EMNLP 2019教程:分布式词向量的语义专业化
需积分: 31 105 浏览量
更新于2024-07-16
收藏 21.27MB PDF 举报
"本资源是EMNLP 2019年大会的一份关于分布式词向量表示的239页PPT报告,主要探讨了如何通过语义特定化方法优化词向量模型,以提升其在自然语言处理任务中的性能。报告由Goran Glavaš、Ivan Vulić和Edoardo Ponti三位学者共同撰写。报告内容涵盖了词向量模型的基础知识,以及语义相似性、词汇蕴含关系、跨语言转移等专题,并详细介绍了联合特殊化、后处理微调和后特殊化等方法。"
在自然语言处理领域,分布式词向量表示(如Word2Vec、GloVe等)已经成为理解和处理文本数据的关键技术。这些词向量能够捕捉词汇之间的上下文关系,从而捕获语义信息。然而,预训练的词向量模型往往无法完全反映出词汇在特定语义任务中的细微差异。
1)联合特殊化方法是将外部语言约束纳入词向量学习过程,以增强模型的语义表达能力。这通常涉及在训练过程中结合额外的语义知识库,如WordNet,以引导模型学习更具有针对性的向量表示。
2)后处理微调(post-processing retrofitting)模型是对预训练词向量的调整,目的是使其与外部语言约束更加一致。这种微调可以针对特定的词汇关系进行,例如同义词、反义词等,以提高模型在语义相似性任务上的表现。
3)后特殊化方法是上述微调概念的扩展,它不仅作用于单个词汇,而是作用于整个词向量空间。这种方法允许更广泛地传播和调整词向量,以适应更复杂的语义结构。
报告还深入讨论了:
2)语义相似性:区分相似性、相关性和其他类型的关系,分析了联合模型和微调模型的优缺点,以及显式微调与后特殊化在评估语义相似性方面的差异。
3)词汇蕴含(Lexical Entailment)和其他关系的特殊化:探讨如何通过特殊化方法改进词向量以反映词汇蕴含,构建向量空间中的嵌套层次结构,以及处理其他类型的词汇关系,并对其进行了评估。
4)跨语言转移:研究如何将特殊化技术应用于目标语言,支持资源贫乏语言的词汇资源构建,同时讨论了在资源有限环境下的挑战。
5)专业术语和短语的特殊化:这部分可能涉及如何针对特定领域的词汇和表达进行优化,以提升模型在专业或特定领域任务中的表现。
这份报告提供了深入理解词向量表示及其语义特定化策略的宝贵资源,对于从事自然语言处理研究和应用的人员来说,是一份非常有价值的参考资料。
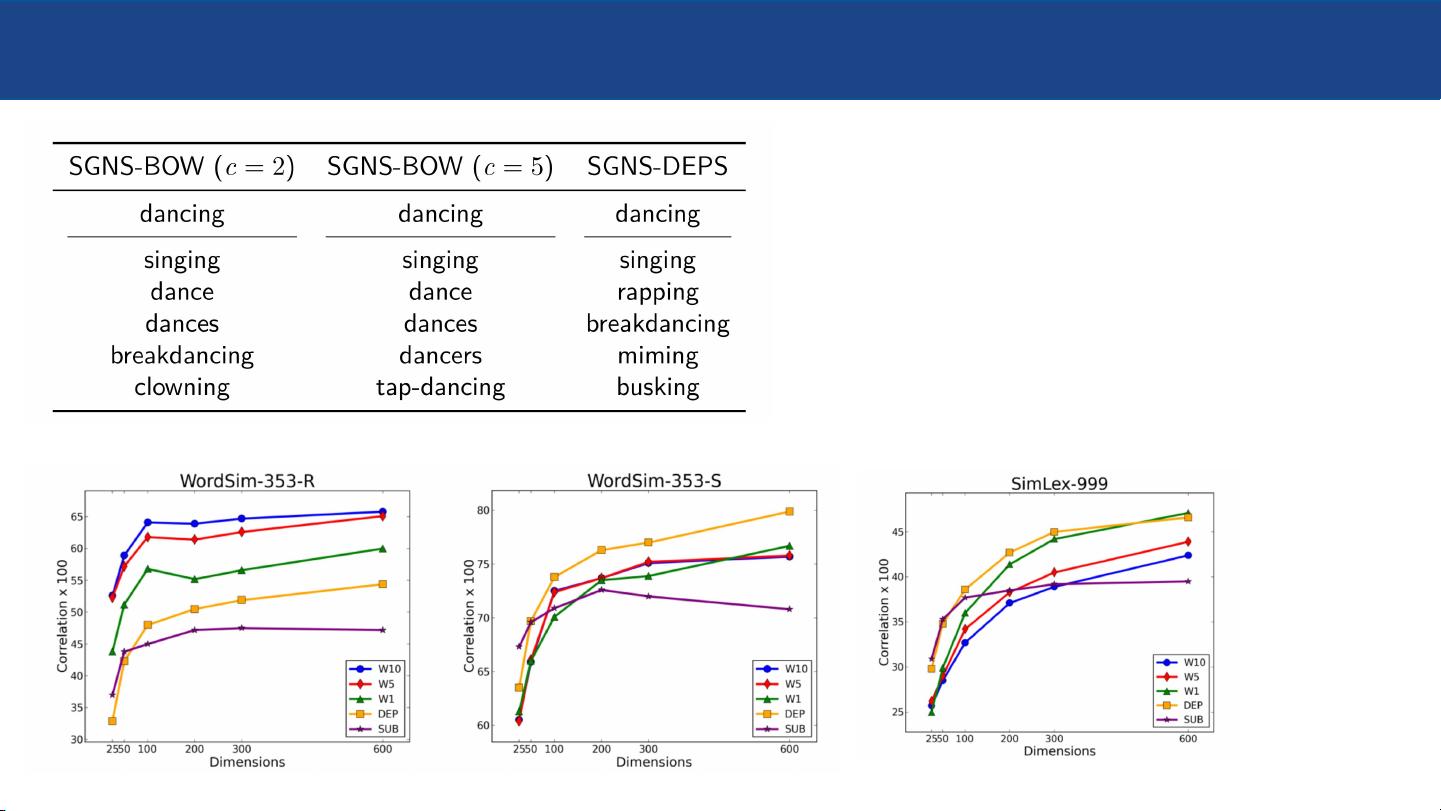
Context Impacts the Resulting Word Vectors
[Levy and Goldberg, ACL-14]
[Melamud et al., NAACL-16]



剩余238页未读,继续阅读
2021-05-14 上传
2022-04-26 上传
2021-02-20 上传
2021-02-21 上传
2021-03-20 上传
2022-06-28 上传
2021-05-09 上传
2021-05-03 上传

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
