Jim Liang的机器学习笔记:全英文详细图解
需积分: 48 38 浏览量
更新于2024-07-18
2
收藏 130.03MB PDF 举报
"这是一份由Jim Liang编写的全英文机器学习笔记,包含了丰富的图示和思维导图,旨在帮助读者以视觉化的方式理解各种机器学习模型。文档创建于2018年5月,版本号为0.92。作者强调这份笔记仅供个人学习使用,不应用于商业目的,且禁止未经授权的复制、修改或分发。"
在笔记中,Jim Liang主要分为两个部分来阐述机器学习的内容:
第一部分:基础概念
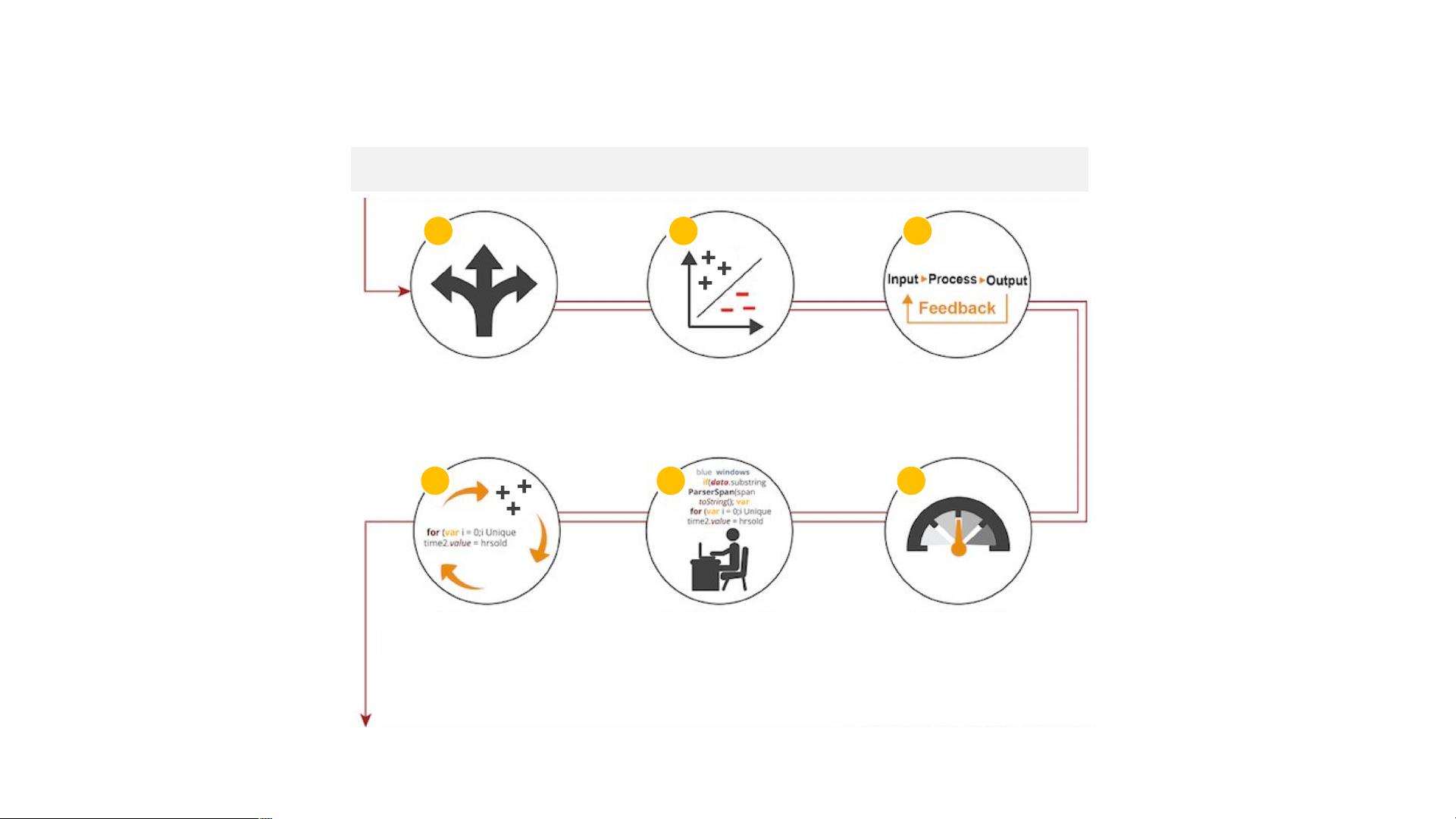
这部分涵盖了机器学习的整个流程,包括:
1. 概述:对机器学习的基本定义和应用背景的介绍。
2. 业务理解:理解问题的背景和目标,以及机器学习如何应用于实际业务场景。
3. 数据理解:了解数据的来源、质量和特征,为后续的数据预处理做准备。
4. 数据预处理:清洗数据,处理缺失值、异常值,进行数据转换等,使数据适合建模。
5. 建模:选择合适的算法,训练模型,如文档中提及的Nearest Neighbor、Support Vector Machines等。
6. 模型评估:通过交叉验证、准确率、召回率等指标评估模型性能。
7. 模型部署:将训练好的模型应用于实际环境,持续监控和优化。
第二部分:知名算法
这部分详细介绍了多种经典的机器学习算法:
1. 最近邻算法(Nearest Neighbor):一种基于实例的学习方法,用于分类和回归。
2. 支持向量机(Support Vector Machines):通过构建最大边界来分类,适用于高维空间。
3. 线性回归(Linear Regression):预测连续变量的值,通过找到最佳拟合直线来建立模型。
4. 逻辑回归(Logistic Regression):二分类问题的常用算法,输出结果为概率值。
5. 神经网络(Neural Network):模拟人脑神经元结构的模型,能处理复杂非线性问题。
6. 梯度下降(Gradient Descent):一种优化算法,常用于求解模型参数。
7. 朴素贝叶斯(Naïve Bayes):基于贝叶斯定理的分类算法,假设特征之间相互独立。
8. K-means聚类:无监督学习中的算法,用于发现数据的自然群组。
9. 主成分分析(PCA):降维技术,减少数据集的复杂性,同时保留大部分信息。
10. 决策树(Decision Trees):通过树形结构进行分类或回归,易于理解和解释。
11. AdaBoost:通过迭代增强弱分类器,形成强分类器。
12. 随机森林(Random Forest):包含多个决策树的集成学习方法,提高预测精度和鲁棒性。
这份笔记还包含了详细的目录结构,便于读者按需查阅。每个主题下可能都配有生动的图示,使得复杂的概念更加直观易懂。最后更新日期为2018年6月1日,说明了这是一份实时更新的学习资料。
总结来说,这份机器学习笔记是Jim Liang个人学习过程中整理的宝贵资料,它系统地介绍了机器学习的基础知识和常见算法,并通过图形化的方式加深理解,对于初学者和进阶者都是极好的参考资料。

Created by: Jim Liang
The image is designed by Asierromero - Freepik.com
What
what are you talking about ?
A computer program is said to learn from experience E
with respect to some class of tasks T and performance
measure P if its performance at tasks in T, as measured
by P, improves with experience E.
- Mitchell, T. (1997). Machine Learning, McGraw Hill
:: What’s machine learning ?


剩余242页未读,继续阅读
2018-08-23 上传
2023-04-21 上传
2024-04-23 上传
2024-09-29 上传
2024-05-16 上传
2024-02-28 上传
2024-09-24 上传

Ycliu8888
- 粉丝: 4
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
