华为Streaming技术:实时流处理与架构解析
版权申诉
77 浏览量
更新于2024-07-17
收藏 1.34MB PPTX 举报
“华为大数据认证课程聚焦于Streaming分布式流计算引擎,涵盖了实时流处理技术,包括Streaming的基本概念、系统架构、关键特性和CQL语言。该认证旨在帮助学习者理解和掌握实时数据流处理的核心原理和应用。”
在华为的大数据认证课程中,Streaming是一个重要的组成部分,它是一种基于开源Storm的分布式、实时计算框架。学员通过学习,可以达到以下目标:
1. **实时流处理概念**:理解实时数据流处理的概念,即对持续不断的数据流进行即时分析和计算,以应对快速变化的业务需求。
2. **Streaming系统架构**:掌握Streaming的三层结构——Topology、Nimbus、Supervisor和Worker。Topology是运行的实时应用程序,Nimbus负责资源管理和任务调度,Supervisor接收Nimbus的任务并管理Worker进程,而Worker是Topology运行的实际执行单元,每个Worker是一个独立的JVM进程。
3. **关键特性**:Streaming具备实时响应(低延迟)、数据不存储(计算优先)、连续查询和事件驱动等特性。这些特性使得Streaming适合处理高并发、低延迟的实时数据处理场景。
4. **CQL基本概念**:学习StreamCQL,这是Streaming中的查询语言,用于定义和执行实时流数据的处理逻辑。
5. **应用场景**:Streaming被广泛应用于实时分析(如日志分析、交通流量监测)、实时统计(网站访问统计、排序)和实时推荐(广告定位、事件营销)等业务场景。
6. **在FusionInsight中的位置**:Streaming位于FusionInsight架构中,作为一个实时分布式计算框架,与其他组件如Hive、HDFS、HBase、Spark、PorterMiner、DataFarm等共同构建大数据生态系统。
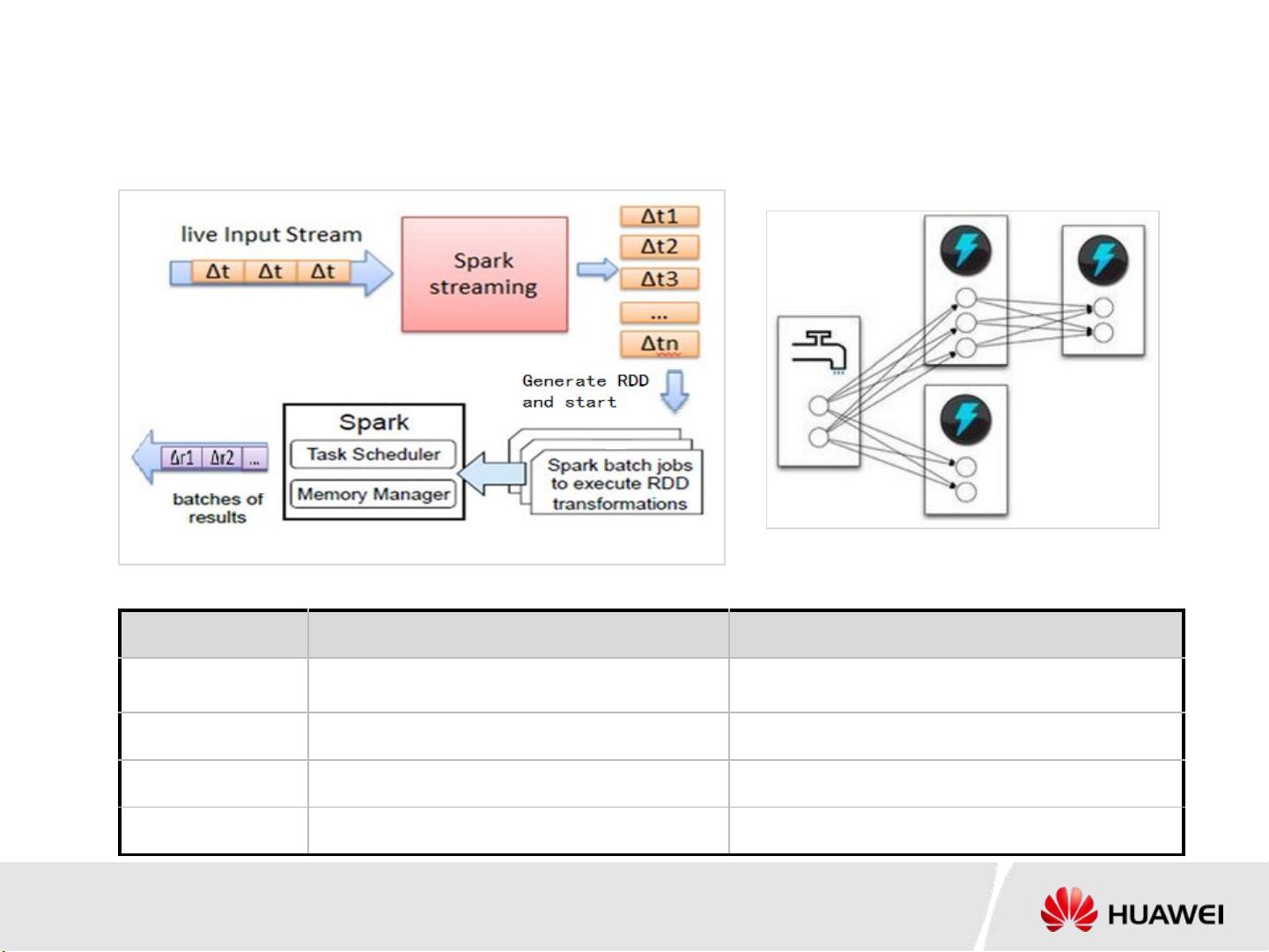
7. **与SparkStreaming的比较**:相比SparkStreaming的微批处理,Streaming在响应时间上具有优势,通常为毫秒级,适合对响应时间有严格要求的场景,而SparkStreaming更适合对响应时间要求不那么高的秒级场景。
通过以上知识点的学习,学员能够深入理解华为大数据平台中Streaming的角色和功能,以及如何利用其特性解决实际业务问题,提升大数据实时处理能力。

第 *页
版权所有 华为技术有限公
司
在 + , 中的位
置
是一个实时的分布式的实时计算框架,在实时业务中有广泛的应用。
-,.
-+/-0
1/%
23
4
1
+
-&2
+"3
系统管理
+
服务治理
1
-&2!4,
4"!4,
52!4,/6
应用服务层
%7/#14/8 "
,9
6"&
: &
;!%#/<62
安全管理
=!
剩余31页未读,继续阅读
135 浏览量
276 浏览量
4363 浏览量
213 浏览量
199 浏览量
209 浏览量
2024-10-31 上传
251 浏览量
238 浏览量

啊明之道
- 粉丝: 1
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- coppa-web-demo:学士学位论文的网络实现演示,可以是私人交流
- reactjs-sample
- 易语言超级列表框与文本文件同步
- cyrus-lin.github.io
- induction-of-decision-tree-demo:通过node.js发现最佳决策树的算法
- NeSpeak:NeSpeak - 单声道语音合成
- Publisher
- The Pirate Bay torrent search-crx插件
- pfc_g5:Projeto Final de Curso | 联电| 卡洛斯,莱昂纳多,佩德罗|
- 易语言超级列表框API选中
- 集成:HACS为您提供了功能强大的UI来处理所有自定义需求的下载
- MFCPCL_MFC_vsmfcpcl_vs2015_pcl1.8.1_显示
- interplanetary-tracker
- coffee_shop:带有颤振的咖啡厅用户界面
- 易语言超级列表单列追加数据
- NOI信奥赛资料(2019 2020)整理.zip
