深度学习文字检测方法综述:基于感受野增强和全卷积网络结合的新思路。
版权申诉
35 浏览量
更新于2024-03-06
收藏 1.74MB DOCX 举报
场景图像文字中承载的高级语义信息可以帮助我们更好地理解周围的世界,同时场景图像文字检测技术也可以广泛地应用于多媒体检索、视觉输入和访问,以及工业自动化。早期的文字检测技术使用传统的模式识别技术,主要分为以连通区域分析为核心技术和以滑动窗为核心技术的两种方法。传统的模式识别方法包含多个步骤,如字符候选区域生成、候选区域滤除、文本行构造和文本行验证,繁琐的检测步骤导致文字检测结果过于依赖中间结果且非常耗时。
随着计算机视觉和模式识别领域的发展,目标检测方法开始使用卷积神经网络(CNN),研究者们开始借鉴基于深度学习的目标检测方法来检测文字,产生了一系列基于回归的深度学习文字检测方法。这类方法主要是基于目标检测框架SSD(Single shot multibox detector)、Faster-RCNN(Region CNN)等进行针对文字特性的改进得到。这些方法通过回归水平矩形框、旋转矩形框以及四边形等形状来获得文字信息,实现了对场景图像中文字的准确检测。
感受野增强和全卷积网络是两种优化方法,用于提高场景文字检测的准确性和效率。感受野增强通过增加神经网络中每个单元的感受野大小,使其能够覆盖更多的局部信息,从而提高模型在整个图像上的理解能力。全卷积网络则是一种端到端的深度学习模型,能够对输入图像进行像素级别的预测,适用于场景文字检测这种需要对整个图像进行分析的任务。将感受野增强和全卷积网络结合起来,可以进一步优化场景文字检测的效果,使得模型在复杂场景中也能够准确地检测出文字。
综合上述内容,感受野增强和全卷积网络的结合为场景文字检测技术带来了新的突破。这种方法不仅提高了文字检测的准确性和效率,还能够更好地应用于多媒体检索、视觉输入和访问,以及工业自动化等领域。未来随着深度学习和计算机视觉的不断发展,相信场景文字检测技术会迎来更多的创新和进步,为我们的生活和工作带来更多便利和可能性。
输出层各部件的特征图通道数如图 2 所示, 输出层中, 输入的是 32 通道的融合特征,
目的是为了保证以少许的计算复杂度换取更高的检测精度. 最后的输出层包含 3 个
conv1×1conv1×1 模块, 分别将输入特征变换到 1 通道的文本得分图、4 通道的矩形距离
响应图和 1 通道的旋转角度响应图, 文本得分图和旋转矩形框的标签制作具体可参照文献
[15].
fi=⎧⎩⎨⎪⎪mi,conv3×3(conv1×1([bi−1;mi])),conv3×3(conv1×1([mi−1;ERFB(mi)])),i=1i=2 其他
fi={mi,i=1conv3×3(conv1×1([bi−1;mi])),i=2conv3×3(conv1×1([mi−1;ERFB(mi)])),其他
(2)
1.3 增强感受野模块
自然场景文字由于尺度大小和宽高比多变, 导致现有方法准确率欠佳. 本节通过加入
感受野模块(Receptive field block, RFB)来提升不同尺度和宽高比文字检测准确率. 受目标检
测领域中文献[16]方法的启发, 本文重新设计了这一模块, 并将其嵌入特征融合中. 图 3(a)展
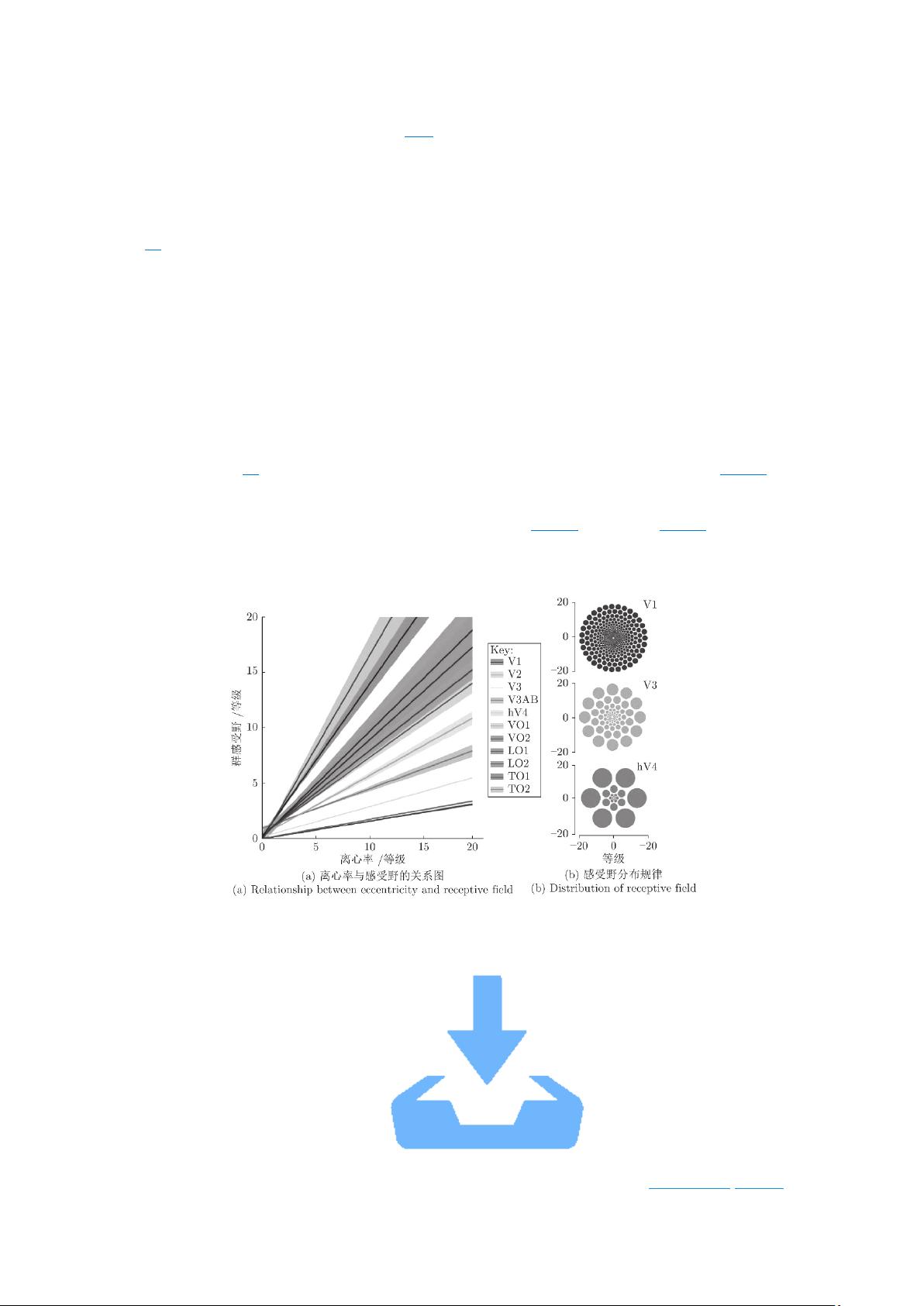
示了在人类视觉系统中, 感受野的大小在人类视网膜图中是离心率的函数, 感受野随着离心
率的增加不断增大; 在不同视觉系统中, 感受野也不同, 图 3(b)展示了基于图 3(a)中参数的
感受野空间阵列, 显示了感受野的分布规律, 每个圆的半径表示在对应离心率下的感受野大
小.
图 3 离心率与感受野的关系图
Fig. 3 Structure of the human visual system's receptive field
下载: 全尺寸图片 幻灯片
下载后可阅读完整内容,剩余18页未读,立即下载
点击了解资源详情
161 浏览量
1751 浏览量
142 浏览量
2022-07-01 上传
2022-07-02 上传
2021-09-20 上传
2022-05-29 上传
2022-12-01 上传

罗伯特之技术屋
- 粉丝: 4611
 我的内容管理
展开
我的内容管理
展开








最新资源
- 易语言网络校时专家源码解析与应用
- 2015年法国省级选举数据获取与gulp静态文件服务教程
- Java3D开发环境搭建指南及插件下载
- Java开发的试题库管理系统功能详解
- Nios II软件开发参考手册详细指南与教程
- VC++开发USB通信协议指南
- 西科大专用new_holytelecom替换协同通信拨号器
- PHP初学者的Hello World测试案例解析
- 易语言实现网络时间自动更新功能
- jBpm开发入门与精通全攻略
- Comet技术实例解析:Ajax与Iframe实现
- Unix学习资源精选:FreeBSD指南与源码解读
- ADB工具包2.0版本发布,优化Android ADB/FASTBOOT操作
- BOSHI210小票机驱动软件深度评测
- OpenGL ES API参考手册(CHM格式)
- 易语言实现cmd远程服务与控制台交互技术解析
