
Model-Agnostic
1.PDP
Partial Dependence Plot
[Annals of Statistics 2001]Greedy function approximation: A gradient boosting machine.
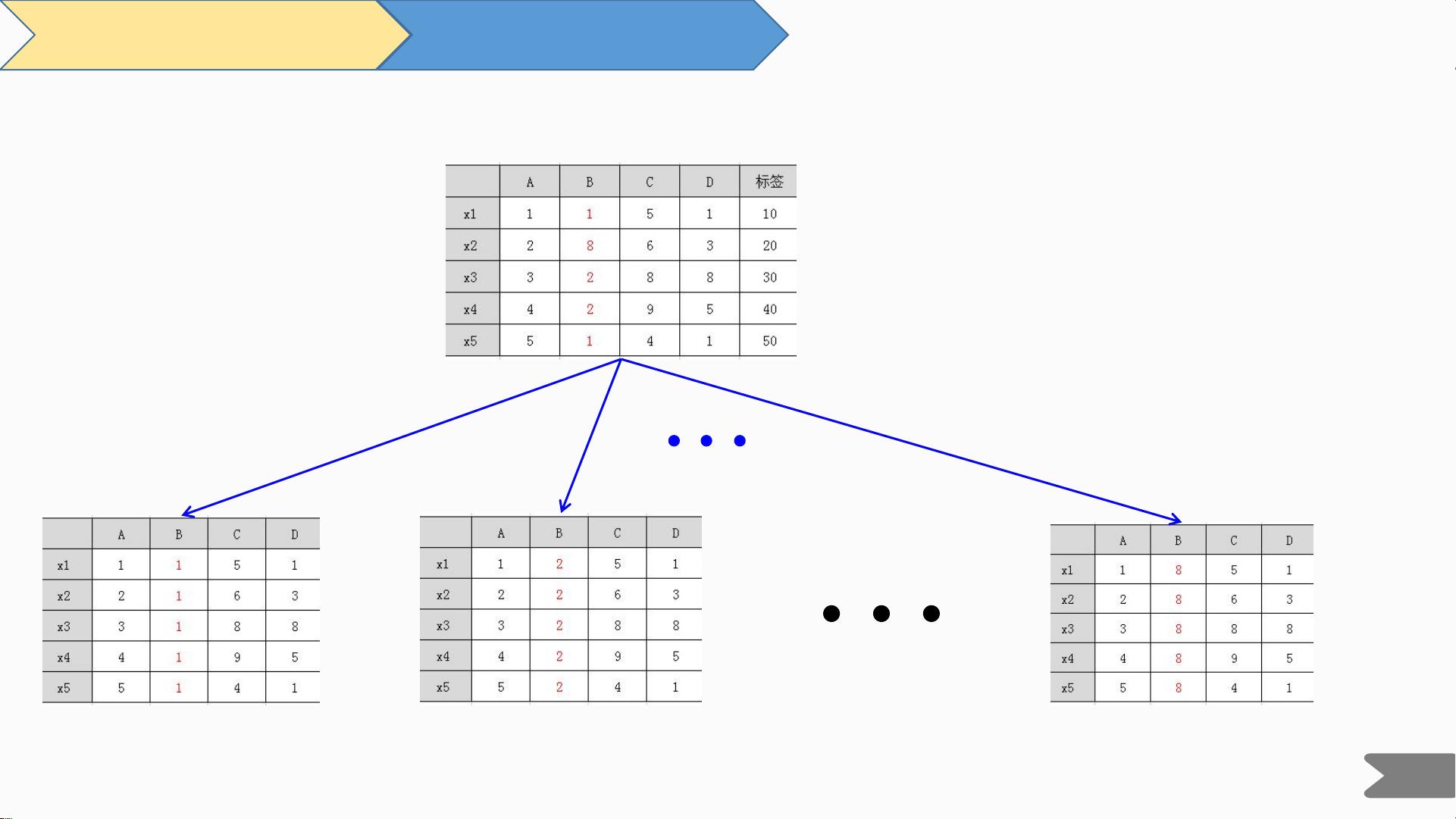
PDP原理简示图
7
剩余34页未读,继续阅读

November丶Chopin
- 粉丝: 2w+
- 资源: 3
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 保险服务门店新年工作计划PPT.pptx
- 车辆安全工作计划PPT.pptx
- ipqc工作总结PPT.pptx
- 车间员工上半年工作总结PPT.pptx
- 保险公司员工的工作总结PPT.pptx
- 报价工作总结PPT.pptx
- 冲压车间实习工作总结PPT.pptx
- ktv周工作总结PPT.pptx
- 保育院总务工作计划PPT.pptx
- xx年度现代教育技术工作总结PPT.pptx
- 出纳的年终总结PPT.pptx
- 贝贝班班级工作计划PPT.pptx
- 变电值班员技术个人工作总结PPT.pptx
- 大学生读书活动策划书PPT.pptx
- 财务出纳月工作总结PPT.pptx
- 大学生“三支一扶”服务期满工作总结(2)PPT.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


