Python爬虫解决中文乱码的三种方法
版权申诉
48 浏览量
更新于2024-09-02
收藏 2.31MB DOCX 举报
"这篇文档详细介绍了在Python网络爬虫中处理中文乱码的三种方法,包括修改requests.get().text为requests.get().content、手动指定网页编码以及使用通用编码方法。"
在Python网络爬虫实践中,中文乱码是一个常见的问题,尤其是在处理非UTF-8编码的网页时。本文档主要针对这一问题提供了三种有效的解决策略。
首先,方法一是改变获取网页内容的方式。通常,我们使用`requests.get().text`来获取网页的文本内容,但这种方式可能会导致乱码。原因是`text`默认将内容解码为UTF-8,如果网页实际编码是GBK等其他编码,就会出现乱码。因此,可以改用`requests.get().content`来获取原始的字节流,这样可以保留原始编码信息,然后根据实际编码手动解码。
其次,方法二是手动指定网页的编码。可以通过检查`response.apparent_encoding`来获取网页的编码信息,然后将其设置为`response.encoding`,确保在解码时使用正确的编码。如果`apparent_encoding`不可靠,也可以直接设定为预期的编码,如GBK。
最后,方法三是采用通用的编码方法,特别是对已经出现乱码的中文字符串进行处理。例如,可以先将乱码字符串用一种广泛支持的编码(如ISO-8859-1)编码,然后再用目标编码(如GBK)解码。这种方法适用于处理已知特定编码的乱码片段。
这三种方法各有优缺点,第一种简单直接,但可能无法处理所有情况;第二种需要正确识别网页编码,否则可能无效;第三种则是一种补救措施,适用于已知编码的乱码字符串。在实际开发中,应结合具体情况灵活运用,解决不同场景下的中文乱码问题。
总结来说,处理Python网络爬虫中的中文乱码问题,关键在于识别网页的正确编码,并确保在解码时使用该编码。通过理解各种编码之间的转换,以及requests库提供的工具,可以有效地避免和解决乱码问题,从而提升爬虫程序的稳定性和可靠性。在实践中,不断学习和掌握新的处理技巧,将有助于提高我们的编程技能。
盘点 3 种 Python 网络爬虫过程中的中文乱码的处理方
法
前言
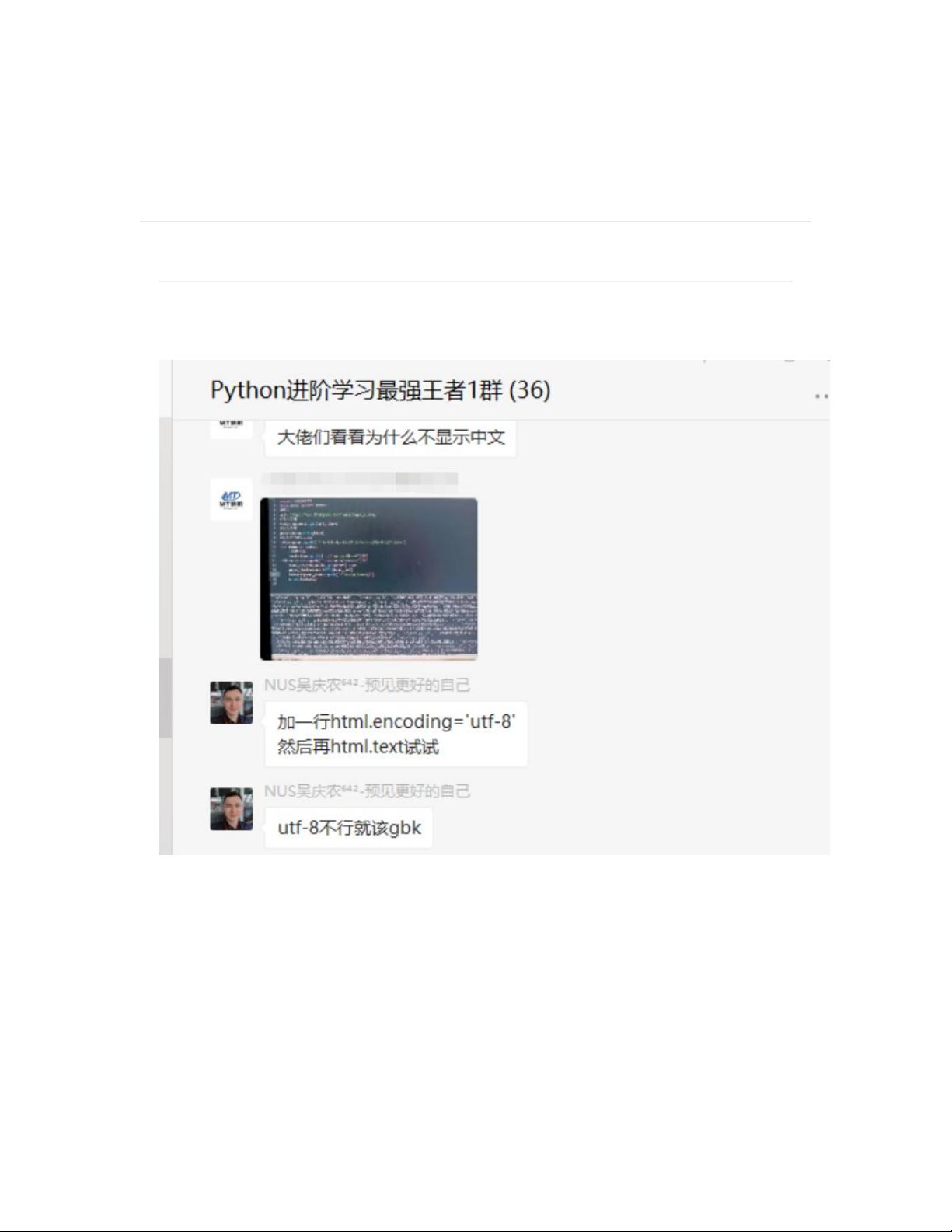
前几天有个粉丝在 Python 沟通群里问了一道关于使用 Python 网络爬
虫过程中中文乱码的问题,如下图所示。
下载后可阅读完整内容,剩余6页未读,立即下载
1206 浏览量
2024-07-30 上传
2021-09-30 上传
368 浏览量
2021-11-25 上传
138 浏览量
1293 浏览量
229 浏览量
点击了解资源详情

bingbingbingduan
- 粉丝: 0
- 资源: 7万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- CI--EA实施
- 24L01模块原理图+PCB两种天线三块板子
- Horiseon-proyect
- SimbirSoft
- 钟摆模型:用于不同实验的 Simulink 模型-matlab开发
- shopcart.me
- 6ES7214-1AG40-0XB0_V04.04.00.zip
- hivexmlserde jar包与配套数据.rar
- KeepLayout:使自动布局更易于编码
- worldAtlas
- AdvancedPython2BA-Labo1
- lsqmultinonlin:共享参数的全局参数非线性回归-matlab开发
- STK3311-WV Preliminary Datasheet v0.9.rar
- js实现二级菜单.zip
- 微店助理 千鱼微店助理 v1.0
- tao-of-rust-codes:作者的回购
