深度学习后端架构与应用场景详解:分布式计算框架与实时/离线处理
版权申诉
87 浏览量
更新于2024-06-21
收藏 3.56MB PDF 举报
本章节深入探讨了深度学习在实际应用中的后端架构选型与场景。首先,它阐述了为何在深度学习项目中需要采用分布式计算,这是因为随着数据量的爆炸性增长和模型复杂性的提高,单机处理已无法满足需求。分布式计算通过将计算任务分解到多台机器上,提高了训练速度和模型扩展性。
章节列举了多个流行的深度学习分布式计算框架,包括:
1. PaddlePaddle:中国自主研发的开源深度学习框架,支持高效的模型训练和部署。
2. Deeplearning4j:由Apache软件基金会支持的Java库,专为大规模机器学习设计。
3. Mahout:Apache的开源机器学习库,也可用于深度学习任务。
4. SparkMLlib:Apache Spark的机器学习库,提供了深度学习工具。
5. Ray:一个灵活的、开源的分布式系统库,适用于训练复杂的神经网络模型。
6. Sparkstream:Spark的实时流处理模块,可用于实时深度学习应用。
7. Horovod:Google开源的深度学习加速器,通过数据并行和模型并行优化训练。
8. BigDL:由华为开源的分布式深度学习框架,专注于大数据和边缘计算环境。
9. Petastorm:Apache的高效数据处理框架,与深度学习集成,提高数据读取效率。
10. TensorFlowOnSpark:将TensorFlow与Spark结合,扩展深度学习在大数据上的能力。
实时计算部分介绍了实时流计算的概念,以及数据采集、预处理、模型构建等步骤。而离线计算则关注数据的批量处理,包括ETL(提取、转换、加载)和工作流调度。
在设计人工智能应用,特别是人机交互系统时,章节详细讨论了问答引擎算法架构、长难句处理、错误纠正、指代消解、语义匹配、相似向量搜索、话术澄清、排序打分和系统效果评估。此外,个性化推荐系统的设计也是一大焦点,包括推荐引擎架构、召回模块、排序模块、用户画像、GBDT粗排、在线FM精排等算法,以及评价体系和案例分析。
整个章节不仅涵盖了深度学习技术的底层原理,还涉及到了如何将其应用于实际场景,帮助读者理解和选择合适的后端架构,以及如何优化和评估深度学习项目的性能和效果。

DeepLearning
务,任务执⾏的时间也可能长短不⼀,执⾏过程有些可能要求同步,也有些可能更适合异步。
另⼀⽅⾯,整个任务流程的DAG图也可能是动态变化的,系统往往可能需要根据前⼀个环节的结果,调整下⼀个环节的
⾏为参数或者流程。这种调整,可能是⽬标系统的需要(⽐如在⾃动驾驶过程中遇到⾏⼈了,那么我们可能需要模拟计算刹
车的距离来判断该采取的⾏动是刹车还是拐弯,⽽平时可能不需要这个环节),也可能是增强学习特定训练算法的需要(⽐
如根据多个并⾏训练的模型的当前收益,调整模型超参数,替换模型等等)。
此外,由于所涉及到的⽬标系统可能是具体的,现实物理世界中的系统,所以对时效性也可能是有强要求的。举个例
⼦,⽐如你想要实现的系统是⽤来控制机器⼈⾏⾛,或者是⽤来打视频游戏的。那么整个闭环反馈流程就需要在特定的时间
限制内完成(⽐如毫秒级别)。
总结来说,就是增强学习的场景,对分布式计算框架的任务调度延迟,吞吐量和动态修改DAG图的能⼒都可能有很⾼的
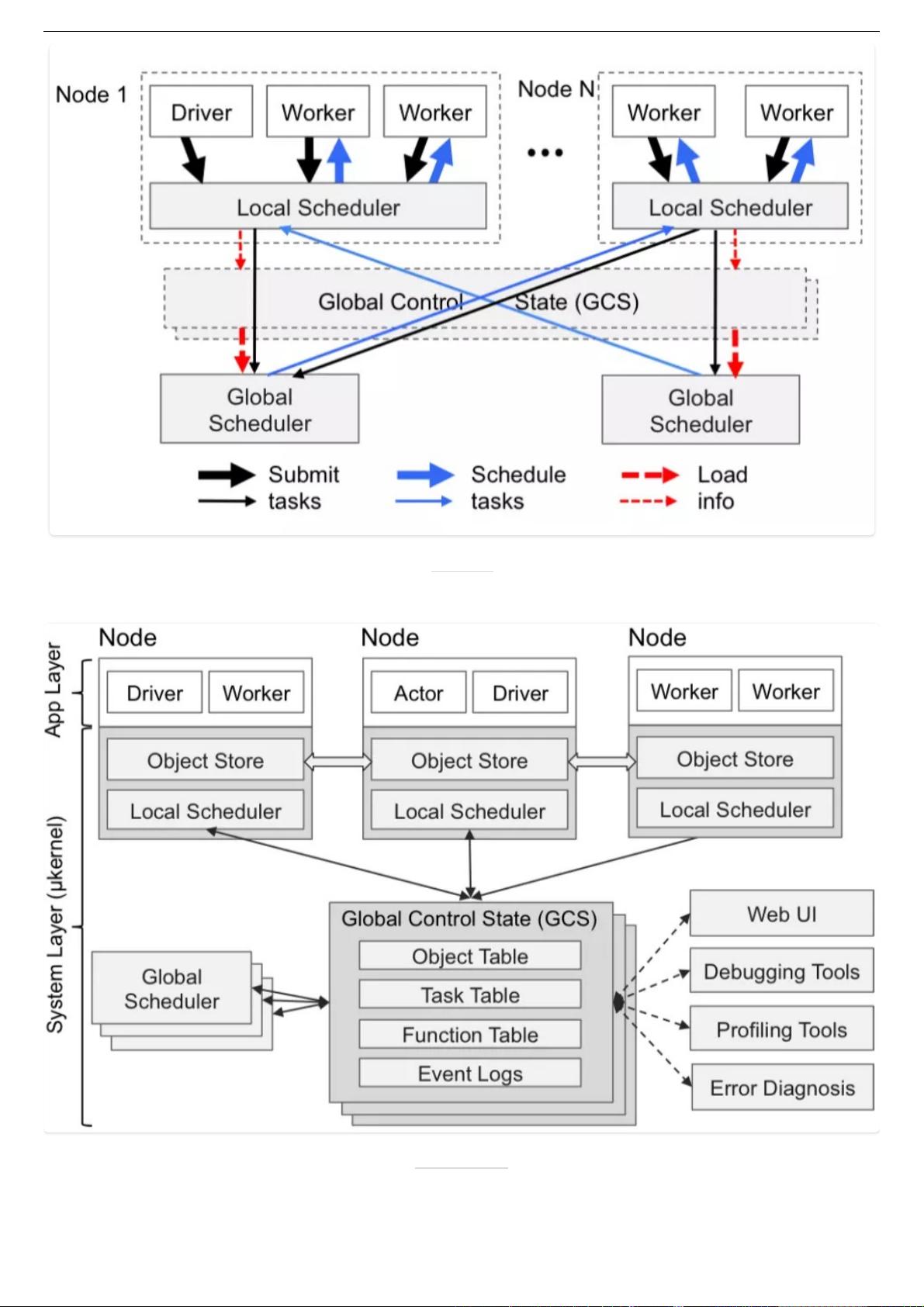
要求。按照官⽅的设计⽬标,Ray需要⽀持异构计算任务,动态计算链路,毫秒级别延迟和每秒调度百万级别任务的能⼒。
Ray的⽬标问题,主要是在类似增强学习这样的场景中所遇到的⼯程问题。那么增强学习的场景和普通的机器学习,深
度学习的场景⼜有什么不同呢?简单来说,就是对整个处理链路流程的时效性和灵活性有更⾼的要求。
Ray框架优点:
海量任务调度能⼒
毫秒级别的延迟
异构任务的⽀持
任务拓扑图动态修改的能⼒
Ray没有采⽤中⼼任务调度的⽅案,⽽是采⽤了类似层级(hierarchy)调度的⽅案,除了⼀个全局的中⼼调度服务节点
(实际上这个中⼼调度节点也是可以⽔平拓展的),任务的调度也可以在具体的执⾏任务的⼯作节点上,由本地调度服务来
管理和执⾏。
与传统的层级调度⽅案,⾄上⽽下分配调度任务的⽅式不同的是,Ray采⽤了⾄下⽽上的调度策略。也就是说,任务调度的发
起,并不是先提交给全局的中⼼调度器统筹规划以后再分发给次级调度器的。⽽是由任务执⾏节点直接提交给本地的调度
器,本地的调度器如果能满⾜该任务的调度需求就直接完成调度请求,在⽆法满⾜的情况下,才会提交给全局调度器,由全
局调度器协调转发给有能⼒满⾜需求的另外⼀个节点上的本地调度器去调度执⾏。
架构设计⼀⽅⾯减少了跨节点的RPC开销,另⼀⽅⾯也能规避中⼼节点的瓶颈问题。当然缺点也不是没有,由于缺乏全
局的任务视图,⽆法进⾏全局规划,因此任务的拓扑逻辑结构也就未必是最优的了。
第⼗⼋章 后端架构选型及应⽤场景
7/53
剩余55页未读,继续阅读

安全方案
- 粉丝: 2538
- 资源: 3960
 我的内容管理
展开
我的内容管理
展开







最新资源
- dc-portfolio-site
- liteBox-开源
- c10lp_refkit_zephyr:在C10LP RefKit FPGA板上的litex vexriscv内核上运行的演示Zephyr应用程序
- Tasky
- UpGuard Cyber Security Ratings-crx插件
- 算法:基本算法和数据结构实现
- JQuerygantt,jquery甘特图
- 参考资料-基于RS485和单片机的排队机控制系统设计.zip
- JRDropMenu:JRDropMenu可快速实现下拉菜单功能
- 源代码深度学习入门:基于Python的理论与实现
- HUPROG:一个包含HUPROG'17(Hacettepe大学编程竞赛)的问题和该问题的解决方案的回购
- Spotify-Data:扩展下载Spotify数据时提供的基本流历史记录数据
- 编码方式
- simple.rar_按钮控件_Borland_C++_
- lua-table:具有超能力的lua表
- bitwarden-menubar:macOS菜单栏中的Bitwarden
