2021年时序数据库误区解析——DataFun峰会议程分享
版权申诉
31 浏览量
更新于2024-07-05
收藏 3.08MB PDF 举报
"8-6.时序数据库的四个误区.pdf"
在大数据存储领域,时序数据库是一个专门处理带有时间戳的数据集的重要工具。时序数据库的使用在近年来随着物联网(IoT)、监控系统、日志分析以及性能指标追踪等应用场景的增多而变得越来越普遍。DataFunSummit峰会上,四维纵横的CEO姚延栋分享了关于时序数据库的四个常见误区,让我们一起来深入探讨。
**01 时序数据库介绍**
时序数据库是设计用来高效地处理和存储时序数据的数据库系统。这类数据具有时间序列的特点,即数据点按照时间顺序排列,每个数据点都附带有精确的时间戳。时序数据的基本元素包括:
- **时间戳**:每个数据点对应的时间点,用于记录数据产生的时刻。
- **指标(Metrics)**:被观测对象的特定属性,如设备温度、网络流量等。
- **标签(Tags)**:用于标识数据来源或环境的元数据,例如设备ID、地理位置等。
- **指标值(Fields)**:每个指标的具体数值,可能包含一个或多个值。
- **数据点(Datapoint)**:一个指标在特定时间点的完整信息,包括时间戳、指标值和可能的标签。
**02 时序数据库的误区**
时序数据库的设计通常考虑了读取效率和压缩存储,因此在理解它们时,有以下几个常见的误区:
**误区一:时序数据库只能用于监控系统**
实际上,时序数据库的应用远不止监控,还可以用于金融交易分析、物联网设备数据存储、性能指标追踪等多个领域。其时间序列特性和高效查询能力使得它在各种需要处理时间序列数据的场景中都能发挥重要作用。
**误区二:时序数据库不支持复杂查询**
虽然时序数据库的主要关注点在于快速写入和读取时间序列数据,但许多现代时序数据库,如InfluxDB和MatrixDB,已经提供了丰富的查询语言和聚合功能,能够处理复杂的查询需求。
**误区三:时序数据库不关心数据一致性**
尽管时序数据库通常强调高吞吐量和低延迟,但这并不意味着它们牺牲了数据一致性。许多时序数据库支持ACID(原子性、一致性、隔离性、持久性)事务或至少部分支持,以确保数据的可靠性。
**误区四:所有时序数据都应该以相同的方式存储**
时序数据可能有不同的模式,如窄表和宽表。窄表通常每个数据点只有一个指标值,而宽表可能包含多个指标值。选择哪种模式取决于具体应用场景和查询需求,而不是简单地一刀切。
**03 MatrixDB和其他时序数据库**
MatrixDB是一个例子,展示了时序数据库如何结合传统的关系型数据库功能,提供更广泛的支持。它可能包括对SQL的支持,同时优化处理时序数据的能力,以满足多种业务需求。
**04 结论**
了解并避免这些误区对于有效地利用时序数据库至关重要。时序数据库并非仅限于监控,它们在处理大量时间敏感数据时展现出的高性能和灵活性使其成为众多现代应用的理想选择。正确理解和使用时序数据库,能够帮助企业更好地管理和分析时间序列数据,从而提升决策质量和业务效率。
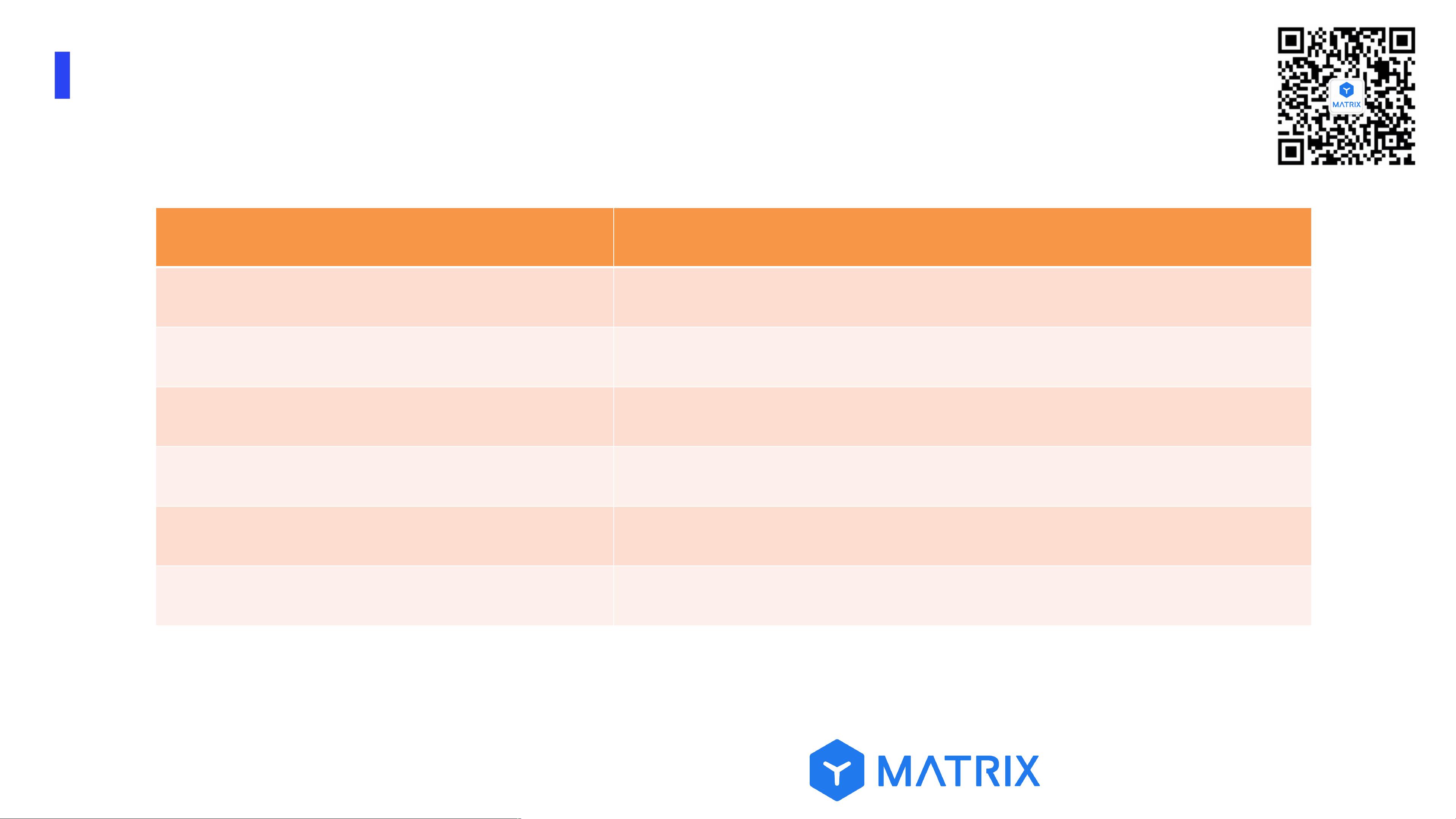
时序数据基本概念
DataFunSummit|
基本概念 描述
时序(
Time series)数据
带有时间戳的一系列数据
指标(
Metrics)
被测主体的某个维度,譬如冰箱的温度
时间戳(
Timestamp)
时刻值
标签(
Tags)
数据的标记,通常标记数据源信息,一个或者多个
指标值(
Fields)
指标数据值,可以有一个或者多个值
数据点(
Data point)
一个指标某个时刻的数据
剩余29页未读,继续阅读
2022-03-18 上传
2023-08-17 上传
2024-11-25 上传
2024-11-25 上传
2024-11-25 上传
2024-11-25 上传
2024-11-25 上传
2024-11-25 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
