NVMe中断与轮询:I/O延迟优化
需积分: 13 158 浏览量
更新于2024-07-16
收藏 3.76MB PDF 举报
"这篇文档是Damien LeMoal在2017年Linux Storage and Filesystems Conference(Vault会议)上的演讲稿,主题是利用NVMe轮询技术优化I/O延迟。主要内容涵盖了I/O模型的比较,Linux内核中的实现,评估结果以及结论与未来方向。"
在这篇演讲中,Damien LeMoal探讨了两种不同的I/O模型:基于中断请求(IRQ)和轮询(polling)的方法。传统的基于IRQ的I/O模型中,设备生成中断来异步通知驱动器命令完成,这通常涉及设备驱动程序、中断处理程序以及VFS(虚拟文件系统)和BIO(块I/O)堆栈。用户进程发起系统调用如read或write后,会进入等待状态,直到中断处理程序通过VFS和BIO栈传递完成信号。
相反,轮询I/O模型中,驱动程序会定期检查设备状态,而不是等待中断。NVMe(非易失性内存 express)设备的引入使得轮询成为可能,因为它们提供了更低的延迟和更高的带宽,这使得轮询模式在某些情况下比基于IRQ的模型更具优势,尤其是在优化I/O延迟方面。
Linux内核的实现部分,LeMoal讨论了如何在块层和NVMe驱动中实现轮询模式。他可能详细解释了如何将轮询机制集成到现有的内核结构中,以及这种改变对性能和效率的影响。
评估结果显示,经典轮询与混合轮询的对比中,混合轮询可能表现出更好的性能。此外,他还研究了进程调度对I/O性能的影响,以及与用户级驱动程序的比较。这可能涉及到如何在系统负载变化时调整轮询策略,以适应不同的工作负载和系统资源需求。
演讲的结论部分,LeMoal可能概述了轮询I/O模型在NVMe环境中的潜力,以及未来的研究和开发方向。这可能包括改进轮询算法以减少开销,优化调度策略,或者探索新的硬件特性以进一步提高I/O效率。
这篇演讲深入探讨了NVMe设备上轮询技术如何优化I/O延迟,为Linux存储和文件系统的开发者提供了有价值的洞见,并为未来的系统优化指明了道路。
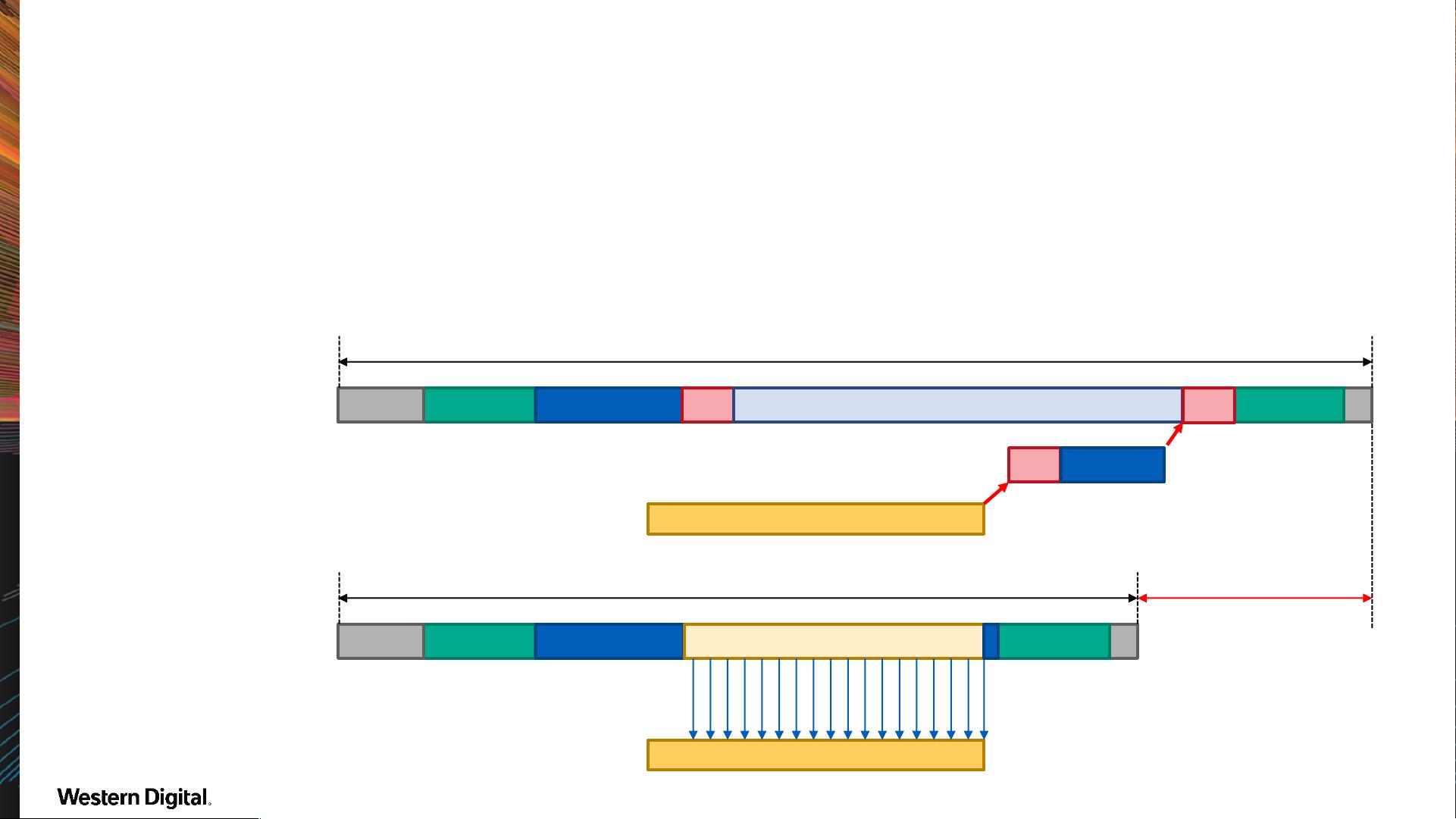
IRQ vs Polling
• Polling can remove context switch (CS) overhead from I/O path
– And more: IRQ delivery delay, IRQ handler scheduling, ...
– But CPU spin-waits for the command completion: higher CPU load
Trade-off CPU load for lower I/O latency
3/21/17 5©2017 Western Digital Corporation or its affiliates. All rights reserved.
Command execution
BIO stacksyscall Device driver CS
CS
Sleep BIO stack
ISR
IRQ
Wake
Application perceived I/O latency
Command execution
BIO stacksyscall Device driver Are you done ?
BIO stack
Application perceived I/O latency
Gain
IRQ
Polling
CS
剩余24页未读,继续阅读
2020-09-16 上传
2022-07-15 上传
2019-08-15 上传
2019-06-16 上传
2024-09-27 上传
2020-05-11 上传

yiyeguzhou100
- 粉丝: 472
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
