深度学习驱动的人脸识别最新进展综述
人脸识别作为生物识别技术中的一个重要分支,近年来受益于深度学习的快速发展,其性能得到了显著提升并广泛应用于实际场景。本篇综述论文《DeepFaceRecognition: A Survey》由Mei Wang和Weihong Deng两位作者撰写,他们分别来自北京邮电大学信息与通信工程学院。论文旨在提供对深度学习在人脸识别(deep face recognition, deepFR)领域最新进展的全面概述。
论文首先阐述了深度学习如何通过多层处理网络来提取数据的多层次特征,这种新兴技术自2014年深度面部识别方法取得突破以来,就重塑了人脸识别研究的格局。深度FR技术利用层次结构将像素融合成不变的脸部表示,极大地提高了识别准确率,并推动了实际应用的成功。
作者在文中详细梳理了深度FR方法的快速演进历程。他们总结了各种网络架构的设计,这些架构包括但不限于卷积神经网络(Convolutional Neural Networks, CNN)、残差网络(Residual Networks, ResNets)、注意力机制(Attention Mechanisms)等,这些都在人脸特征提取和识别过程中发挥了关键作用。此外,论文还探讨了不同的损失函数,如softmax、中心损失(Center Loss)、对比性损失(Contrastive Loss)等,它们对于模型的学习和优化至关重要。
在脸部处理方法方面,文章将相关技术分为两大类:一是特征提取,如特征金字塔网络(Feature Pyramid Networks, FPN)、局部二值模式(Local Binary Patterns, LBP)等;二是人脸对齐与归一化,如Morphable Models、3D人脸重建等,这些技术确保了不同姿态和光照条件下的人脸都能被准确地识别。
论文接着讨论了数据库的发展,涵盖了公开的人脸识别基准数据集,如LFW、CelebA、VGGFace、MS-Celeb-1M等,以及随着大数据和云计算带来的新挑战和机遇。同时,作者分析了人脸识别协议和标准,如FaceNet的嵌入式特征、OpenFace的实时性优化,以及FR在安全验证、身份验证、监控系统和虚拟现实等多个应用场景中的应用实例。
这篇综述论文不仅深入剖析了深度学习在人脸识别领域的技术进步,还为研究人员和开发者提供了关于算法设计、数据管理和实际应用的实用指南,有助于推动该领域进一步发展和创新。
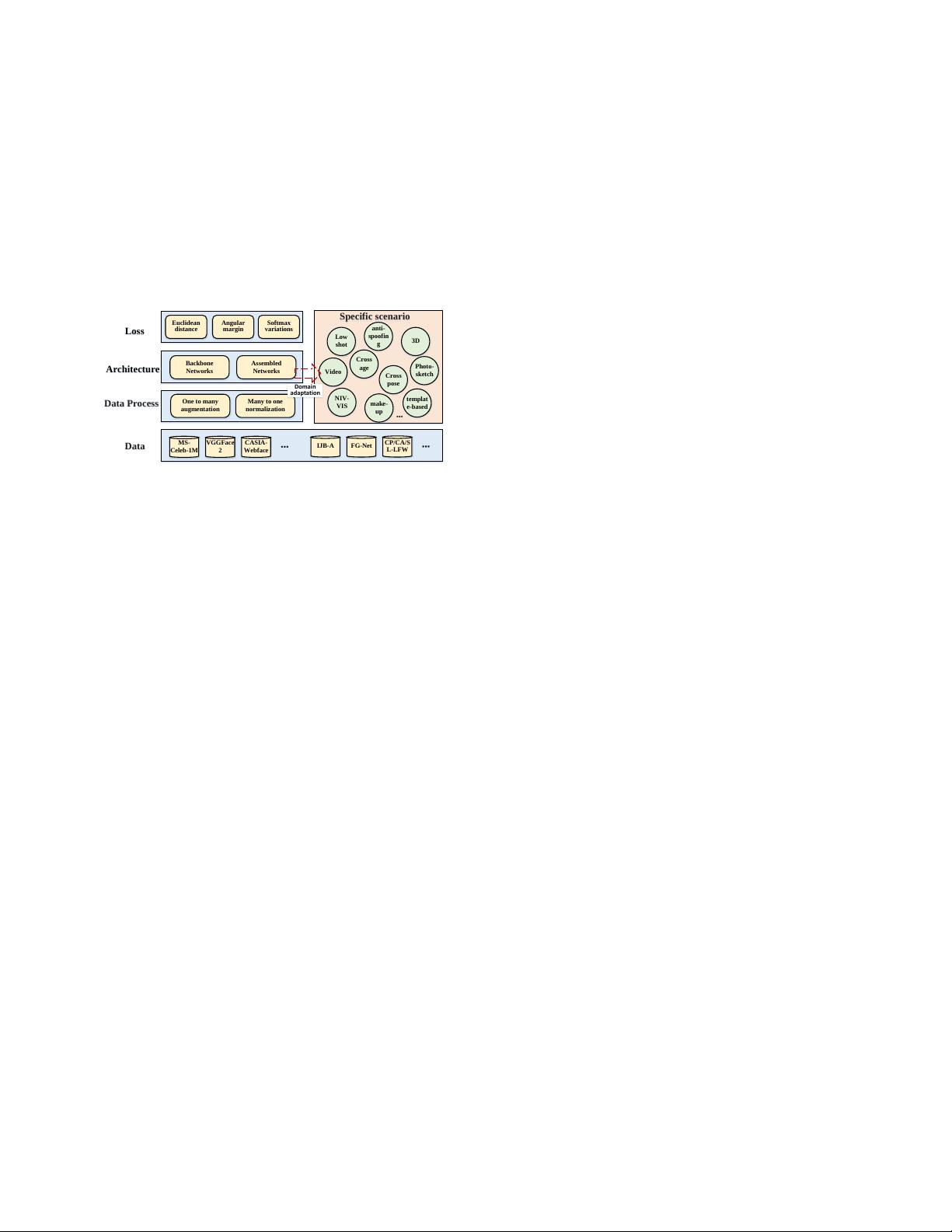
5
tions inherit from object classification and develop according
to unique characteristics of FR; face processing methods are
also designed to handle poses, expressions and occlusions
variations. With maturity of FR in general scenario, difficulty
levels are gradually increased and different solutions are driven
for specific scenarios that are closer to reality, such as cross-
pose FR, cross-age FR, video FR. In specific scenarios, more
difficult and realistic datasets are constructed to simulate
reality scenes; face processing methods, network architectures
and loss functions are also modified based on those of general
solutions.
Data
Data Process
Architecture
Loss
Euclidean
distance
Angular
margin
Softmax
variations
Backbone
Networks
Assembled
Networks
One to many
augmentation
Many to one
normalization
Video
3D
Low
shot
Photo-
sketch
…
anti-
spoofin
g
make-
up
Domain
adaptation
MS-
Celeb-1M
VGGFace
2
CASIA-
Webface
…
IJB-A FG-Net
CP/CA/S
L-LFW
…
NIV-
VIS
templat
e-based
Cross
age
Cross
pose
Specific scenario
Fig. 4. FR studies have begun with general scenario, then gradually increase
difficulty levels and drive different solutions for specific scenarios to get close
to reality, such as cross-pose FR, cross-age FR, video FR. In specific scenarios,
targeted training and testing database are constructed, and the algorithms, e.g.
face processing, architectures and loss functions are modified based on those
of general solutions.
III. NETWORK ARCHITECTURE AND TRAINING LOSS
As there are billions of human faces in the earth, real-
world FR can be regarded as an extremely fine-grained object
classification task. For most applications, it is difficult to
include the candidate faces during the training stage, which
makes FR become a “zero-shot” learning task. Fortunately,
since all human faces share a similar shape and texture, the
representation learned from a small proportion of faces can
generalize well to the rest. A straightforward way is to include
as many IDs as possible in the training set. For example,
Internet giants such as Facebook and Google have reported
their deep FR system trained by 10
6
− 10
7
IDs [176], [195].
Unfortunately, these personal datasets, as well as prerequisite
GPU clusters for distributed model training, are not accessible
for academic community. Currently, public available training
databases for academic research consist of only 10
3
−10
5
IDs.
Instead, academic community make effort to design effec-
tive loss functions and adopt deeper architectures to make deep
features more discriminative using the relatively small training
data sets. For instance, the accuracy of most popular LFW
benchmark has been boosted from 97% to above 99.8% in the
pasting four years, as enumerated in Table IV. In this section,
we survey the research efforts on different loss functions and
network architecture that have significantly improved deep FR
methods.
A. Evolution of Discriminative Loss Functions
Inheriting from the object classification network such as
AlexNet, the initial Deepface [195] and DeepID [191] adopted
cross-entropy based softmax loss for feature learning. After
that, people realized that the softmax loss is not sufficient by
itself to learn feature with large margin, and more researchers
began to explore discriminative loss functions for enhanced
generalization ability. This become the hottest research topic
for deep FR research, as illustrated in Fig. 5. Before 2017,
Euclidean-distance-based loss played an important role; In
2017, angular/cosine-margin-based loss as well as feature and
weight normalization became popular. It should be noted that,
although some loss functions share similar basic idea, the new
one is usually designed to facilitate the training procedure by
easier parameter or sample selection.
1) Euclidean-distance-based Loss : Euclidean-distance-
based loss is a metric learning method[230], [216] that embeds
images into Euclidean space and compresses intra-variance
and enlarges inter-variance. The contrastive loss and the triplet
loss are the commonly used loss functions. The contrastive loss
[222], [187], [188], [192], [243] requires face image pairs and
then pulls together positive pairs and pushes apart negative
pairs.
L =y
ij
max
0, kf(x
i
) − f (x
j
)k
2
−
+
+ (1 − y
ij
)max
0,
−
− kf(x
i
) − f (x
j
)k
2
(2)
where y
ij
= 1 means x
i
and x
j
are matching samples and
y
ij
= −1 means non-matching samples. f (·) is the feature
embedding,
+
and
−
control the margins of the matching and
non-matching pairs respectively. DeepID2 [222] combined the
face identification (softmax) and verification (contrastive loss)
supervisory signals to learn a discriminative representation,
and joint Bayesian (JB) was applied to obtain a robust embed-
ding space. Extending from DeepID2 [222], DeepID2+ [187]
increased the dimension of hidden representations and added
supervision to early convolutional layers, while DeepID3 [188]
further introduced VGGNet and GoogleNet to their work.
However, the main problem with the contrastive loss is that
the margin parameters are often difficult to choose.
Contrary to contrastive loss that considers the absolute
distances of the matching pairs and non-matching pairs, triplet
loss considers the relative difference of the distances between
them. Along with FaceNet [176] proposing by Google, Triplet
loss [176], [149], [171], [172], [124], [51] was introduced
into FR. It requires the face triplets, and then it minimizes
the distance between an anchor and a positive sample of the
same identity and maximizes the distance between the anchor
and a negative sample of a different identity. FaceNet made
kf(x
a
i
) − f (x
p
i
)k
2
2
+ α < − kf (x
a
i
) − f (x
n
i
)k
2
2
using hard
triplet face samples, where x
a
i
, x
p
i
and x
n
i
are the anchor,
positive and negative samples, respectively; α is a margin;
and f (·) represents a nonlinear transformation embedding
an image into a feature space. Inspired by FaceNet [176],
TPE [171] and TSE [172] learned a linear projection W to
construct triplet loss, where the former satisfied Eq. 3 and the
latter followed Eq. 4. Other methods combine triplet loss with
softmax loss [276], [124], [51], [40]. They first train networks
with the softmax and then fine-tune them with triplet loss.
(x
a
i
)
T
W
T
W x
p
i
+ α < (x
a
i
)
T
W
T
W x
n
i
(3)

剩余25页未读,继续阅读
331 浏览量
472 浏览量
234 浏览量
278 浏览量
831 浏览量
246 浏览量
2021-12-08 上传
358 浏览量

一片绿色
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
