PDF结构详解:从实例看文件组成与解析
需积分: 10 50 浏览量
更新于2024-09-16
收藏 131KB DOC 举报
PDF结构分析深入探讨了Adobe PDF文件的四个关键组成部分:对象、文件(物理结构)、文档结构以及内容流。首先,对象是PDF的基础,它由一系列基本的数据类型构成,这些对象定义了文档的构成单元。每个PDF文档都是由这些对象按特定规则组织而成的。
文件(物理结构)关注的是这些对象在PDF文件中的存储方式,包括它们的位置、访问路径和可能的更新机制。这层结构与对象的语义内容无关,而是关注于文件的实际存储逻辑。
文档结构部分阐述了如何将对象组织成更具体的元素,如页面、字体、注释等,这些都是构成PDF文档内容的基石。例如,一个PDF文档可能会包含多个页面,每一页都由特定的布局元素组成,字体用来呈现文本,批注则用于添加用户的评论。
内容流是PDF文件的核心,它是一系列指令,负责描述页面的视觉呈现和图形实体的外观,比如线条、形状和文字排版等。理解内容流对于解析PDF文档至关重要,因为它控制着读者看到的实际内容。
在阅读PDF文件的初期,理解这些概念可能比较抽象,特别是对于那些不熟悉其他文件格式如HTML和XML的人来说。HTML是文本格式,适合浏览器解析并呈现结构化的网页,而XML主要用于数据交换,通常需要额外的XSD(XML Schema Definition)来指导解析。相比之下,PDF是二进制格式,直接存储视觉和布局信息,阅读和解析更为复杂。
学习PDF结构时,可以从已知的HTML或XML基础知识入手,因为它们之间存在相似性,如关键字、标记和数据。理解了这些基础后,再通过一个简单的PDF文件实例,逐步掌握其语法、解析规则和流程,这将有助于更好地把握PDF文件的内在结构和功能。
通过实际操作和案例研究,你可以逐渐掌握PDF文件的组成原理,如如何创建、编辑和查看PDF,以及在编程或处理文档时如何有效地操作PDF内容。记住,学习过程虽然起初可能有挑战,但通过实践和理解,你会发现PDF的世界既严谨又富有灵活性。
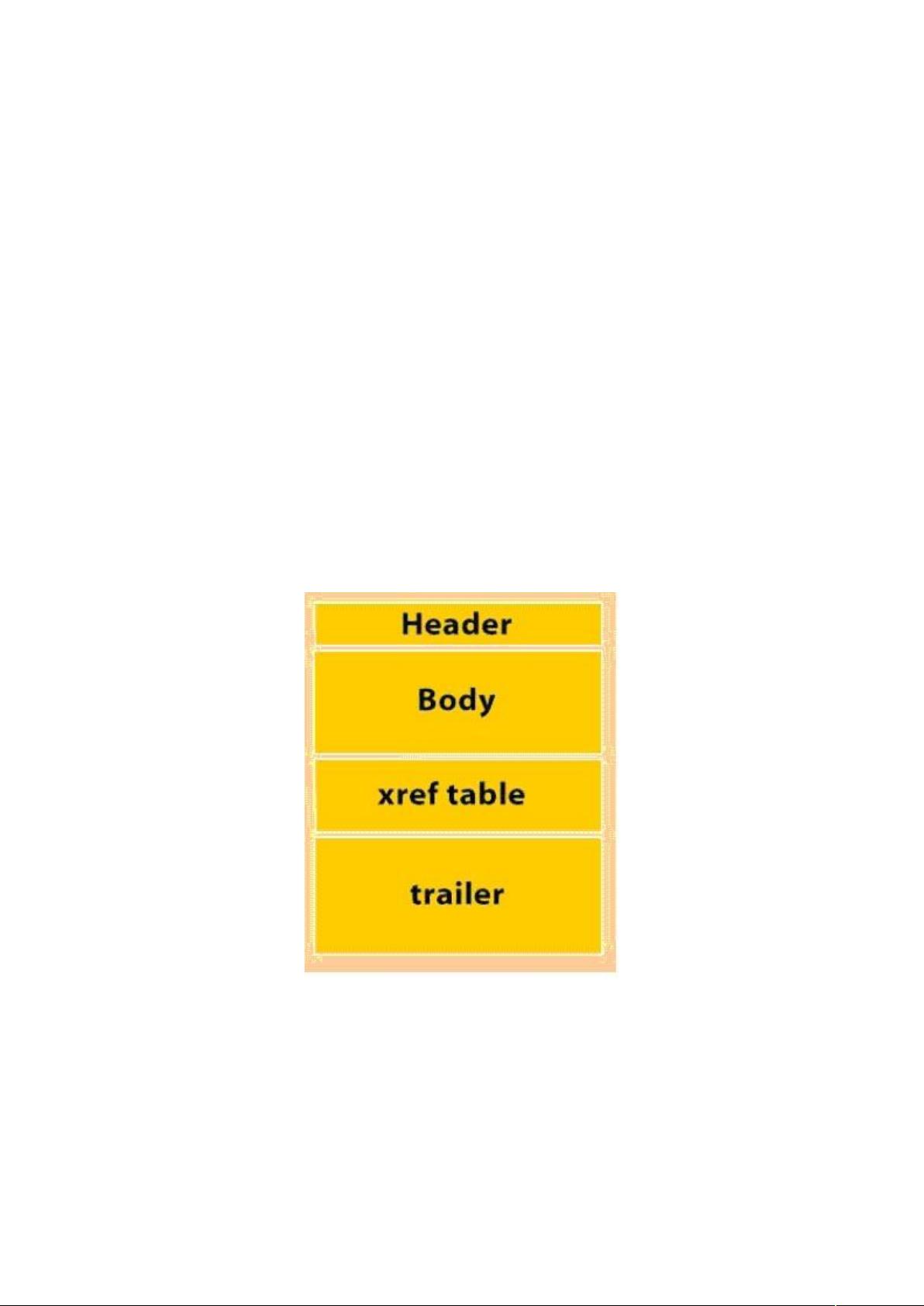
3.PDF 文件的基本组成:
一个 PDF 文件从大的方面来说分 4 个部分:
l 文件头,指明了该文件所遵从的 PDF 规范的版本号,它出现在 PDF 文
件的第一行。
l 文件体,PDF 文件的主要部分,由一系列对象组成。
l 交叉引用表,为了能对间接对象进行随机存取而设立的一个间接对象的
地址索引表。
l 文件尾,声明了交叉引用表的地址,即指明了文件体的根对象
(Catalog),从而能够找到 PDF 文件中各个对象体的位置,达到随机访问。
另外还保存了 PDF 文件的加密等安全信息(以后详细讨论)。
如下图:
图 1
4.PDF 文档的逻
辑结构
作为一种结构化
的文件格式,一个
PDF 文档是由一些
称为“对象”的模块组
成的。并且每个对
象都有数字标号,
这样的话可以这些
对象就可以北其他的对象所引用。这些对象不需要按照顺序出现在 PDF 文档里
面,出现的顺序可以是任意的,比如一个 PDF 文件有 3 页,第 3 页可以出现在
第一页以前,对象按照顺序出现唯一的好处就是能够增加文件的可读性,如果
你不会用文本编辑器来阅读 PDF 结构,那么大可不必关心。正是因为页与页之
间的不相关性,就可以对 PDF 文件的页码进行随机的访问。
剩余10页未读,继续阅读
2011-01-22 上传
2023-10-17 上传
2023-11-05 上传
2023-09-17 上传
2023-08-13 上传
2023-08-27 上传
2023-08-03 上传
2023-10-31 上传

laoyes
- 粉丝: 175
- 资源: 57
 我的内容管理
展开
我的内容管理
展开







最新资源
- ASP.NET数据库高级操作:SQLHelper与数据源控件
- Windows98/2000驱动程序开发指南
- FreeMarker入门到精通教程
- 1800mm冷轧机板形控制性能仿真分析
- 经验模式分解:非平稳信号处理的新突破
- Spring框架3.0官方参考文档:依赖注入与核心模块解析
- 电阻器与电位器详解:类型、命名与应用
- Office技巧大揭秘:Word、Excel、PPT高效操作
- TCS3200D: 可编程色彩光频转换器解析
- 基于TCS230的精准便携式调色仪系统设计详解
- WiMAX与LTE:谁将引领移动宽带互联网?
- SAS-2.1规范草案:串行连接SCSI技术标准
- C#编程学习:手机电子书TXT版
- SQL全效操作指南:数据、控制与程序化
- 单片机复位电路设计与电源干扰处理
- CS5460A单相功率电能芯片:原理、应用与精度分析
