多/单视图人体动作识别:层次分块词袋法与部分诱导多任务结构学习
68 浏览量
更新于2024-07-15
收藏 2.05MB PDF 举报
本文探讨的主题是"通过部分诱导的多任务结构学习进行多人/单视图人类动作识别",发表在2015年6月的IEEE Transactions on Cybernetics第45卷第6期。研究者们提出了一个统一的框架,旨在解决多视角和单视角人类动作识别问题。他们的方法首先关注于构建层次化的局部和全局视觉注意力表示,这是基于人体结构线索的,即body-wise bag-of-words (BoW) 表征,这有助于捕捉动作中的关键视觉特征。
在这个框架中,作者将多视角和单视角的人类动作识别视为一个部分约束的多任务结构学习(MTSL)问题。这种方法的两个主要优势在于:
1) 一致性与互补性:它维护了基于身体结构的动作分类与基于身体部分的动作分类之间的内在一致性,同时利用不同动作类别之间以及多个视角之间的互补信息。这种一致性有助于提高模型在处理复杂动作场景时的准确性。
2) 特征子空间发现:通过多任务学习,研究者能够发掘出既特定于动作又共享于动作的特征子空间。这样做不仅有助于减少过拟合,还能增强模型的泛化能力,使得模型在未见过的动作样本上也能表现出良好的性能。
值得注意的是,该研究还贡献了两个新颖的人类动作识别数据集,这对于评估和推动该领域的研究具有重要意义。这些数据集的设计和标注对于训练和测试多视角和单视角动作识别算法至关重要,反映了实际应用中可能遇到的多样性。
这篇论文的核心贡献在于提出了一种创新的方法,通过结合多任务学习和部分诱导的结构学习,实现了更有效的人类动作识别,无论是在多人还是单人、单视图的情况下,都能显著提升识别的准确性和模型的泛化能力。这对于计算机视觉和动作识别技术的发展具有重要的理论和实践价值。
1196 IEEE TRANSACTIONS ON CYBERNETICS, VOL. 45, NO. 6, JUNE 2015
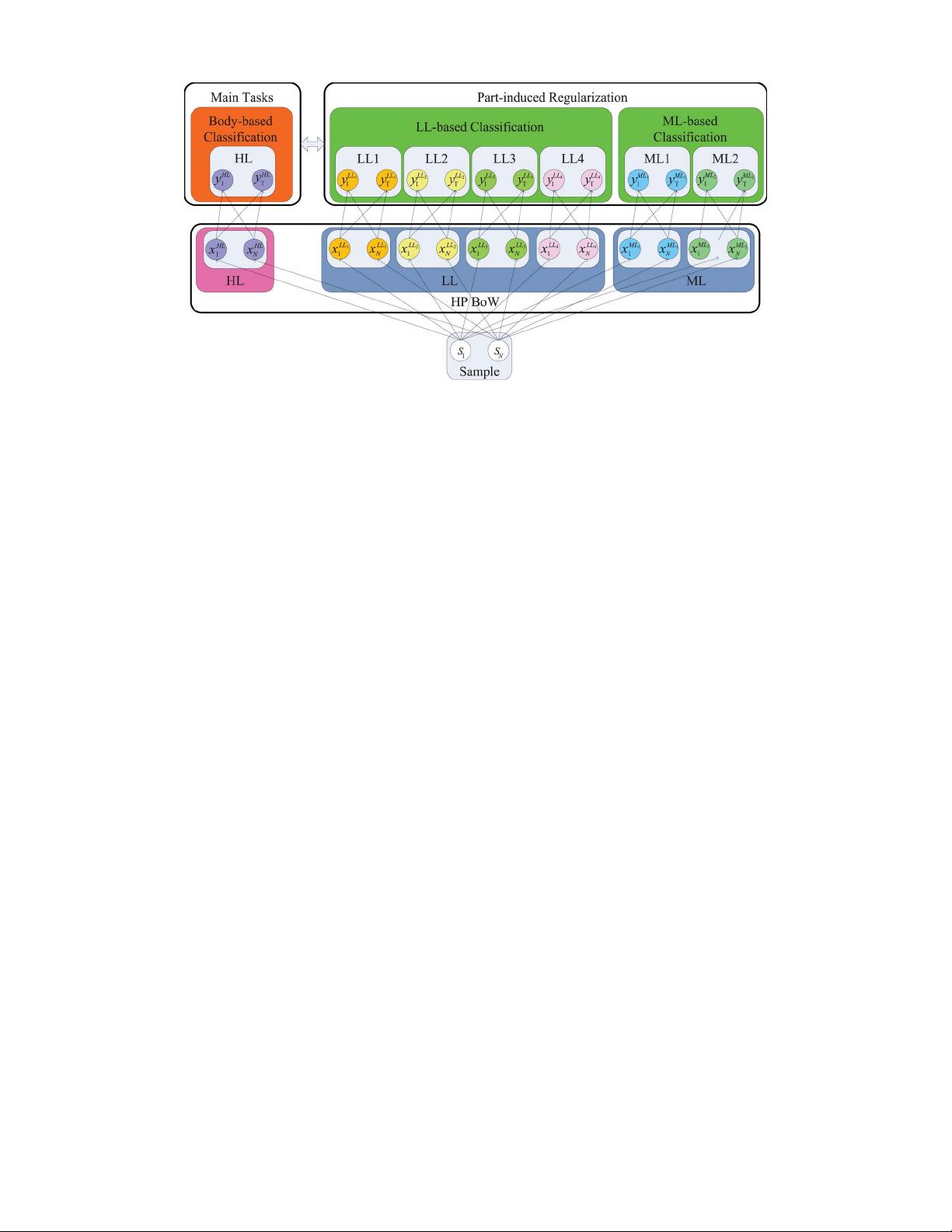
Fig. 1. Systematic framework.
skeleton data. We hope this dataset can benefit the
development of the learning-based methods.
b) Multiview multimodal human action recognition
dataset (MV-TJU): To our knowledge, most human
action datasets with RGB, depth and skeleton data
are captured in single view [39], [42] while there
is seldom multiview human action dataset with
data in three modalities. With the rapid spread
of Microsoft Kinect, we can simultaneously cap-
ture RGB/depth/skeleton data with an affordable
device. The depth and skeleton data can com-
pensate RGB data and significant benefit human
action recognition. We prepared the multiview
dataset (MV-TJU) with RGB/depth/skeleton data to
encourage the research on multiview human action
recognition with multimodality information.
Both datasets can be downloaded from
media.tju.edu.cn/dataset.html.
The rest of the paper is structured as follows. In Section II,
we briefly illustrate the framework of the proposed method.
Then the hierarchical partwise bag-of-words (HPBoW) rep-
resentation and the part-regularized MTSL are respectively
presented in Sections III and IV. The experimental method
and results will be detailed in Sections V and VI. At last,
conclusion are presented.
II. F
RAMEWORK
This paper propose a unified framework for multiple/single-
view human action recognition. To achieve this goal, the
method contains two essential components, feature represen-
tation and model learning, as shown in Fig. 1.
A. Feature Representation
The classic BoW representation has limited descriptive abil-
ity because it ignores the structure of human body and only
focuses on the global saliency. Furthermore, since one sample
can only be represented in one feature space, it is difficult to
design auxiliary tasks, which are closely related to main tasks,
to improve the performance. To handle this problem, we pro-
pose the HPBoW representation. HPBoW consists of seven
kinds of BoW features (limb, head, leg, foot, upper, lower,
full) in three levels [low level (LL), middle level (ML), high
level (HL)] as shown in Fig. 1 and each level focuses on the
visual saliency of different body areas. Consequently, each
sample can be represented in seven kinds of feature spaces
which are intrinsically correlated and will be further leveraged
to design joint MTL.
B. Model Learning
For model learning, we propose the part-regularized MTSL
method. We utilize the bodywise features in HPBoW (the HL
features in the pink box in Fig. 1) of different action cat-
egories in multiple/single views to construct the body-based
main tasks since the bodywise feature can represent the global
saliency of human action. The partwise features in HPBoW
(the LL and ML features in the blue box in Fig. 1)of
different actions in multiple/single views are utilized to con-
struct the part-based regularization (the green box in Fig. 1).
Furthermore, to realize feature learning, we propose to divide
the classic linear predictor into two components, including the
action-specific part and the action-shared part, to preserve
the category-wise characteristic and transfer the shared com-
mon knowledge across different categories. It is expected that
jointly optimizing both can boost the performance.
III. HPB
OWREPRESENTATION
The proposed HPBoW representation proceeds through
three steps as shown in Fig. 2.
A. Local Space-Time Feature Extraction
This step aims to extract the local saliency descriptors. Local
space-time feature extraction usually contains two continuous
steps, local saliency point detection and description. All the
aforementioned local space-time interest point (STIP) detec-
tors and descriptors can be utilized in this step. After local
STIP extraction, a video can be considered as a collection of
剩余14页未读,继续阅读
2021-03-07 上传
2020-03-14 上传
2023-03-31 上传
2023-03-31 上传
2023-06-07 上传
2023-09-24 上传
2023-12-08 上传
2023-03-30 上传

weixin_38643141
- 粉丝: 3
- 资源: 940
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
