Kafka入门:分布式消息系统的核心设计与操作详解
153 浏览量
更新于2024-09-02
收藏 207KB PDF 举报
Kafka使用入门教程第1/2页深入讲解了这个分布式消息传递系统的基本概念和独特设计。Kafka作为一个核心组件,是现代微服务架构中不可或缺的一部分,尤其在实时流处理和日志收集场景中。其主要特点是:
1. **消息组织与分类**:Kafka将消息按照主题(topic)进行组织,这是一种抽象的概念,用于逻辑上的归类。生产者(producer)负责向指定主题发布消息,消费者(consumer)则订阅并消费这些主题。
2. **分布式与分区**:Kafka采用分布式架构,消息存储在称为broker的服务器节点上,形成一个集群。每个主题都有多个分区(partition),每个分区内的消息按顺序排列,通过连续的序列号(offset)标识。这种设计确保了高吞吐量和数据的并行处理能力。
3. **数据持久性与时间窗口**:Kafka保留消息一段时间(默认为7天),在这期间,消息可被消费者消费。消费者维护他们读取消息的位置(offset),允许他们回溯或重新读取历史消息,同时不会干扰其他消费者。
4. **轻量级消费**:由于消息的顺序性和分区机制,消费者能够高效地读取消息,仅需维护自己的offset,不会对集群整体性能造成显著压力。这意味着消费者可以独立工作,无需担心其他消费者的活动。
5. **通信协议**:Kafka使用TCP协议进行客户端(如Java客户端)和服务端的通信,支持多种编程语言,为开发者提供了广泛的接入选择。
6. **日志管理**:Kafka的日志管理通过分区和时间策略实现,有助于保持数据的整洁和高效存储,同时也便于故障恢复和数据分析。
理解这些核心概念有助于你更好地使用Kafka构建实时数据管道和事件驱动的系统。后续章节可能会深入探讨Kafka的生产者和消费者模型、配置选项、生产和消费性能优化等内容,帮助你实现在大规模分布式系统中的消息传递。
Kafka使用入门教程第使用入门教程第1/2页页
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。这个独特的设计是什么样的呢
介绍
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。这个独特的设计是什么样的呢?
首先让我们看几个基本的消息系统术语:
•Kafka将消息以topic为单位进行归纳。
•将向Kafka topic发布消息的程序成为producers.
•将预订topics并消费消息的程序成为consumer.
•Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
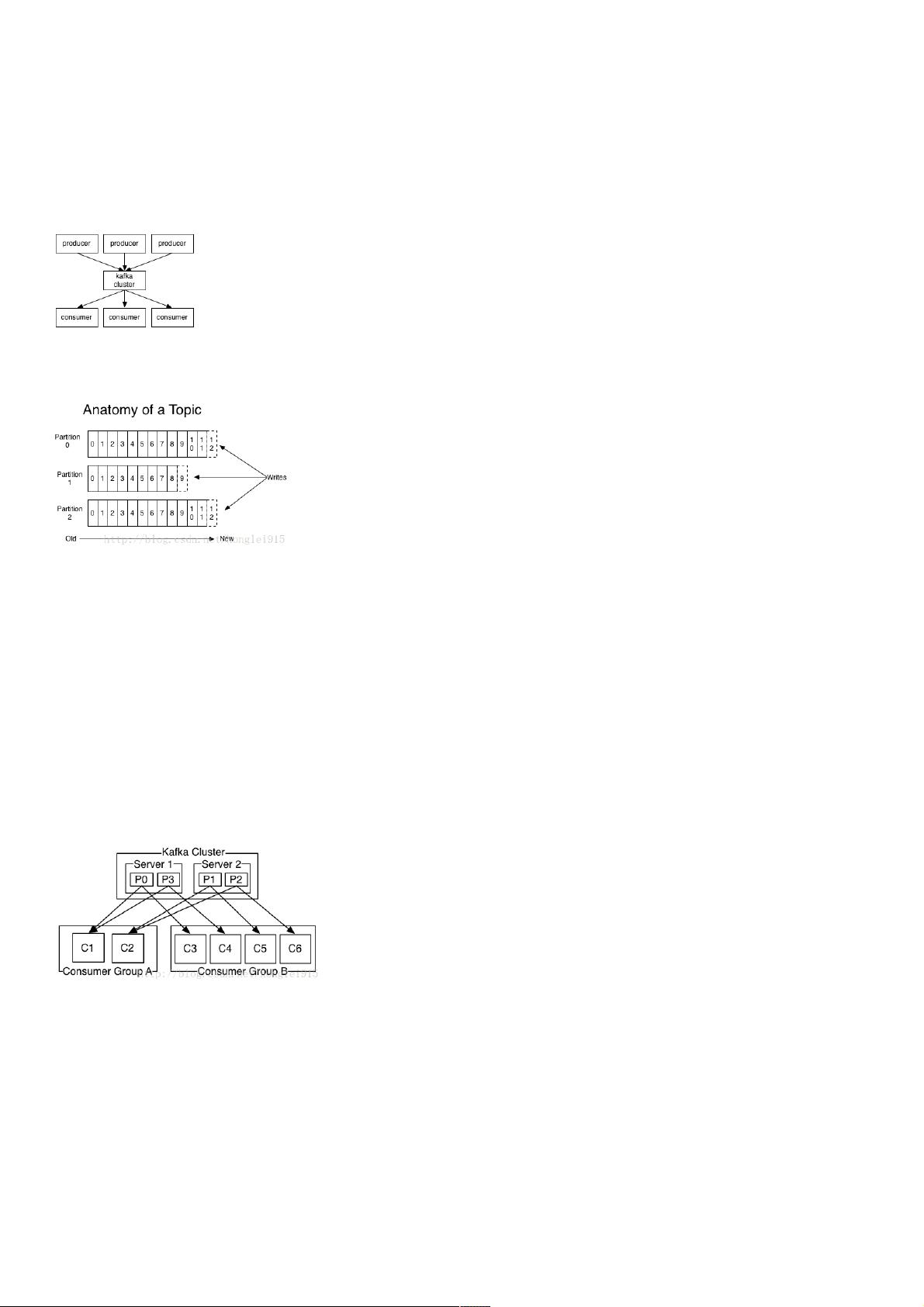
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
Topics 和和Logs
先来看一下Kafka提供的一个抽象概念:topic.
一个topic是对一组消息的归纳。对每个topic,Kafka 对它的日志进行了分区,如下图所示:
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它
将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。
实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset.这个offset有consumer来维护:一般情况下随着consumer不断的读取消息,这offset的值不断增加,但其实consumer可以
以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。
以上特点的结合,使Kafka consumers非常的轻量级:它们可以在不对集群和其他consumer造成影响的情况下读取消息。你可以使用命令行来"tail"消息而不会对其他正在消费消息的consumer造成影响。
将日志分区可以达到以下目的:首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。
分布式分布式
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”,leader负责处理消息的读和写,followers则去复制leader.如果leader down了,followers中的一台则会自动成为leader。集群中的每
个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就会据有较好的负载均衡。
Producers
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。
Consumers
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消
息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的
机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到
所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,
只不过订阅者是个组而不是单个consumer。
更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组
而不是单个consumer。
由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumerB组有4个
相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到
各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消
息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个
consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发
消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有
一个consumer组消费它。
接下来一步一步搭建接下来一步一步搭建Kafka运行环境。运行环境。
Step 1: 下载Kafka点击下载最新的版本并解压.
> tar -xzf kafka_2.9.2-0.8.1.1.tgz
> cd kafka_2.9.2-0.8.1.1
Step 2: 启动服务
Kafka用到了Zookeeper,所有首先启动Zookper,下面简单的启用一个单实例的Zookkeeper服务。可以在命令的结尾加个&符号,这样就可以启动后离开控制台。
> bin/zookeeper-server-start.sh config/zookeeper.properties &[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)...
现在启动Kafka:
下载后可阅读完整内容,剩余3页未读,立即下载
2022-04-11 上传
2017-02-07 上传
2017-06-28 上传
点击了解资源详情
点击了解资源详情
2022-04-28 上传
2024-01-12 上传
点击了解资源详情
点击了解资源详情

weixin_38551143
- 粉丝: 3
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- Haskell编写的C-Minus编译器针对TM架构实现
- 水电模拟工具HydroElectric开发使用Matlab
- Vue与antd结合的后台管理系统分模块打包技术解析
- 微信小游戏开发新框架:SFramework_LayaAir
- AFO算法与GA/PSO在多式联运路径优化中的应用研究
- MapleLeaflet:Ruby中构建Leaflet.js地图的简易工具
- FontForge安装包下载指南
- 个人博客系统开发:设计、安全与管理功能解析
- SmartWiki-AmazeUI风格:自定义Markdown Wiki系统
- USB虚拟串口驱动助力刻字机高效运行
- 加拿大早期种子投资通用条款清单详解
- SSM与Layui结合的汽车租赁系统
- 探索混沌与精英引导结合的鲸鱼优化算法
- Scala教程详解:代码实例与实践操作指南
- Rails 4.0+ 资产管道集成 Handlebars.js 实例解析
- Python实现Spark计算矩阵向量的余弦相似度
