Scrapy+Selenium爬取中国裁判文书网文书实践与踩坑
版权申诉
在本文档中,作者分享了利用Python爬虫技术,结合Scrapy框架和Selenium模拟浏览器的方式爬取中国裁判文书网(<https://wenshu.court.gov.cn/>)上裁判文书的经历。作者起初尝试暴力解析网页结构,但意识到这并不适合这种复杂的动态网站,转而选择Scrapy作为主要框架。
Scrapy是一个强大的、基于Python的Web抓取框架,适用于处理静态和半静态网页。它提供了高效的数据提取功能,以及分布式爬虫支持,非常适合批量抓取和存储数据。与之相比,Pyspider虽然也有类似的功能,但由于其文档更新较慢且在处理连续页面问题上存在局限性,作者最终决定使用Scrapy。
在具体实施过程中,作者首先设置了Scrapy爬虫去抓取前两页的裁判文书,每页最多抓取15份文书,以减少不必要的页面跳转。同时,通过Selenium模拟浏览器操作,控制了页面加载时间和元素选择,确保了爬取的稳定性和效率。
爬虫遇到的主要挑战包括:
1. 解析详情页时,需处理返回的list类型对象,正确提取所需信息,并避免使用XPath或CSS选择器在list内继续操作。
2. 对于页面元素的显示延迟和超时设置,需要进行细致的调试和优化。
3. 数据清洗方面,针对文书主体内容中不同部分(如当事人、法院原由、判决结果)的不规则div标签结构,进行了灵活的处理。
4. 针对下载中间件的问题,通过设置meta字段来区分文书列表和详情页面,实现了有效的链接管理。
5. 确保spiders代码中的链接访问策略,设置"dont_filter"参数,防止因重复链接过滤导致的逻辑错误。
6. 考虑到页面链接的不变性,为了避免陷入无限循环,需要正确处理下一页的跳转逻辑。
这个案例展示了在复杂网站爬取中如何有效地运用Scrapy和Selenium,以及如何应对常见的爬虫问题和陷阱。通过实践学习,作者对自己的技术水平有了更深的认识,并提供了有价值的爬虫技巧供读者参考。
scrapy+selenium之中国裁判文书网文书爬取之中国裁判文书网文书爬取
浅尝浅尝python网络爬虫,略有心得。有不足之处,请多指正网络爬虫,略有心得。有不足之处,请多指正
url = https://wenshu.court.gov.cn/
爬取内容:裁判文书
爬取框架:scrapy框架 + selenium模拟浏览器访问
开始想暴力分析网页结构获取数据,哈哈哈哈哈,天真了。看来自己什么水平还真不知道。
之后锁定pyspider框架,搞了四五天。该框架对于页面超链接的连续访问问题,可以手动点击单个链接测试,但是通过外部“run”操作,会获取不到数据。其实最后发现很多博客说pyspider的官网
文档已经很久没有更新了,企业、项目一般都会用到scrapy。scrapy框架结构如下图:
代码为爬取前两页数据,单页文书数量为5,通过selenium设置单页文书数量为最大值15,这样可以省去很多主页面的跳转、访问、解析时间。由于单页15个访问链接,外加2个文书列表界面,
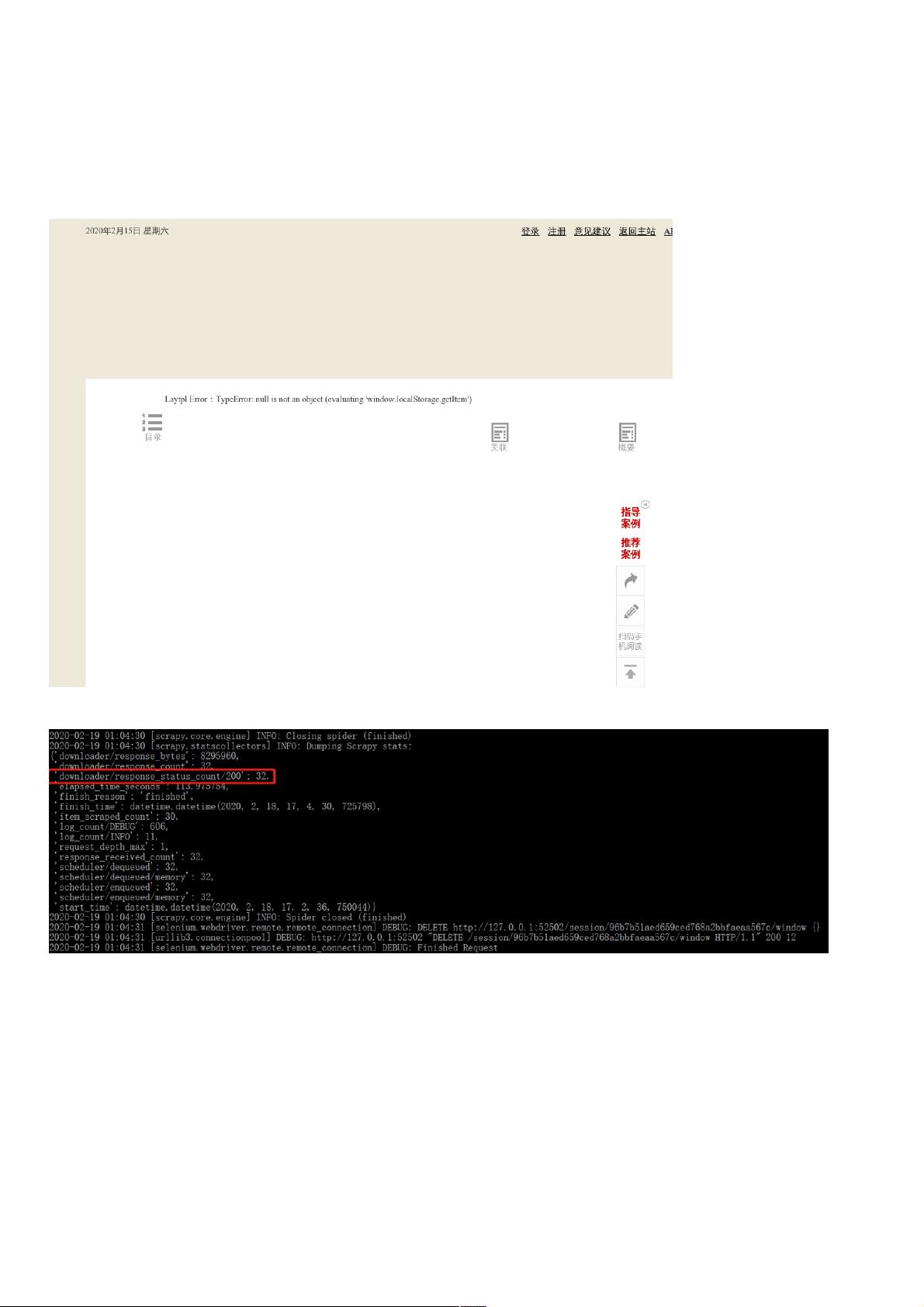
总共32次响应返回,响应码全部为”200″(成功响应)。以下为代码执行结果图:
此时数据库中显示插入的30条文书实体数据,以下为MongoDB中相应collection更新的数据:
下载后可阅读完整内容,剩余6页未读,立即下载
2019-01-10 上传
2021-04-01 上传
2023-07-12 上传
2021-03-05 上传
2021-05-12 上传
2024-02-25 上传

weixin_38731761
- 粉丝: 7
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
