深度学习中的优化策略:随机梯度下降与正则化技术
需积分: 0 170 浏览量
更新于2024-08-04
收藏 1.71MB DOCX 举报
"神经网络训练方法与优化策略"
在神经网络的训练过程中,有几种重要的概念和技术用于提高模型性能和防止过拟合。本章节主要讨论了以下几点:
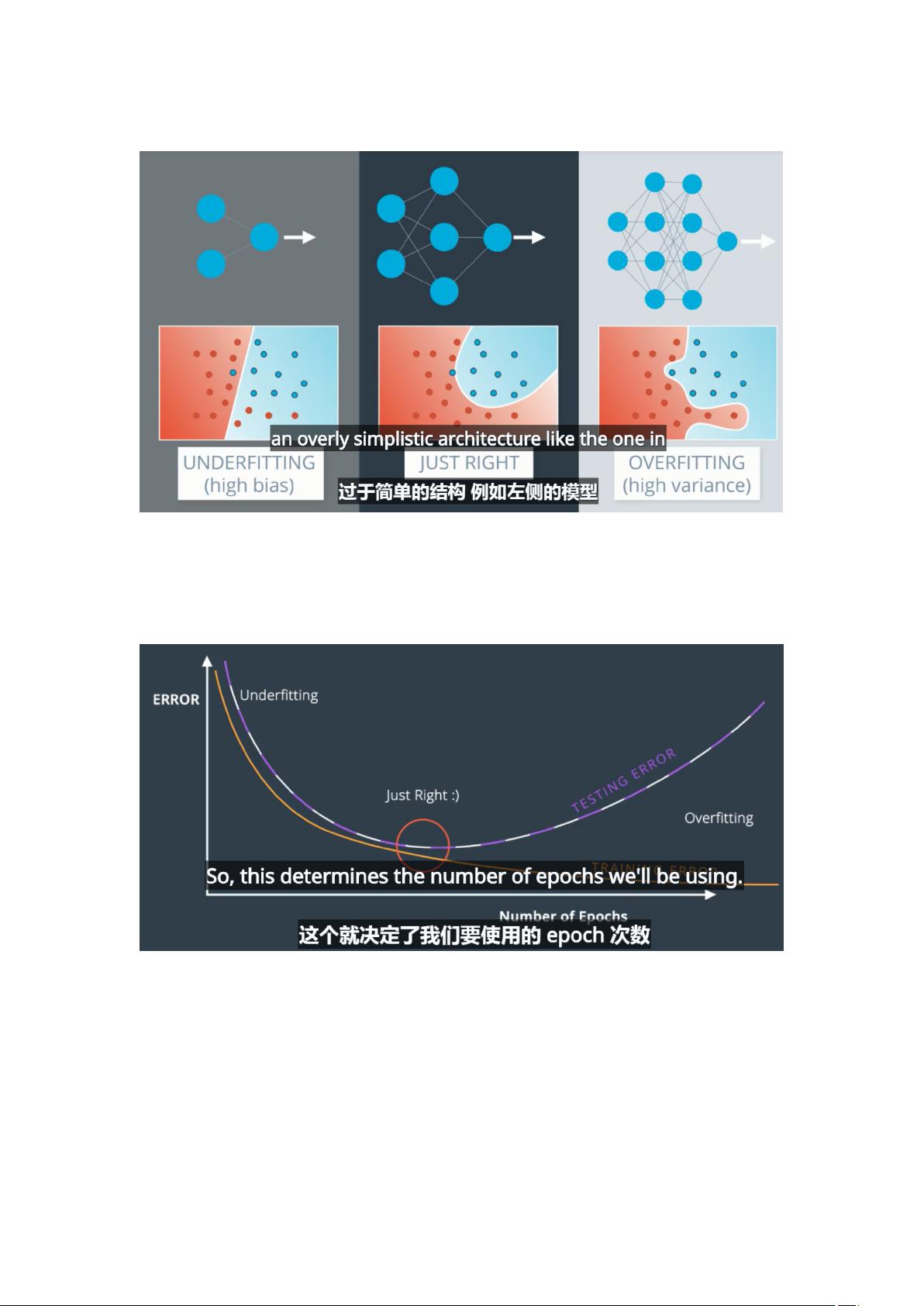
1、**过拟合与欠拟合**:过拟合是指模型在训练集上表现良好,但在未见过的数据(测试集)上表现差,这是因为模型过于复杂,过度学习了训练数据的噪声。相反,欠拟合则是模型对训练数据的学习不足,表现为训练和测试数据上的表现都不理想,通常需要增加模型复杂度或训练时间。
2、**早期停止法**:这是一种简单有效的防止过拟合的方法,通过监控验证集的性能,一旦发现验证集上的性能开始下降,就立即停止训练,以保留模型在验证集上的最好状态。
3、**L1和L2正则化**:正则化是用于减轻过拟合的技术,L1正则化倾向于产生稀疏权重,有助于特征选择;L2正则化则通过惩罚权重的平方和来避免权重过大,防止模型过于复杂。
4、**Dropout**:Dropout是一种在训练期间随机关闭部分神经元的策略,以减少神经元间的依赖,增强模型的泛化能力。在测试阶段,所有神经元都参与计算,但权重会被调整以反映训练时的dropout概率。
5、**激活函数**:激活函数是神经网络的核心组成部分,如Sigmoid函数在深度网络中会出现梯度消失问题,而双曲正切函数(tanh)和Rectified Linear Unit (ReLU)常作为替代方案。ReLU函数尤其受到青睐,因为它在大部分区域具有非零梯度,解决了Sigmoid和tanh的梯度消失问题。
6、**随机梯度下降(SGD)与标准梯度下降(GD)**:GD需要计算所有样本的梯度来更新权重,计算量大,而SGD仅使用单个或一小批样本进行更新,速度快但可能导致优化波动。尽管SGD可能会陷入局部最小值,但在大型数据集上,它往往能更快地找到接近全局最小值的解决方案,尤其是在使用动量等优化算法时。
解决局部最优解的方法包括使用不同的初始化策略、改变学习率调度、使用更复杂的优化器(如Adam、RMSprop等)、引入正则化技术以及使用SGD的变体如Mini-Batch SGD,它们在一定程度上可以帮助模型跳出局部最优,寻找全局最优解。在实际应用中,结合这些策略可以有效地训练神经网络,提高其泛化能力和性能。
1、过拟合和欠拟合
2、早期停止法来缓解欠拟合
3、L1L2 正则化缓解过拟合
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-08 上传
2022-08-08 上传
2022-08-03 上传
2022-08-04 上传
2022-12-21 上传
2010-12-19 上传

wxb0cf756a5ebe75e9
- 粉丝: 28
- 资源: 283
 我的内容管理
展开
我的内容管理
展开







最新资源
- ncomatlab代码-EarlySpringOnset:评估21世纪的异常早春发作
- iODBC:开源的ODBC驱动程序管理器和SDK,可促进在linux,freebsd,unix和MacOS X平台上开发与数据库无关的应用程序
- sturcott3:我是一个非常好奇的人,开始了第二职业的开发。 随时打个招呼!
- pdf2pdf:通过将页面另存为图像并将图像的反转版本合并为一个PDF来反转提供的PDF文件的颜色
- search-user-list:演示
- 基于图像处理的手柄键位映射方案.zip
- 行业文档-设计装置-一种利用钢结构厂房柱间支撑制作的检修平台.zip
- copy-speed-test
- Druid(apache-druid-0.21.1-bin.tar.gz)
- pywikibot::robot:与MediaWiki API接口的Python库。 这是gerrit.wikimedia.org的镜像。 不要在此处提交任何补丁。 见https
- snaparound---adm-ui:控制您的 snaparound 用户数据
- ORAN:ORAN的尊重追踪机器人
- 基于协同过滤的中医书籍推荐系统,实现的基于user和item的协同过滤算法.zip
- SentimentAnalysis:基于字典的情感分析
- 电子行业周报:北水南下推动港股优质电子资产估值修复,看好代工设备封测功率景气度持续高涨.rar
- rpgmaster-realms
