宜信数据一致性与实时抽取:日志与Kafka驱动的解决方案
160 浏览量
更新于2024-08-28
收藏 1.06MB PDF 举报
在互联网金融企业宜信,数据一致性与实时性是至关重要的。传统的数据抽取方式,如DBA在业务低峰期开放备库,虽然解决了数据一致性的问题,但时效性较差,往往导致数据延迟,且存在冲突和重复抽取的问题。为解决这些问题,宜信引入了LinkedIn的做法,利用日志和消息队列Kafka来构建更高效的数据基础设施。
首先,日志被设计为所有系统操作的基础,记录每一笔数据的变更。这样,数据不再依赖于周期性的抽取,而是通过实时的、异步的方式传播。Kafka作为关键的消息传递系统,提供了高吞吐量和可靠性,使得数据使用者能够即时订阅并处理最新的日志事件,从而达到数据一致性与实时性的双重保障。
具体应用中,不同的数据使用方可以根据自身需求选择不同的数据存储方式。例如,大数据分析团队可以将数据存储到Hive或Spark表中便于查询;搜索引擎则可能选择Elasticsearch或HBase;缓存服务可能用Redis或Alluxio来存储日志,提供快速访问;而那些需要同步的用户可以直接将数据写入自己的数据库,确保数据同步。
相较于Sqoop等定期抽取方式,基于日志和Kafka的方法避免了侵入式开发和性能损耗,以及双写带来的复杂性。它允许系统以最小的修改和干扰来适应变化,提高了整体数据管理的灵活性和效率。通过这样的设计,宜信成功地实现了数据的一致性和实时性,显著提升了数据驱动决策的能力和用户体验。
图片来自:https://github.com/alibaba/canal
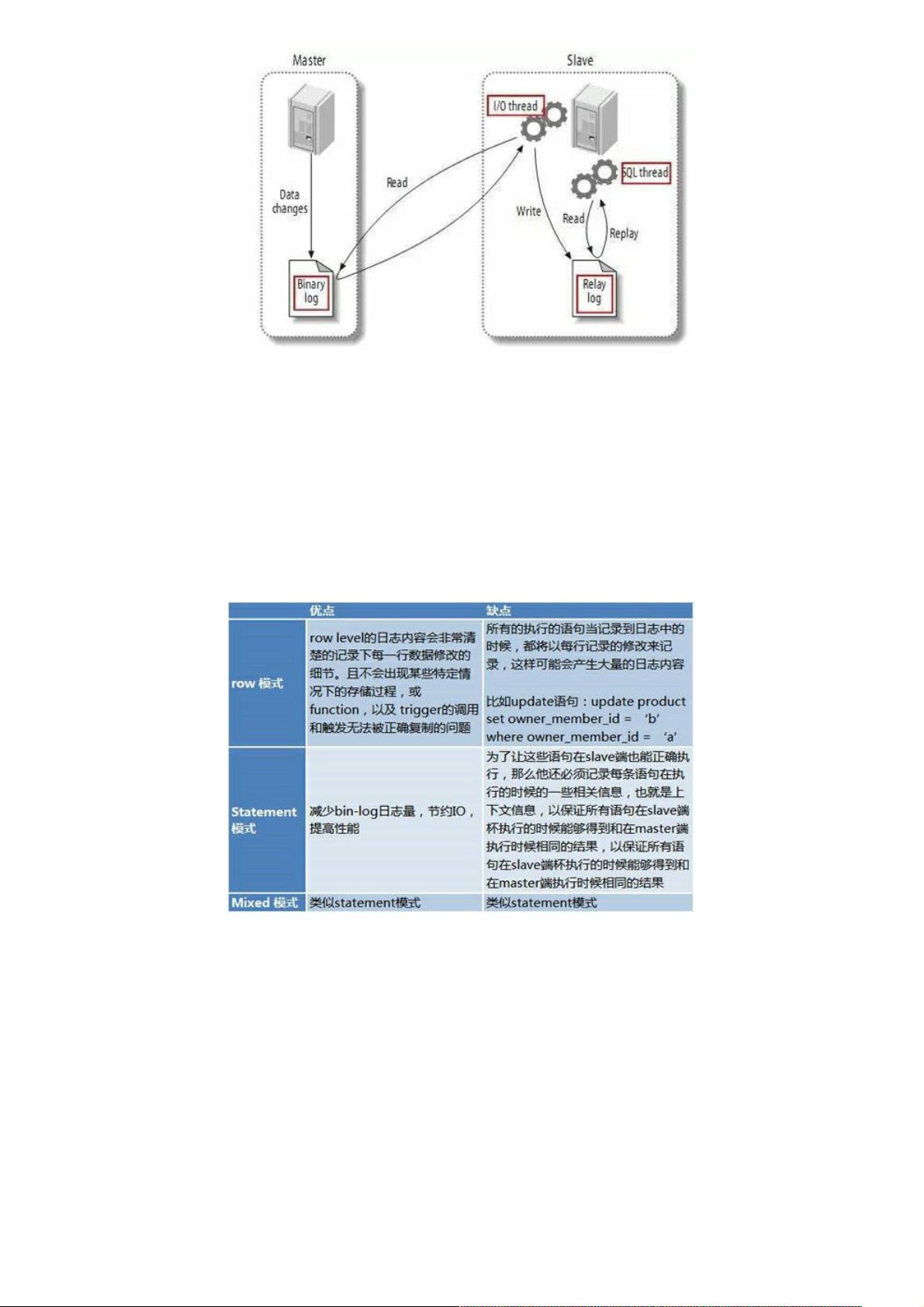
而binlog有三种模式:
Row 模式:日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。
Statement 模式: 每一条会修改数据的sql都会记录到 master的bin-log中。slave在复制的时候SQL进程会解析成和原来master
端执行过的相同的SQL来再次执行。
Mixed模式: MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一
种。
他们各自的优缺点如下:
此处来自:http://www.jquerycn.cn/a_13625
由于statement 模式的缺点,在与我们的DBA沟通过程中了解到,实际生产过程中都使用row 模式进行复制。这使得读取全量
日志成为可能。
通常我们的MySQL布局是采用 2个master主库(vip)+ 1个slave从库 + 1个backup容灾库 的解决方案,由于容灾库通常是用于异
地容灾,实时性不高也不便于部署。
为了最小化对源端产生影响,显然我们读取binlog日志应该从slave从库读取。
读取binlog的方案比较多,github上不少,参考https://github.com/search?utf8=%E2%9C%93&q=binlog。最终我们选用了阿
里的canal做位日志抽取方。
Canal最早被用于阿里中美机房同步, canal原理相对比较简单:
1.Canal模拟MySQL Slave的交互协议,伪装自己为MySQL Slave,向MySQL Slave发送dump协议
2.MySQL master收到dump请求,开始推送binary log给Slave(也就是canal)
3.Canal解析binary log对象(原始为byte流)
剩余11页未读,继续阅读
728 浏览量
2010-11-23 上传
2010-06-06 上传
2023-06-06 上传
2022-07-11 上传
2024-01-01 上传
2023-07-27 上传
点击了解资源详情
点击了解资源详情

weixin_38623366
- 粉丝: 4
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
