随机森林模式识别系统设计与实现代码详解
需积分: 7 29 浏览量
更新于2024-08-04
收藏 154KB DOC 举报
该文档主要介绍了基于随机森林模式识别系统的详细设计与实现过程。以下是主要内容的深入解析:
1. 决策树与随机森林概念:
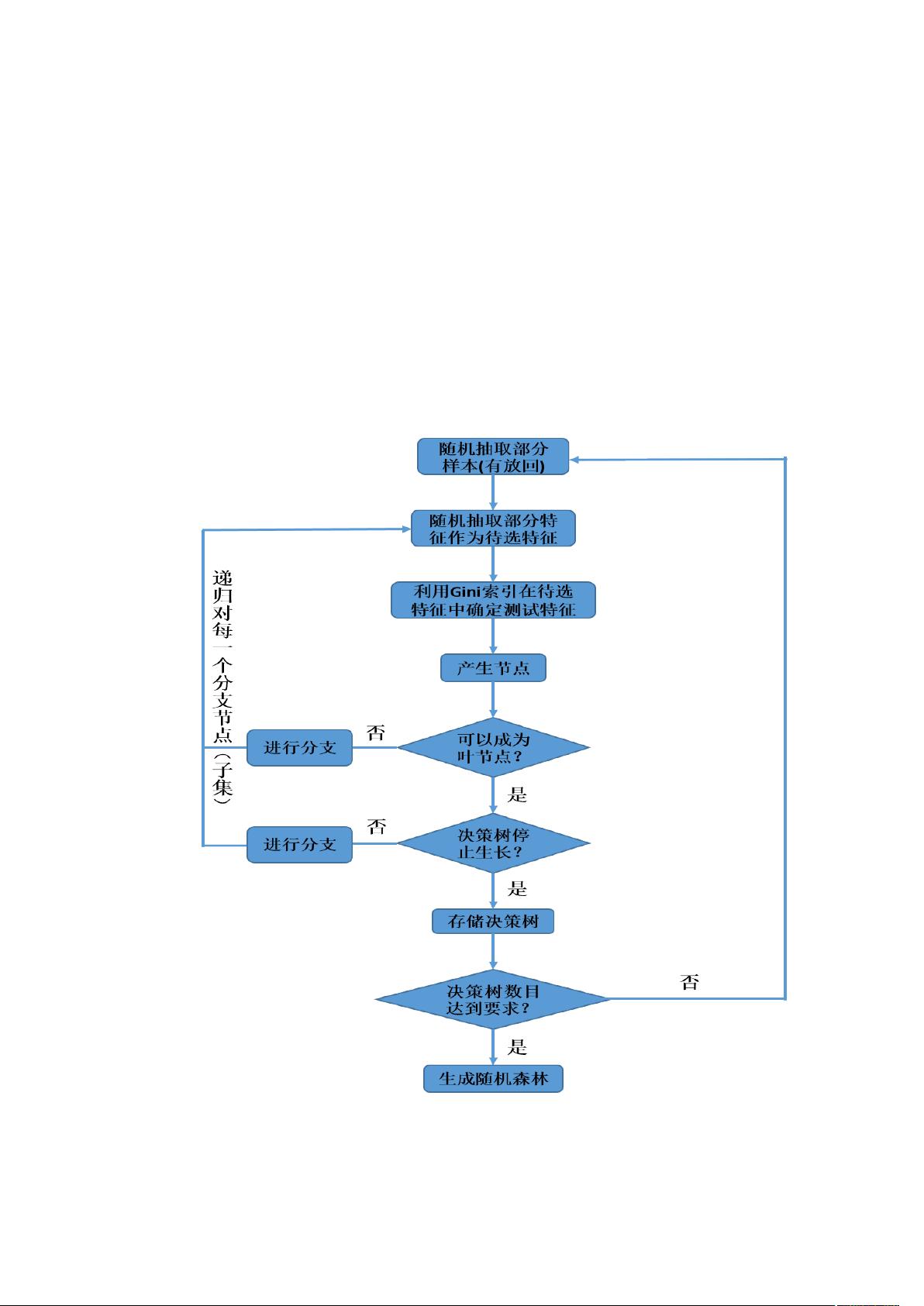
随机森林是一种集成学习方法,它由众多决策树组成。决策树是一种基本的分类和回归模型,通过数据特征递归地将数据集分割成更纯的子集。随机森林通过随机选取数据样本(bagging)和特征(feature bagging)的方式,降低了过拟合的风险,提高了模型的稳定性和准确性。
2. 算法原理与流程:
随机森林工作流程包括:首先,从原始数据集中随机选择一部分样本(bootstrap样本)和特征;其次,为每棵决策树训练一个模型,每个模型基于不同的子集;最后,所有决策树对新数据进行预测,通过投票机制得出最终分类结果。这种策略可以减少单个决策树的偏差,提高整体预测性能。
3. 系统环境:
实现这个系统需要在PC电脑端硬件环境下,使用MATLAB这样的编程语言进行开发。MATLAB提供了丰富的数据分析和机器学习工具箱,便于实现随机森林算法。
4. 数据集与特征提取:
数据集包含汽车的各种属性,用于评估车辆质量。特征提取过程采用随机森林中的C4.5算法,通过信息增益率来选择最优特征,每个决策树在训练过程中只使用部分特征,增强了模型的多样性。
5. 分类过程:
采用有放回和无放回抽样的方式,对数据进行多次处理,每次选取不同特征进行训练。信息增益被用来决定节点分裂,形成具有高预测能力的决策树。最后,所有决策树的预测结果汇总并投票决定最终分类。
6. 主要程序代码:
文档提供了一个简化的主程序代码示例,使用MATLAB的clearall命令清空内存,为后续代码执行做准备。具体的随机森林实现会涉及数据预处理、训练决策树、构建随机森林以及评估模型性能等步骤。
通过阅读这份文档,读者可以了解到如何运用随机森林算法进行模式识别,包括如何选择特征、创建决策树、以及如何通过集成多个决策树来提升模型的性能。同时,实际操作代码的展示使得开发者能够直接将其应用到实际项目中,提高工作效率。
基于随机森林模式识别系统的设计与实现
1.1 题目的主要研究内容(宋体四号加粗左对齐)
(1)决策树、随机森林的概念,数据和待选特征的随机选取。随机森林算
法分类器的原理和算法流程。利用现有的公开数据集实现分类器,并利用分类投
票对分类结果进行分析评判。(宋体小四号不加粗 1.5 倍行距)
(2)系统流程图
1.2 题目研究的工作基础或实验条件
(1)硬件环境:PC 电脑端
下载后可阅读完整内容,剩余8页未读,立即下载
2022-10-19 上传
2022-11-24 上传
2024-03-18 上传
2024-05-02 上传
2020-05-11 上传
2021-10-07 上传
2023-06-30 上传
2023-09-12 上传
2023-07-12 上传

李逍遥敲代码
- 粉丝: 2995
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







