Python数据分析:Numpy&Pandas分组计算详解
3 浏览量
更新于2024-09-01
收藏 107KB PDF 举报
本文主要介绍了如何在Python的pandas库中进行分组计算,通过`groupby`函数实现数据的拆分、应用和合并,详细展示了对Series和DataFrame的分组计算方法,包括求平均值、计数以及迭代分组等操作。
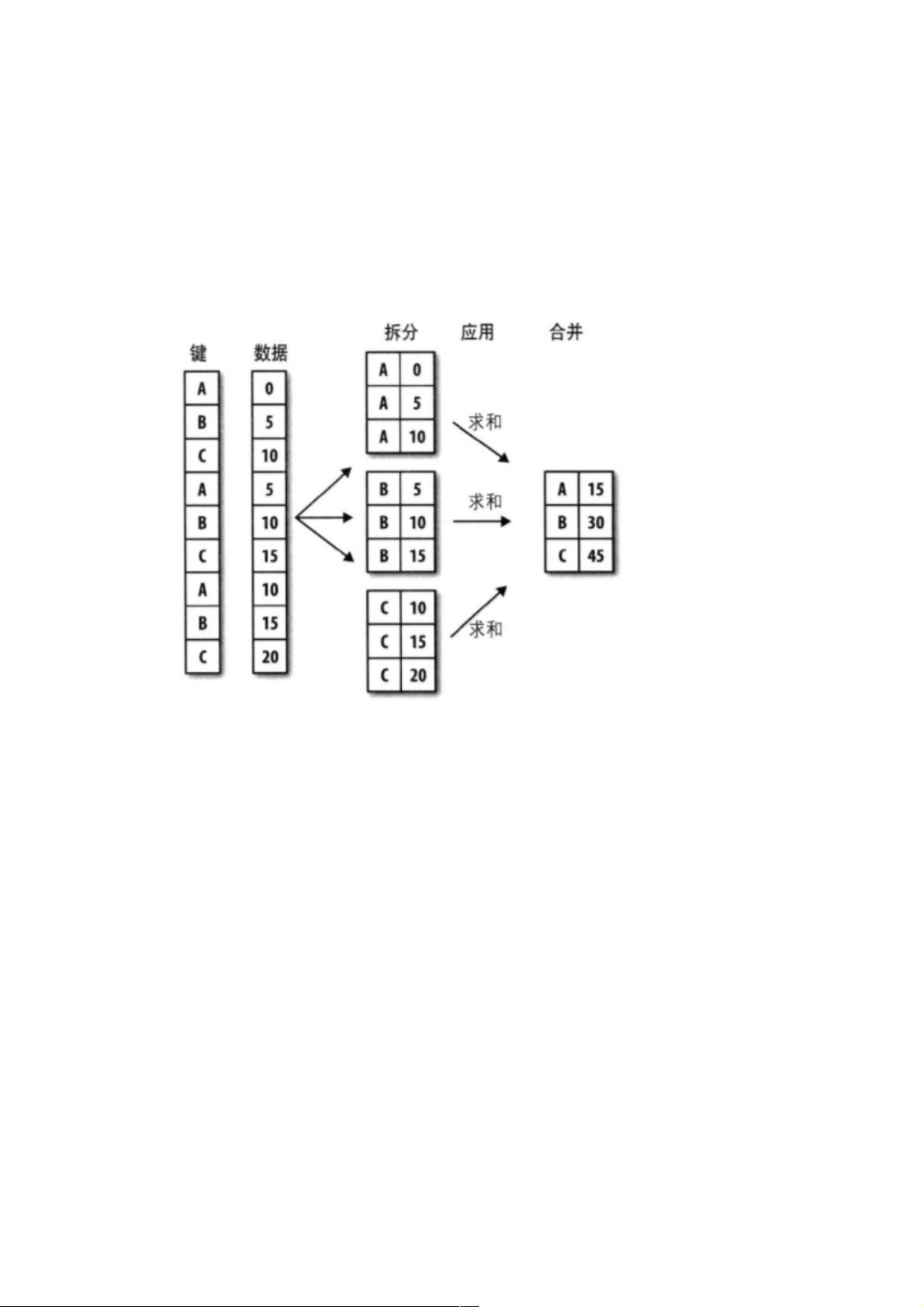
在pandas中,分组计算是一个重要的数据分析功能,它允许我们根据一个或多个列的值将数据分为不同的组,并对这些组分别执行统计计算。分组计算通常遵循三个步骤:
1. **拆分**:确定依据哪些列来进行分组。例如,在提供的代码中,`df.groupby('key1')`是基于`key1`列进行分组,而`df.groupby(['key1', 'key2'])`则是基于`key1`和`key2`两列进行分组。
2. **应用**:定义要在每个分组上执行的操作。如计算平均值、求和、计数等。例如,`grouped.mean()`计算了`data1`列在各个分组内的平均值。
3. **合并**:将所有分组的结果整合成一个新的数据结构,通常是DataFrame或Series。例如,`grouped.mean().unstack()`会将行索引和列索引交换,形成一个新的DataFrame。
在实际操作中,可以对Series进行分组,如:
```python
grouped = df['data1'].groupby(df['key1'])
```
这会根据`key1`的值将`data1`分组,然后可以执行各种聚合操作,如计算平均值:
```python
grouped.mean()
```
对于DataFrame,分组计算更为复杂,因为可以同时考虑多列进行分组,例如:
```python
df.groupby('key1').mean()
```
这会计算DataFrame中所有数值列在`key1`分组下的平均值。如果需要特定列的平均值,可以指定列名:
```python
df.groupby(['key1', 'key2'])['data1'].mean()
```
此外,还可以计算每个分组的元素个数:
```python
df.groupby(['key1', 'key2']).size()
```
通过迭代分组,可以遍历每个组并查看其内容:
```python
for name, group in df.groupby('key1'):
print(name)
print(group)
```
最后,分组结果也可以转换为字典形式,便于进一步处理:
```python
d = dict(list(df.groupby('key1')))
```
这些基本操作构成了pandas分组计算的核心,它们使得我们可以高效地对大型数据集进行复杂的数据分析。在实际的数据科学项目中,熟练掌握这些技巧是至关重要的。
Numpy&pandas(四)(四)–分组计算分组计算
import pandas as pd
import numpy as np
分组计算分组计算
分组计算三步曲:拆分 -> 应用 -> 合并
拆分:根据什么进行分组?
应用:每个分组进行什么样的计算?
合并:把每个分组的计算结果合并起来。
df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randint(1, 10, 5),
'data2': np.random.randint(1, 10, 5)})
对对Series进行分组进行分组
通过索引对齐关联起来
grouped = df['data1'].groupby(df['key1'])
#通过key1对data1进行分组
grouped.mean()
#对以上数据进行求平均值
df['data1'].groupby([df['key1'], df['key2']]).mean()
#先用key1进行分组(作为行第一索引),再用key2进行分组(行第二索引)然后再进行求平均值操作
对对DataFrame进行分组进行分组
df.groupby('key1').mean()
#只能对数值进行求平均值操作,不是数值的列自动消失
means = df.groupby(['key1', 'key2']).mean()['data1'] #先对两个data进行分组,求和然后单独拿出来data1
means.unstack()
#行第一索引和列第一索引调换位置
df.groupby(['key1', 'key2'])['data1'].mean()
#先分好组在拿出data1进行取平均值
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-20 上传
2020-12-22 上传
2020-12-22 上传
2022-05-24 上传
2021-01-07 上传
2020-10-16 上传









