决策树与集成算法:预测与特征归纳详解
需积分: 12 191 浏览量
更新于2024-07-09
收藏 1.82MB PDF 举报
决策树与集成算法是机器学习领域中的重要工具,尤其在数据分析和预测任务中发挥着关键作用。本资料由首都经济贸易大学统计学院的宋捷教授于2019年制作,旨在介绍决策树的基本概念、构建方法以及其在实际场景中的应用。
首先,决策树作为一种直观且易于理解的模型,模仿了人类做决策的过程。它的主要特点是将复杂的问题分解成一系列简单的选择,通过比较特征值来逐步做出决策。决策树可以分为两类:分类树和回归树,前者用于将数据分为不同的类别,后者则用于预测数值型目标变量。
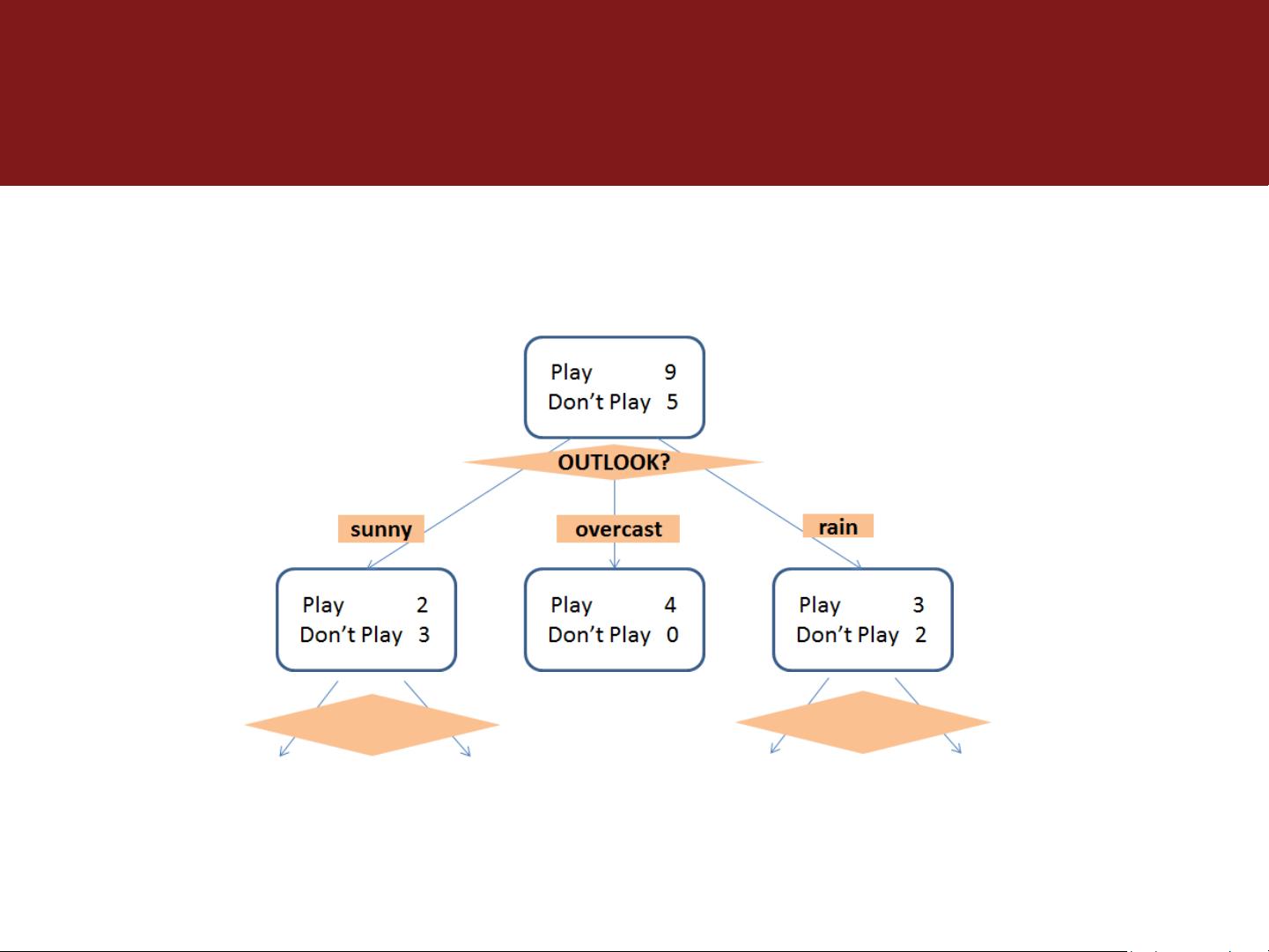
在上述举例中,为了预测某天俱乐部打球的人数,决策树被用来归纳天气状况、气温、相对湿度和是否有风等因素与顾客光顾行为之间的关系。Quinlan(1986)提供的数据集展示了如何通过这些特征训练决策树,其中包含14个样本,每个样本都有五种属性:天气、温度、湿度、风力和是否打球。
决策树构建过程中,数据集被分为训练样本,通过一系列的节点(如根节点、内部节点和叶节点)来形成树状结构。每个节点根据某个特征进行划分,直至达到一个叶子节点,该节点代表最终的决策结果或预测类别。在这个例子中,通过对天气状况的条件判断,构建出一条路径来预测是否有人打球,这体现了决策树的可解释性和可视化特性。
决策树的不同版本包括对决策树算法的改进,如C4.5、CART(Classification and Regression Trees)等,它们在处理噪声数据、过拟合等问题上有所优化。例如,C4.5引入了信息增益和基尼不纯度的概念,帮助选择最优特征进行分割,而CART则区分了分类和回归任务,并考虑了连续型特征的处理。
集成算法,如随机森林(Random Forest)和梯度提升机(Gradient Boosting),则是通过组合多个决策树来提高预测性能。它们通过并行构建多个决策树,然后取平均或者投票等方式集成预测结果,从而降低单个决策树的偏差,提高模型的稳定性和准确性。
总结来说,决策树与集成算法在实际应用中展现了强大的预测能力,尤其在处理具有明显因果关系的数据集时。掌握这些技术对于理解机器学习模型的构建和优化至关重要,无论是用于预测、分类还是解释性建模,都是数据科学家和机器学习工程师的必备技能。

决策树构建的基本想法:Hunt方法
2019/12/3
数据挖掘与机器学习
16
Hunt方法的要点是(假定在某一个节点)
• 如果数据已经只有一类了,则该节点为叶节点。否则
进行下一步。
• 寻找一个变量使得依照该变量的某个条件把数据分成
纯度较大的两个或几个数据子集。而用其它变量所划
分的子集不如该变量划分得那样纯。也就是说,根据
某种局部最优性来选择变量。然后对于其子节点回到
上一步。


剩余148页未读,继续阅读
2020-05-24 上传
2022-07-03 上传
2021-05-07 上传
2022-07-11 上传
2022-01-01 上传
2023-03-04 上传
2023-02-27 上传
2019-09-18 上传
2021-07-14 上传

qq_40363318
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
