聚类算法详解:K-Means与DBSCAN
版权申诉
“聚类算法讲解--.pdf”
在机器学习领域,聚类是一种无监督学习方法,用于将数据集中的对象根据它们的相似性或差异性分成不同的组,即所谓的簇。聚类算法无需预先知道数据的类别标签,而是通过分析数据的内在结构来寻找自然的分组。
K-MEANS算法是聚类算法中最常见的一种。它的基本思想是通过迭代找到K个质心,每个质心代表一个簇的中心。首先,我们需要指定簇的数量K。然后,根据欧几里得距离或余弦相似度等距离度量方法,将每个数据点分配给最近的质心所在的簇。质心是簇中所有点的均值。算法的工作流程包括初始化质心、重新分配数据点到最近的质心、更新质心,直至质心不再显著移动或达到预设的迭代次数。K-MEANS算法简单快速,适用于常规形状的数据集,但其缺点是K值难以确定,且对于非凸或不规则形状的簇识别能力较弱。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它能发现任意形状的簇并有效处理噪声点。DBSCAN的核心概念是核心对象,即在设定的半径r(称为ϵ-邻域)内包含至少minPts个点的点。如果两个点之间可以通过核心对象的密度可达路径连接,那么它们被认为是密度相连的。反之,那些不能被任何核心对象密度可达的点被视为噪声点。边界点是属于某个簇但不是核心对象的点。DBSCAN的参数包括半径ϵ和最小点数MinPts,前者可以通过K距离来设定,后者一般选取较小的值。参数的选择对聚类结果有显著影响。DBSCAN的优势在于能够处理非凸形状的簇,但参数调整可能较为复杂。
为了更好地理解和评估聚类效果,可以使用可视化工具,例如链接中提到的两个资源,它们可以帮助直观地展示DBSCAN算法的聚类过程和结果。通过可视化,我们可以更清晰地看到不同簇的分布以及噪声点的分布情况,从而进一步优化聚类算法的参数设置。
聚类算法是数据分析中的重要工具,K-MEANS和DBSCAN是两种常见的方法,各有特点和适用场景。理解这些算法的基本原理和参数设置,对于数据挖掘和模式识别具有重要的实践价值。
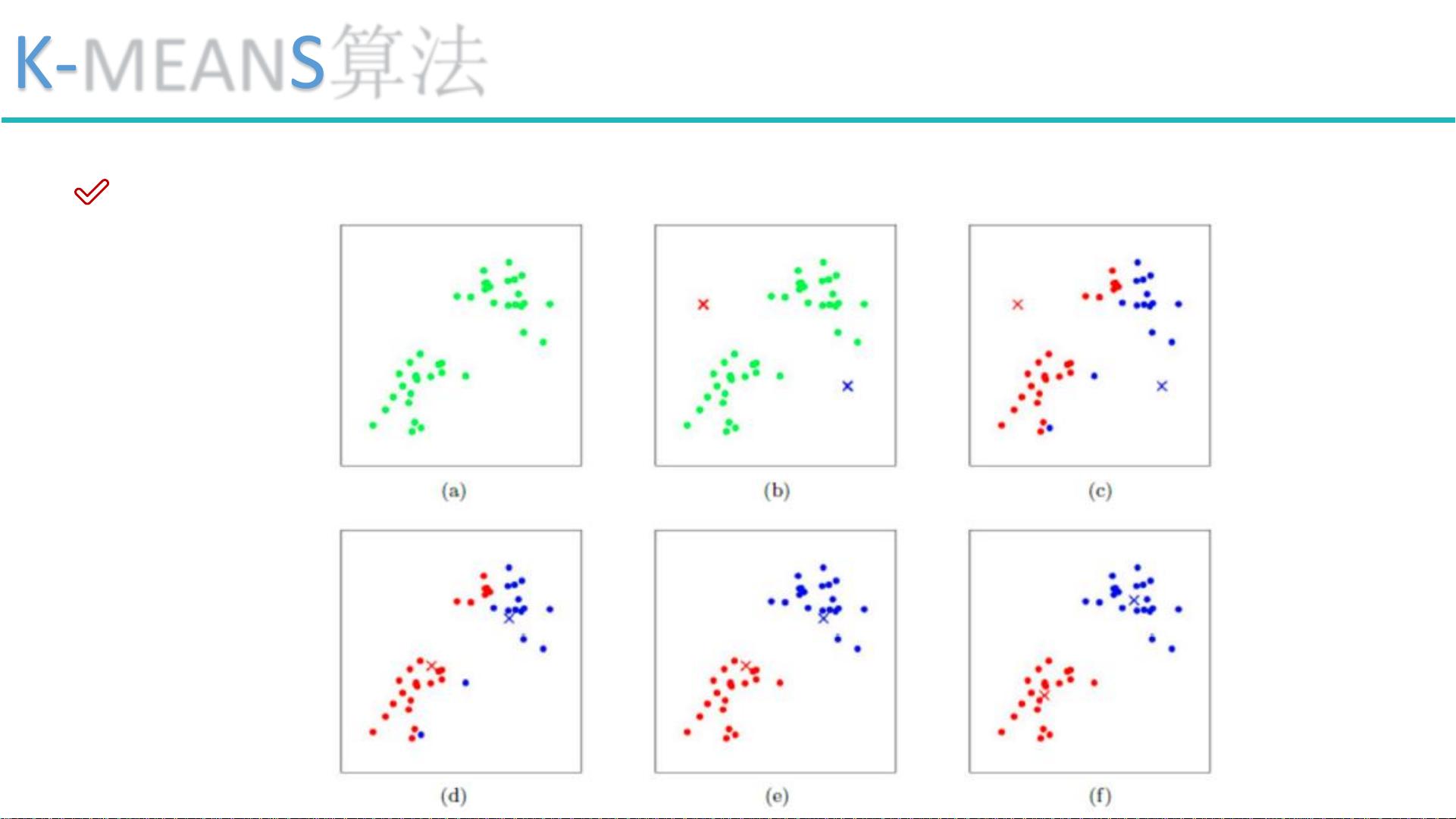
K-MEANS算法
工作流程:
剩余10页未读,继续阅读
2023-03-07 上传
2022-04-15 上传
2024-07-02 上传
2024-07-02 上传
2024-07-02 上传
2024-06-19 上传
2021-10-09 上传
2021-10-09 上传
2024-08-16 上传

卷积神经网络
- 粉丝: 364
- 资源: 8440
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
