Hadoop集群探索:Hive应用开发详解
需积分: 9 115 浏览量
更新于2024-07-15
收藏 1.04MB PDF 举报
"Hadoop_Hadoop集群(第14期)_Hive应用开发.pdf"
本文主要探讨了Hadoop集群中的Hive应用开发,Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。以下是详细的知识点介绍:
1. **Hive服务**:
Hive提供了多种服务接口,包括HiveShell、Thrift服务器、Web接口、元数据服务以及JDBC/ODBC支持,这些服务增强了其功能性和可扩展性。
2. **HiveShell**:
- HiveShell是Hive的基本交互界面,用户可以通过它来编写和执行HiveQL(Hive的SQL方言)语句。在HiveShell中,每条语句以分号结尾。
- HiveShell也允许执行Hive的管理命令,如导入jar包、设置临时环境变量等。
3. **HiveQL执行**:
- 查询示例:`select name from xp;` 当执行这样的查询时,Hive会启动一个MapReduce作业来处理数据。
- HiveShell还支持HDFS文件操作,用户可以直接在shell中使用dfs命令查看HDFS上的文件。
4. **数据存储**:
- Hive的数据仓库位于HDFS的`/user/hive/warehouse`目录下,每个表对应一个以表名为名的子目录。
- 表内的数据、分区目录和桶文件等都存储在这个目录下。
- 查询日志默认保存在本地的`/tmp/<user.name>`目录,而MapReduce执行计划则存储在`/tmp/<user.name>/hive`。
5. **配置属性**:
- `hive.metastore.metadb.dir`:用于设置HDFS上的元数据目录。
- `hive.querylog.location`:指定查询日志的存放位置。
- `hive.exec.scratcher`:设定HDFS上的临时文件目录。
6. **设置和查看临时变量**:
- 用户可以通过`set`命令设置临时变量,如`set fs.default.name=hdfs://192.168.1.2:9000`,这仅在当前会话中有效,便于切换不同的执行环境。
Hadoop集群中的Hive应用开发是一个关键环节,它使得大数据分析变得更加便捷。通过Hive,用户无需深入理解底层的MapReduce,即可进行复杂的数据处理和分析任务。Hive的灵活性和易用性使其成为大数据处理领域的一个重要工具。
创建时间:2012/3/24 修改时间:2012/3/26 修改次数:0
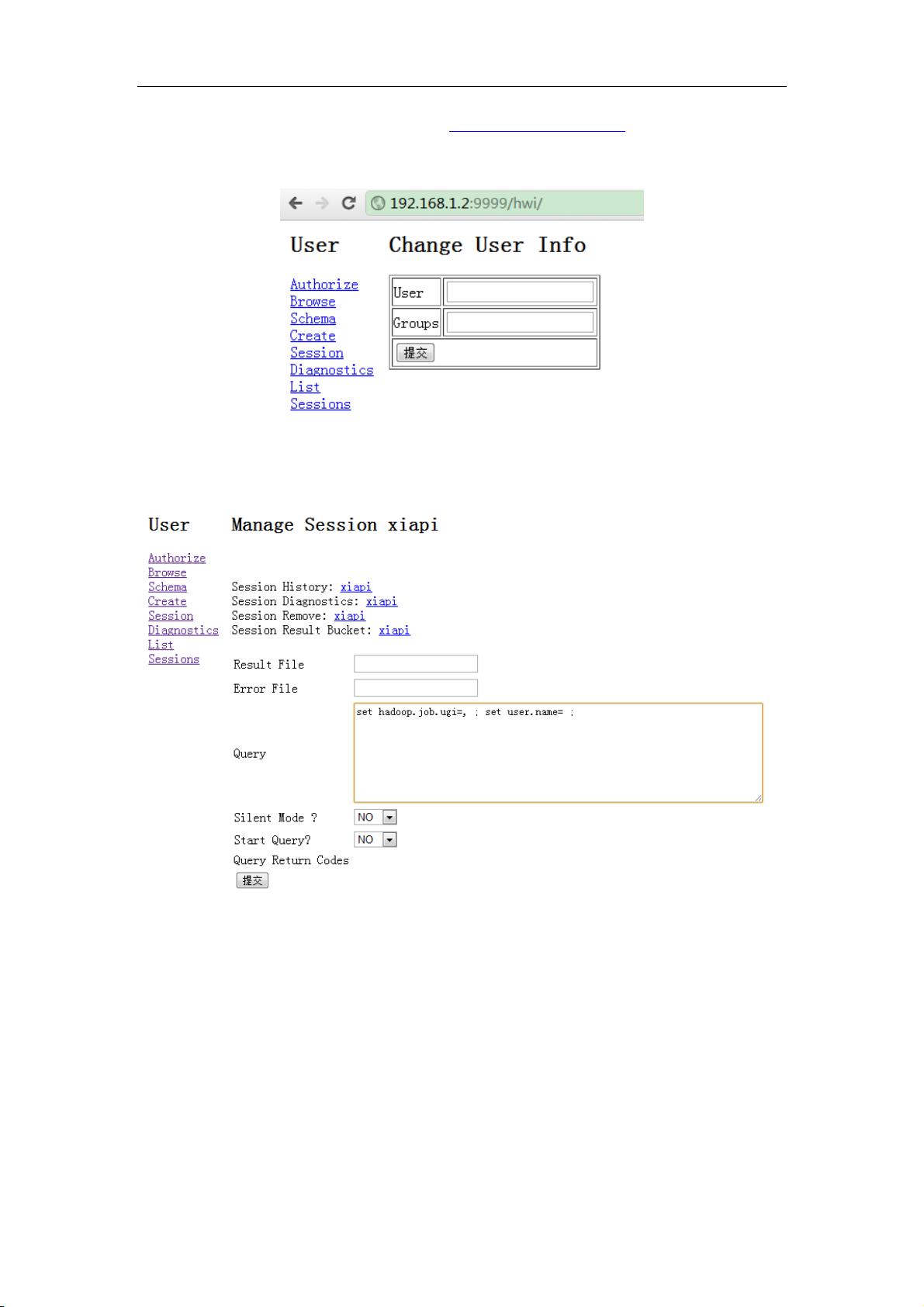
完成上述工作之后,在浏览器键入地址http://host_name:9999/hwi,即可进入Hive的Web
页面,如图 1.4-1 所示。
图 1.4-1 Hive 的 Web 界面
点击“Create Session”创建会话,在如图 1.4-2 所示的界面中可以执行查询操作。
图 1.4-2 查询页面
可以看到 Hive 的网络接口拉近了用户和系统的距离,我们可以通过网络接口之间创建
会话并进行查询。用户界面和功能展示非常直观,适合于刚接触到 Hive 的用户。
2、HiveQL详解
HiveQL 是一种类似 SQL 的语言,它与大部分的 SQL 语法兼容,但是并不完全支持 SQL
标准,如 HiveQL 不支持更新操作,也不支持索引和事务,它的子查询和 join 操作也很局
限,这是因其底层依赖于 Hadoop 云平台这一特性决定的,但其有些特点是 SQL 所无法企
及的。例如多表查询、支持 create table as select 和集成 MapReduce 脚本等,本节主要介绍
Hive 的数据类型和常用的 HiveQL 操作。
河北工业大学——软件工程与理论实验室 编辑:虾皮
5

剩余31页未读,继续阅读
2022-03-20 上传
2018-03-23 上传
2022-03-20 上传
2022-03-20 上传
2022-03-20 上传
2022-03-20 上传
2022-03-20 上传
2019-09-26 上传
2019-10-29 上传

app_code
- 粉丝: 152
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- java版商城源码-4sg:小而简单的SVGSankey生成器(使用XSLT)
- FPGA实现推箱子游戏.7z
- Single-Price-Grid-Component
- RaspberryPi 安装 WindowsArm 驱动 20200315drv_rpi4.zip
- PiperBlocklyLibrary:CircuitPython库支持使用RP Pico微控制器的块编码
- 易语言图片任意旋转源码.zip易语言项目例子源码下载
- Grades_Calc
- cschool:基本的Rails应用程序中的基本代码学校-谁想要雄心勃勃的人都可以免费打开手提袋
- 码
- data-structure
- 行业文档-设计装置-一种笔尾设置可折叠掏耳勺的方便笔.zip
- 华为简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- usov.tech
- 蒂莫·格拉斯特拉
- Webcam Fun +-开源
- semaphore_nuxt
