Hadoop云上实践:存储与计算分离的优势与挑战
"Hadoop存储与计算分离实践,主要探讨了在传统集群和云上集群部署中Hadoop的挑战与解决方案,特别提到了阿里云E-MapReduce团队在Hadoop+OSS结合上的实践和优化。"
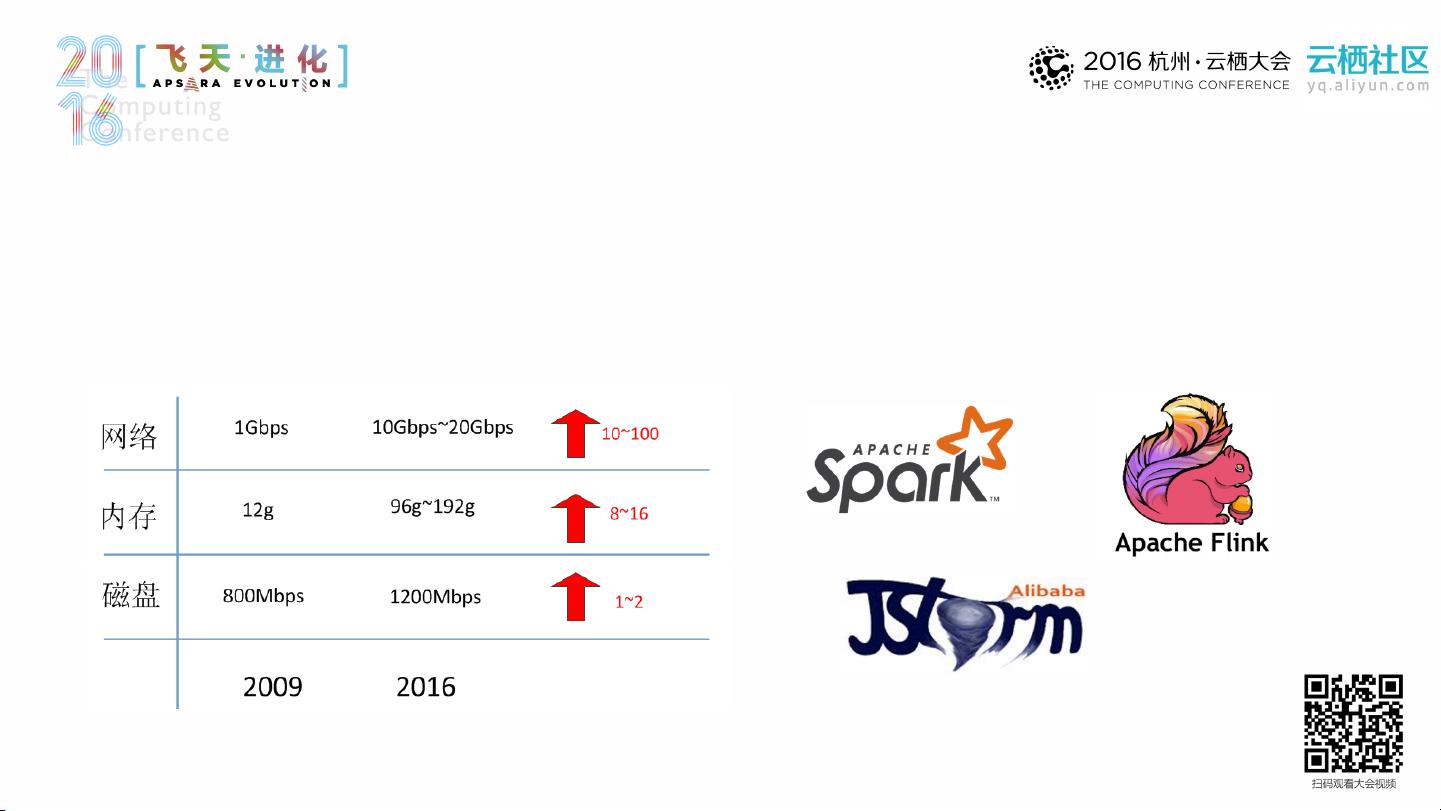
在传统的Hadoop集群部署中,计算能力和存储能力是紧密绑定的,这种模式下,数据的本地磁盘访问速度远超网络传输,但这也导致了任务处理时数据获取的高开销,即“计算找数据”。集群混部是为了减少数据迁移,提高资源利用率,然而现实中,随着带宽不再成为瓶颈,磁盘的角色在计算中逐渐减弱。集群的木桶效应和资源浪费问题凸显,尤其是在面临DataLocality(数据本地性)和远程数据的抉择时,混部模式的劣势也暴露出来,如资源浪费和集群扩展性的降低。
随着云计算的发展,阿里云E-MapReduce团队提出了一种云上集群部署实践。云计算基础设施如ECS、SLS、VPC等提供了丰富的存储、计算和中间件支持,使得Hadoop集群可以实现一键部署,快速启动和使用。然而,云上部署也带来了新的挑战:存储成本相对较高,热数据逐渐冷却,冷数据不断积累,导致存储质量和平衡代价上升,以及磁盘存储费用和数据服务可用性要求高等问题。
为应对这些挑战,阿里云团队提出了Hadoop+OSS(对象存储服务)的分离部署方案。OSS作为存储层,通过内网高速传输与ECS上的Hadoop进行通信,降低了存储成本并提高了数据服务可用性。Hadoop对OSS的支持也在不断演进,EMR-Core的各个版本逐步优化了性能、安全性以及对小文件和数仓场景的支持,如通过MetaService提供更好的管理和易用性,针对OSS的读写进行优化以提高稳定性与性能。
针对文件移动操作的重量级特点,Hadoop执行过程中涉及大量文件移动,EMR-Core的改进显著提升了效率,减少了不必要的性能损耗。这样的优化策略确保了在存储与计算分离架构下,Hadoop依然能够高效地处理大数据任务,同时利用云存储的优势降低成本和提升服务质量。
总结而言,"Hadoop存储与计算分离实践"着重讨论了传统Hadoop集群的局限性,展示了云上部署的便利性与挑战,并提出了Hadoop与阿里云OSS结合的创新解决方案,以适应不断变化的大数据处理需求。

n 理想
更少的数据迁移
更高的资源利用率
剩余36页未读,继续阅读
2022-09-23 上传
2021-12-04 上传
点击了解资源详情
123 浏览量
点击了解资源详情
点击了解资源详情

dick1305
- 粉丝: 6
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- 不看后悔的人事管理系统论文
- jmeter测试流程
- 图书管理系统_概要规划说明书
- 图书管理系统_软件开发设计书
- iBATIS 入门指南
- 很不错的java面试宝典
- C#函数方法集(汇总c#.net常用函数和方法集)
- Servlet_JSP
- 硬件必读硬件必读\硬件必读\硬件必读\
- Apache+ActiveMQ教程.pdf下载
- plsql21天自学通
- A Novel Invisible Color ImageWatermarking Scheme using Image Adaptive Watermark Creation and Robust Insertion-Extraction
- BerkeleyDB
- MapInfo Professional操作指南(pdf)
- 软件需求变更管理七步法
- 计算机软件测试面试题
