机器翻译技术:Encoder-Decoder模型与注意力机制解析
148 浏览量
更新于2024-08-30
收藏 1.22MB PDF 举报
本资源主要探讨了机器翻译的几种关键技术,包括编码器-解码器模型、注意力机制以及Seq2seq模型,同时也提到了Transformer这一先进的模型架构。在机器翻译任务中,由于输入和输出的长度可能不一致,因此需要采用特定的模型结构来处理这种不对称性。
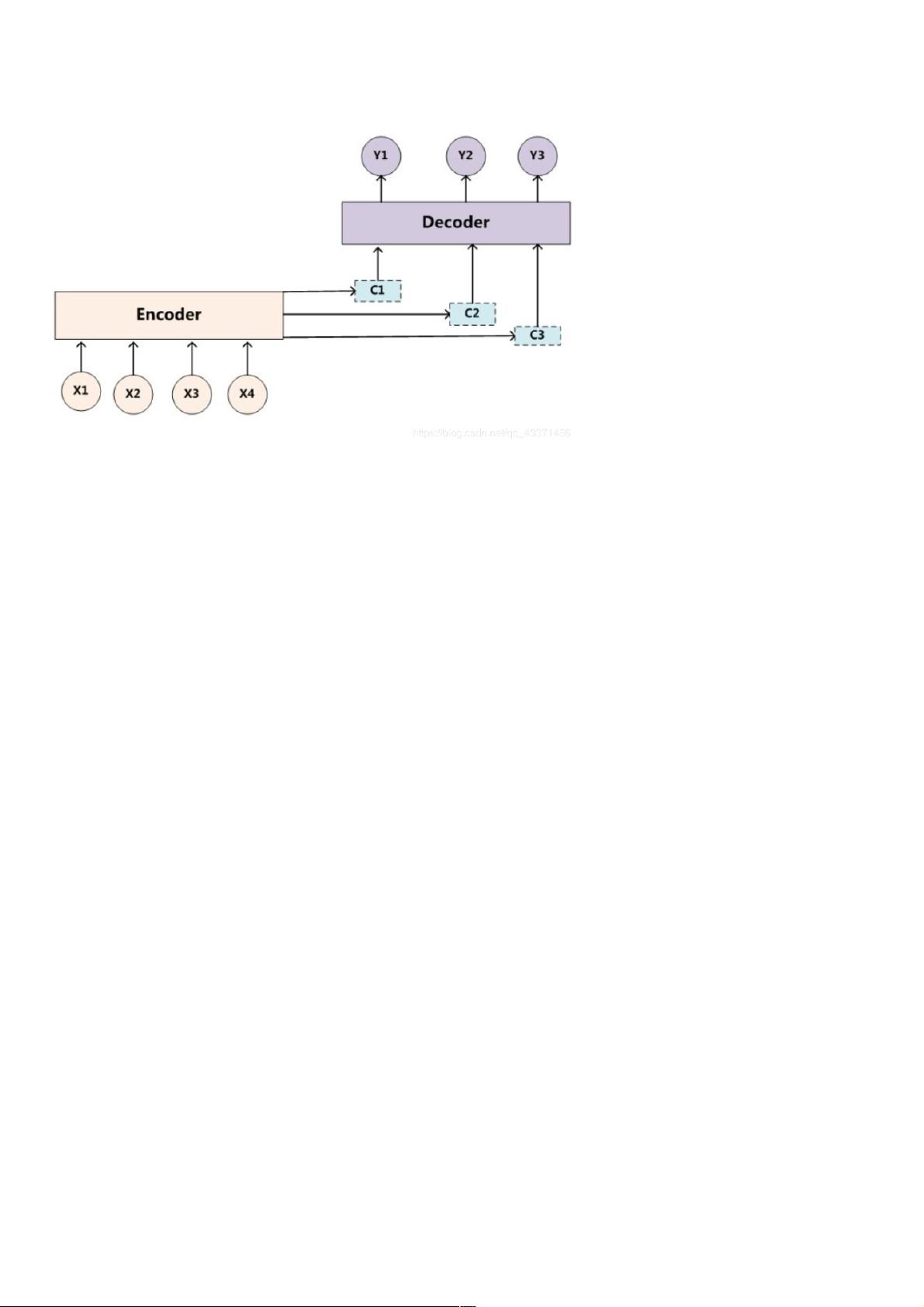
在Seq2seq模型中,编码器-解码器架构扮演了核心角色。编码器负责接收输入序列,如“我是中国人”,并将这些信息压缩成一个固定长度的向量,通常称为上下文向量(C)。这个上下文向量包含了输入序列的所有重要信息,用于解码器生成目标序列,如“i am Chinese”。编码器和解码器通常使用循环神经网络(RNN),因为它们能够处理变长序列,并且可以捕捉序列内的依赖关系。
在训练过程中,为了指示句子的开始和结束,会在序列末尾添加特殊标记如<eos>(end of sentence),并在解码器的第一个输入位置添加<bos>(beginning of sentence)。为了确保序列长度的一致性,短于预设长度的句子会被填充到规定的长度。
编码器的输入可以是所有隐藏层状态的组合,如C=q(h1,h2…ht),也可以直接使用最后一个隐藏层状态c=ht。在训练时,通常使用教师强制(teacher forcing)策略,即将真实的下一个词(y1)作为解码器的输入,而不是上一时刻的预测输出(y_hat1)。
在解码阶段,贪心算法选择每个时间步的最可能输出,但这可能无法保证全局最优解。为了解决这个问题,采用了束搜索(Beam Search)策略,保留当前最优的k个候选序列,考虑到长度的惩罚项Lα,以平衡准确性和效率。
注意力机制的引入是为了解决Seq2seq模型中所有输入对解码的影响被平均化的问题。在翻译场景下,例如“tomchasejerry”到“Tom chases Jerry”,“Jerry”这个词的翻译更依赖于它自身,而非“tom”和“chase”。注意力机制允许解码器在生成每个目标词时动态地关注源序列的不同部分,赋予不同单词不同的权重,从而提高了翻译的质量和准确性。
这篇资料深入讲解了机器翻译中的关键技术和方法,特别是如何利用Encoder-Decoder模型、注意力机制和束搜索策略来提高翻译性能,对于理解和应用机器翻译技术具有很高的价值。
Task04:机器翻译及相关技术;注意力机制与:机器翻译及相关技术;注意力机制与Seq2seq模型;模型;Transformer
如果我们现在要做个中英文翻译,比如我是中国人翻译成 ‘i am Chinese’.这时候我们会发现输入有 5个中文字,而输出只有三个英文单词. 也就是输入长度并不等于输出长度.这时候我们
会引入一种 编码器-解码器的模型也就是 (Encoder-Decoder).首先我们通过编码器 对输入 ‘我是中国人’ 进行信息编码, 之后将生成的编码数据输入 decoder 进行解码.一般编码器和解
码器 都会使用循环神经网络.
当然为了使机器知道句子的结束我们会在每个句子后面增加 一个<eos> 表示 句子的结束.使得电脑可以进行识别.在训练的时候 我们也一般会在解码器的第一个输入阶段加上<bos>表
示预测的开始.
同时为了使每个句子保持相同长度,我们 会人为预先规定句子长度,若句子没有达到长度,那么我们会对句子进行填充,使得其长度达到规定长度.
作为编码器的输入 我们一般使用 C = q(h1, h2…ht)作为第一个隐藏层输入,一般的我们也可以直接使用c = ht,不用包含之前所有的隐藏层信息。
在训练的时候我们一般会使用强制教学强制教学,也就是 不把y_hat1的预测数据当做编码器的第二个输入, 而是直接用标签数据的y1当做输入。
当我们使用贪心算法再对y进行softmax的时候,我们对每个输出的y进行当前最优的选择。可能会达到全局最优的情况
如下图所示 –引用自 动手学深度学习
下载后可阅读完整内容,剩余5页未读,立即下载
2021-01-06 上传
2021-01-07 上传
2021-01-07 上传
2021-01-06 上传
2021-01-06 上传
2021-01-07 上传
2021-01-06 上传
2021-01-20 上传
点击了解资源详情

weixin_38658982
- 粉丝: 7
- 资源: 940
 我的内容管理
展开
我的内容管理
展开







最新资源
- pomodoro:用榆木制成的Pomodoro应用程序
- Shiba_Inu-开源
- [信息办公]PHP Classifieds v7.3_classifieds.rar
- Scanned-Images-Tools,c#二维码解析源码,c#
- Gujarati Ringtone Donwload -crx插件
- Day13-14
- backbone-todo
- Advanced-DB-project
- Habbig Aceitação Automática de Flash-crx插件
- tiktok-clone-react:React,Ticker,Firebase。 蒂科克(Tiktok)的照片403ошибкуинеотдаетвидео
- [影音娱乐]星辰音乐DJ系统 v1.01最终版_xcdjv1.01.rar
- 计算齿数:使用一些图像处理算法来计算齿轮上的齿数。-matlab开发
- GameWorldApp,抖音表白恶搞小程序c#源码,c#
- evstuff:半熟事物的常规沙箱,主要与Anki,日语和InDesign有关
- pycharm快捷键ReferenceCard整理
- spring-loaded-example
