Spark RDD:内存计算与容错机制解析
需积分: 32 33 浏览量
更新于2024-07-18
2
收藏 1.44MB PDF 举报
"SparkRDD论文中文版主要探讨了Resilient Distributed Datasets (RDD)的概念,这是一种用于大规模集群计算的容错内存计算模型。RDDs的设计目标是解决现有框架在处理迭代算法和交互式数据挖掘时效率低下的问题,通过保持数据在内存中,显著提升了性能。RDDs提供了一种粗粒度转换的共享内存模型,以实现高效的容错机制。论文还分析了RDDs能够表达多种计算类型,不仅包括类似Pregel的迭代计算模型,还支持其他现有模型无法表达的计算。
1: 介绍部分提到,尽管MapReduce和Dryad等分布式计算框架在大数据分析中广泛应用,但它们缺乏对分布式内存的有效抽象。这导致在处理需要复用中间结果的迭代计算时效率低下,尤其是在机器学习和图计算中。
2: RDD抽象部分详细阐述了RDD的核心特性,即它是不可变的、分区的记录集合,具有血统信息,允许快速恢复丢失的数据。Spark编程接口允许用户创建和操作RDD,通过一系列高级操作实现并行计算。
2.2.1 例子–监控日志数据挖掘展示了如何使用Spark的RDD API来处理和分析监控日志数据,体现了RDDs在实际应用中的灵活性。
2.3 RDD模型的优势在于其高效的容错能力,以及在内存计算中带来的性能提升,特别是对于迭代算法和交互式任务。
3.1 Spark中RDD的操作介绍了RDD支持的各种操作类型,如转换(transformations)和行动(actions),转换不会立即执行,而是在需要时通过血统信息计算。
3.2.1 线性回归和3.2.2 PageRank的实例展示了RDDs如何应用于机器学习和图计算任务。
4: 表达RDDs部分深入讨论了RDDs如何表达各种计算模式,证明了其广泛适用性。
5: 实现部分详细描述了Spark的内部机制,包括作业调度、解释器集成、内存管理和检查点支持,这些都是实现高效、容错的RDD计算的关键。
6: 评估部分通过不同应用场景(如迭代式机器学习、PageRank计算)和容错测试,展示了RDDs在性能和容错方面的优势。
7: 讨论部分比较了RDDs与其他编程模型,并讨论了RDDs在调试中的帮助。
8: 相关工作部分回顾了与RDDs相关的研究,指出RDDs的创新之处。
Spark系统通过实现RDDs,已被广泛应用于各种用户应用程序和交互式数据挖掘,证实了其设计的有效性和实用性。
这篇论文的结论总结了RDDs的重要性和Spark系统在大数据计算领域的贡献,强调了其对现有框架的改进和对未来的启示。"
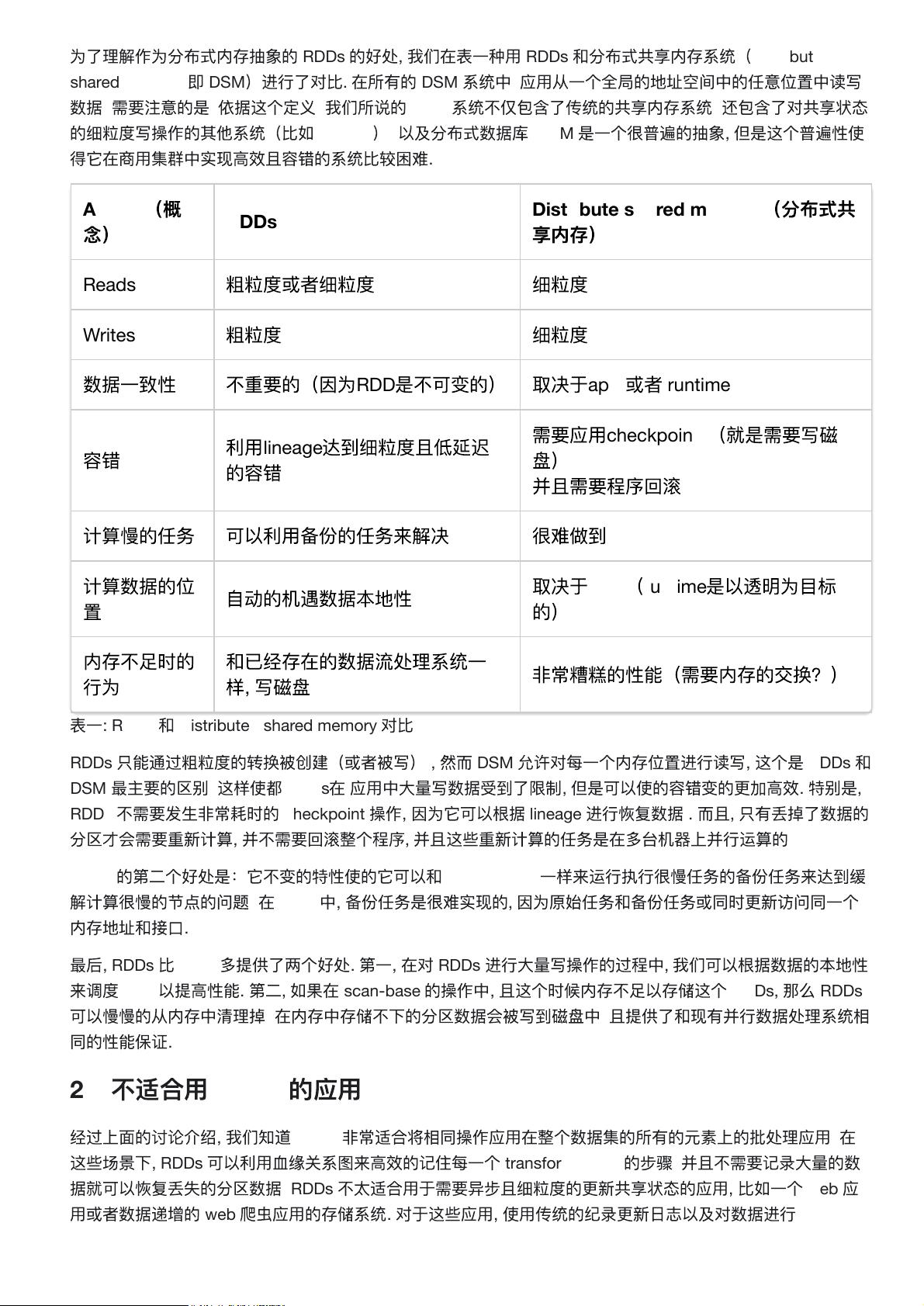
为了
理
解
作为
分
布
式
内
存
抽
象
的
RDDs
的
好处
,
我
们
在
表
一
种
用
RDDs
和
分
布
式
共
享
内
存
系统
(
Distributed
shared memory
即
DSM
)
进
行
了
对
比
.
在
所
有
的
DSM
系统
中
,
应
用
从
一个
全
局
的
地址
空
间
中
的
任
意
位
置
中
读
写
数据
.
需
要
注
意
的
是
,
依
据
这
个
定
义
,
我
们
所
说
的
DSM
系统
不
仅
包
含
了传
统
的
共
享
内
存
系统
,
还
包
含
了
对
共
享
状
态
的
细粒
度
写
操
作
的
其
他
系统
(
比
如
Piccolo
)
,
以
及
分
布
式
数据
库
. DSM
是
一个
很
普
遍
的
抽
象
,
但
是
这
个
普
遍
性
使
得
它
在商
用
集
群
中
实
现
高
效
且
容
错
的
系统
比
较
困
难
.
Aspect
(
概
Aspect
(
概
念
)
念
)
RDDs
RDDs
Distribute shared memory
(
分
布
式
共
Distribute shared memory
(
分
布
式
共
享
内
存
)
享
内
存
)
Reads
粗粒
度
或
者
细粒
度
细粒
度
Writes
粗粒
度
细粒
度
数据
一
致
性
不
重
要
的
(
因
为
RDD
是
不
可变
的
)
取
决
于
app
或
者
runtime
容
错
利
用
lineage
达
到
细粒
度
且
低
延
迟
的
容
错
需
要
应
用
checkpoints
(
就
是
需
要
写
磁
盘
)
并
且
需
要
程
序
回
滚
计
算
慢
的
任
务
可
以
利
用
备
份
的
任
务
来
解
决
很
难
做到
计
算
数据
的
位
置
自
动
的
机
遇
数据
本
地
性
取
决
于
app
(
runtime
是
以
透
明
为
目
标
的
)
内
存
不
足
时
的
行
为
和
已
经
存
在
的
数据
流
处
理
系统
一
样
,
写
磁
盘
非
常
糟糕
的
性
能
(
需
要
内
存
的
交
换
?)
表
一
: RDDs
和
Distributed shared memory
对
比
RDDs
只
能
通过
粗粒
度
的
转
换
被
创
建
(
或
者
被
写
)
,
然
而
DSM
允
许
对
每
一个
内
存
位
置
进
行读
写
,
这
个
是
RDDs
和
DSM
最
主
要
的
区
别
.
这
样
使
都
RDDs
在
应
用
中
大
量
写
数据
受
到
了
限
制
,
但
是
可
以使
的
容
错
变
的
更
加
高
效
.
特
别
是
,
RDDs
不
需
要
发
生
非
常
耗
时
的
checkpoint
操
作
,
因
为
它
可
以
根
据
lineage
进
行
恢
复
数据
.
而
且
,
只
有
丢
掉
了
数据
的
分
区
才
会
需
要
重
新
计
算
,
并
不
需
要
回
滚
整
个
程
序
,
并
且
这
些
重
新
计
算
的
任
务
是
在
多
台
机
器
上
并
行
运
算
的
.
RDDs
的
第
二
个
好处
是
:
它
不
变
的
特
性
使
的
它
可
以
和
MapReduce
一
样来
运
行
执
行
很
慢
任
务
的
备
份任
务
来
达
到
缓
解计
算
很
慢
的
节
点
的
问题
.
在
DSM
中
,
备
份任
务
是
很
难
实
现
的
,
因
为
原
始
任
务
和
备
份任
务
或
同
时更
新
访
问
同
一个
内
存
地址
和
接
口
.
最
后
, RDDs
比
DSM
多
提
供了
两个
好处
.
第
一
,
在
对
RDDs
进
行
大
量
写
操
作
的
过
程
中
,
我
们
可
以
根
据数据
的
本
地
性
来
调
度
task
以
提
高
性
能
.
第
二
,
如
果
在
scan-base
的
操
作中
,
且
这
个
时
候
内
存
不
足
以
存
储
这
个
RDDs,
那
么
RDDs
可
以
慢慢
的
从
内
存
中
清
理
掉
.
在
内
存
中
存
储
不下
的
分
区
数据
会
被
写到
磁
盘
中
,
且
提
供了
和
现
有
并
行
数据
处
理
系统
相
同
的
性
能
保
证
.
2.4
不
适
合
用
RDDs
的
应
用
经
过
上
面
的
讨论
介
绍
,
我
们
知
道
RDDs
非
常
适
合
将
相
同
操
作
应
用
在
整
个
数据
集
的
所
有
的
元
素
上
的
批
处
理
应
用
.
在
这
些
场
景
下
, RDDs
可
以
利
用
血
缘
关
系
图
来
高
效
的
记
住
每
一个
transformations
的
步
骤
,
并
且不
需
要记
录
大
量
的
数
据
就
可
以
恢
复
丢
失
的
分
区
数据
. RDDs
不
太
适
合
用
于
需
要
异
步
且
细粒
度
的
更
新
共
享
状
态
的
应
用
,
比
如
一个
web
应
用
或
者
数据
递
增
的
web
爬
虫
应
用
的
存
储
系统
.
对
于
这
些
应
用
,
使
用
传
统
的
纪
录
更
新日
志
以
及
对
数据
进
行
剩余22页未读,继续阅读
277 浏览量
点击了解资源详情
220 浏览量
270 浏览量
336 浏览量
277 浏览量
194 浏览量
220 浏览量
213 浏览量

jinc09
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
