至关重要。例如,`conf`包负责读取系统配置,而`fs`包则封装了文件系统操作,两者之间存在依赖,因为配置文件可能存储在文件系统中。这种深度分析有助于开发者理解Hadoop的工作原理,优化性能,或者根据需求进行定制。
通过分析Hadoop源代码,我们可以学习到分布式系统的设计原则,如何处理大规模数据,以及如何实现容错性和可扩展性。这对于希望构建和维护大规模数据处理系统的工程师来说,是极其宝贵的知识。同时,这也为研究其他基于Hadoop的项目,如HBase(对应Google的BigTable)和Hive(用于数据分析)提供了基础。

DataXceiver 才是真正干活的地方,目前,DataXceiver 支持的操作总共有六条,分别是:
OP_WRITE_BLOCK (80)
:写数据块
OP_READ_BLOCK (81)
:读数据块
OP_READ_METADATA (82)
:读数据块元文件
OP_REPLACE_BLOCK (83)
:替换一个数据块
OP_COPY_BLOCK
(84)
:拷贝一个数据块
OP_BLOCK_CHECKSUM
(85)
:读数据块检验码
DataXceiver 首先读取客户端的版本号并检验,然后再读取一个字节的操作码,并转入相关的子程序进行处理。我们先看一下
读数据块的过程吧。
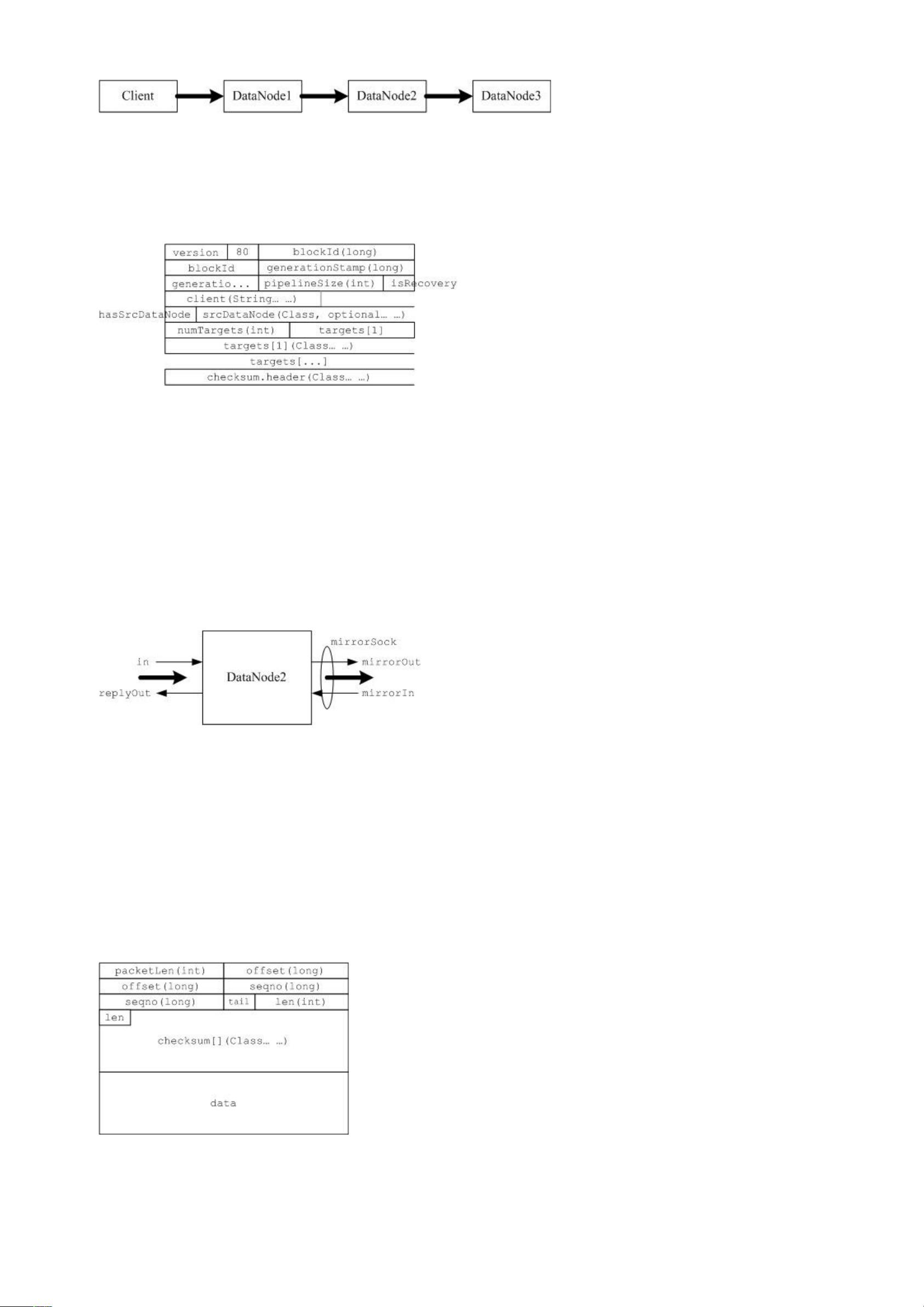
首先看输入,下图是读数据块时,客户端发送过来的信息:
包括了要读取的 Block 的 ID,时间戳,开始偏移和读取的长度,最后是客户端的名字(貌似只是在写日志的时候用到了)。根
据上面的信息,我们可以创建一个 BlockSender,如果 BlockSender 没有出错,返回客户端一个正确指示后,否则,返回错误
码。成功创建 BlockSender 以后,就可以开始通过 BlockSender.sendBlock 发送数据。
下面我们就来分析 BlockSender。BlockSender 的构造函数看似很复杂,其实就是根据需求(特别是在处理 checksum 上,因为
checksum 是基于块的),打开相应的数据流。close()用于释放各种资源,如已经打开的数据流。sendBlock 用于发送数据,数
据发送包括应答头和后续的数据包。应答头如下(包含 DataXceiver 中发送的成功标识):
然后后面的数据就组织成数据包来发送,包结构如下:
各个字段含义:
packetLen
:包长度,包括包头
offset
:偏移量
seqno
:包序列号
tail
:是否是最后一个包
len
:数据长度
checksum
:检验数据
data
:数据块数据
需要注意的,在写数据前,BlockSender 会校验数据,保证数据包中的 checksum 和数据的一致性。同时,如果数据出错,将会
有 ChecksumException 抛出。
数据传输结束的标志,是一个 packetLen 长度为 0 的包。客户端可以返回一个两字节的应答
OP_STATUS_CHECKSUM_OK
(5)
Hadoop
源代码分析(一四)
继续 DataXceiver 分析,下一块硬骨头是写数据块。HDFS 的写数据操作,比读数据复杂 N 多倍。读数据的时候,只需要在多个数
据块文件的选一个读,就可以了;但是,写数据需要同时写到多个数据块文件上,这就比较复杂了。HDFS 实现了了 Google 写文
件时的机制,如下图:

剩余81页未读,继续阅读
2022-03-12 上传
2021-09-06 上传
6675 浏览量
2012-01-05 上传
773 浏览量
2013-09-12 上传
2013-10-23 上传
2022-06-18 上传

妖孽横生
- 粉丝: 33
- 资源: 133
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
