Lucene原理与代码分析详解
"Lucene原理与代码分析完整版"
在深入探讨Lucene的原理与代码之前,我们首先要理解全文检索的基本概念。全文检索是一种在大量文本数据中快速查找相关信息的技术,而Lucene是Apache软件基金会的一个开放源代码项目,它是Java语言实现的全文搜索引擎库,广泛应用于各种搜索引擎和信息检索系统中。
全文检索的基本原理
1. 总论:全文检索的核心在于建立索引,索引使得我们可以快速定位到包含特定关键词的文档。索引构建时,会对原始文档进行分词,然后对分词结果进行处理,最后存储这些词及其在文档中的位置等信息。
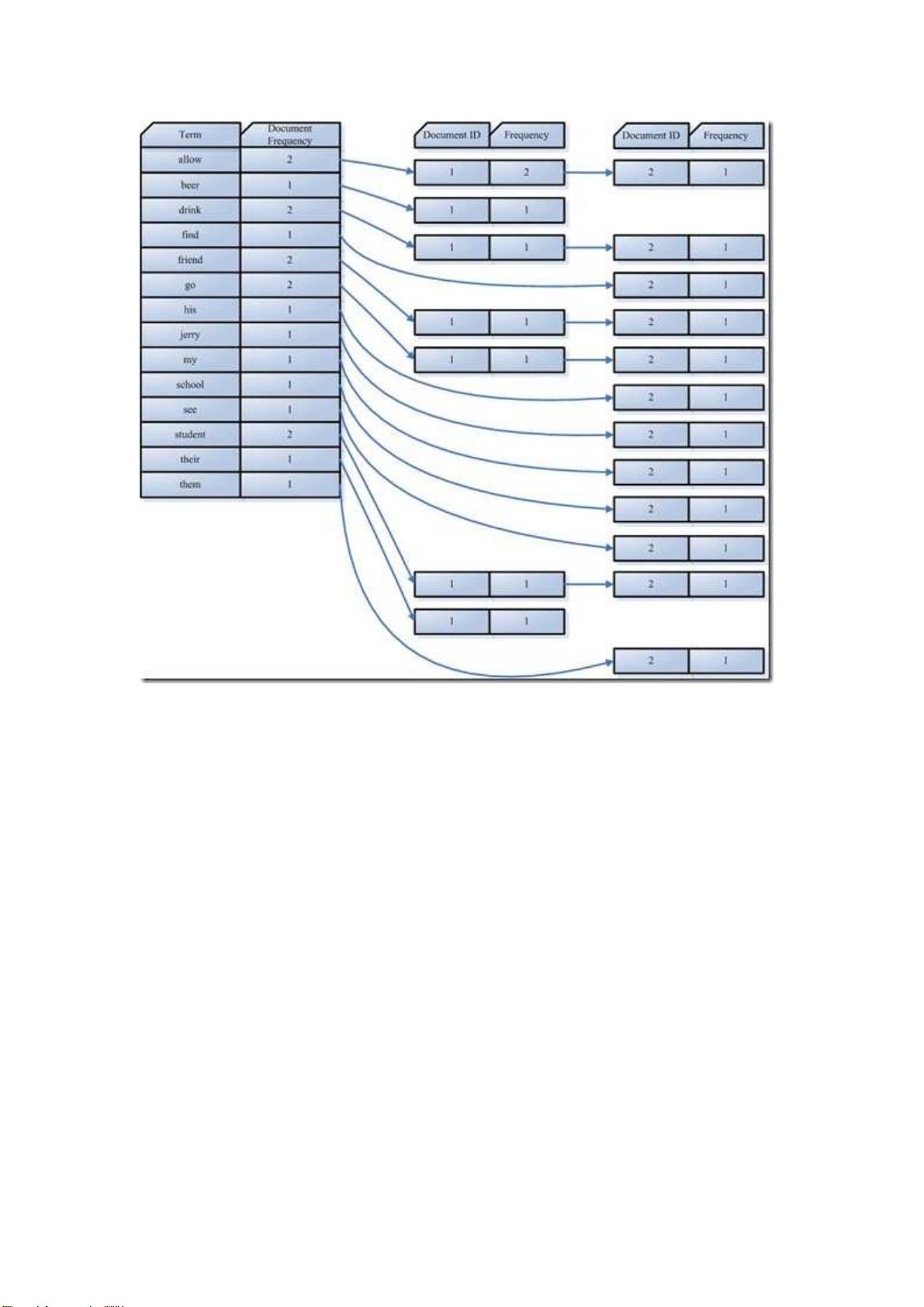
2. 索引里面存什么:索引主要包括两个部分——字典和文档倒排列表。字典中保存了所有独一无二的词元,而文档倒排列表记录了每个词元在哪些文档中出现过以及它们在文档中的位置。
3. 创建索引的步骤:
- 原始文档:要被索引的文本内容。
- 分词组件:将文档内容分割成独立的词元。
- 语言处理组件:针对不同语言进行词形还原、停用词处理等。
- 索引组件:创建字典,排序,合并相同的词元形成文档倒排列表。
索引搜索的步骤:
1. 用户输入查询:用户提交查询语句。
2. 查询处理:包括词法分析(识别单词和关键字)、语法分析(构造语法树)和语言处理(同索引过程中的处理)。
3. 搜索索引:根据查询语句的词元搜索文档倒排列表,找到匹配的文档。
4. 排序结果:计算每个文档与查询的相关性,使用向量空间模型(VSM)评估相关性,然后对结果进行排序。
Lucene的总体架构:
Lucene主要由以下几个关键组件组成:
- Analyzer:负责分词和语言处理。
- IndexWriter:构建索引。
- IndexReader:读取索引。
- IndexSearcher:执行查询和结果排序。
- Document和Field:表示要索引的数据结构。
- QueryParser:解析用户的查询语句。
Lucene的索引文件格式:
Lucene使用多种数据存储策略来优化磁盘空间和检索速度,如:
1. 前缀后缀规则:存储数值时,只存储变化的部分,减少存储空间。
2. 差值规则:连续数值存储它们的差值,减小文件大小。
3. 或然跟随规则:某些字段可能为空,采用特殊编码处理。
通过这些原理和代码分析,我们可以更深入地理解Lucene如何高效地处理全文检索,以及它在实际应用中的优化策略。对于开发者来说,了解这些内容有助于更好地利用Lucene构建自己的搜索系统。

16
到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,
“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索 drove,而 drive 也能被搜索出来。
第四步
第四步第四步
第四步:
::
:将得到的词
将得到的词将得到的词
将得到的词(Term)传给索引组件
传给索引组件传给索引组件
传给索引组件(Indexer)。
。。
。
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词
利用得到的词利用得到的词
利用得到的词(Term)创建一个字典
创建一个字典创建一个字典
创建一个字典。
。。
。
在我们的例子中字典如下:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2



剩余526页未读,继续阅读
2021-09-18 上传
2011-07-28 上传
2012-11-04 上传
点击了解资源详情
2018-04-19 上传
2024-11-11 上传
2024-11-11 上传
2024-11-11 上传

snsunny
- 粉丝: 2
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
