Kaggle OTTO 推荐系统比赛方案解析
需积分: 0 177 浏览量
更新于2024-06-18
收藏 1.12MB PDF 举报
"Kaggle Topk商品推荐方案总结 - 2023-02-16"
这篇文档是关于2023年2月16日在Kaggle平台上进行的一项名为OTTO Multi-Objective Recommender System的比赛的总结。该比赛涉及到AI和人工智能领域,特别是推荐系统的应用。作者在文中分享了他们团队的竞赛经验和所学,以及一些顶级参赛团队的解决方案。
一、比赛介绍
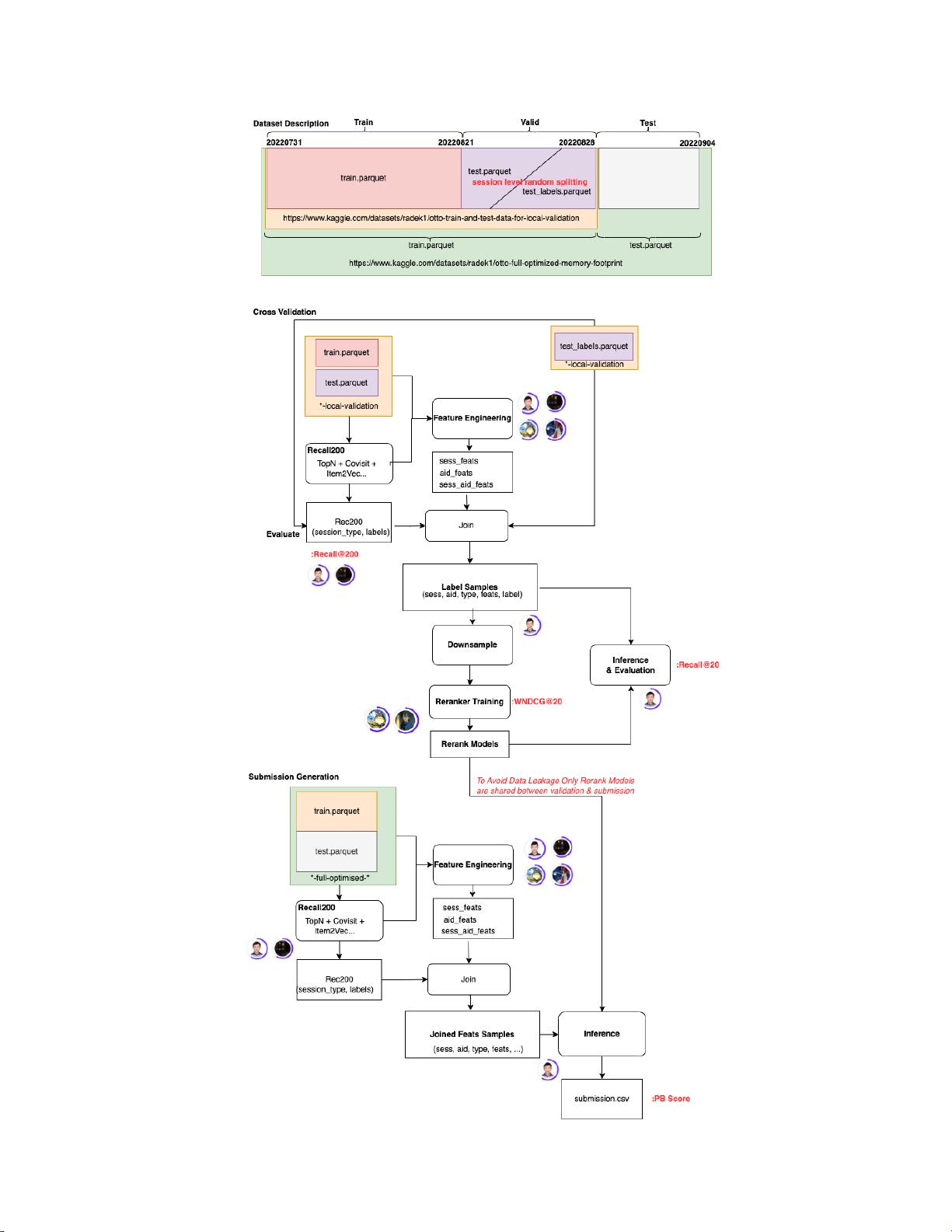
OTTO是一个电商推荐任务,目标是为每个用户的会话(session)推荐20个可能被点击、加入购物车或购买的商品。评估指标是加权平均各类型(clicks, carts, buys)的recall@20。数据集包含超过100万个商品和数千个用户的会话,且user与session之间是一对多的关系。训练集和测试集的session id没有重叠,意味着部分用户可能存在冷启动问题。数据集中约80%的点击行为不是由推荐系统引导,而是用户自主搜索或浏览产生的,这有助于模型避免过拟合,并鼓励探索新的用户兴趣。
二、团队方案
作者团队采用了以下步骤:
1. 召回阶段:利用不同的召回策略,针对每个session的三种类型行为(clicks, carts, buys),分别召回topk个商品。
2. 特征工程:构建了与session、商品(aid)和会话行为相关的特征,包括但不限于用户的会话历史、商品属性、时间序列信息等。
3. 模型融合:使用多种模型进行预测,如基于协同过滤的模型、基于内容的模型以及深度学习模型(例如,神经网络)。这些模型可能分别针对不同类型的推荐行为进行优化。
4. 集成策略:将多个模型的预测结果进行集成,通常采用加权平均或者堆叠的方法,以提升整体性能。
5. 调参与验证:利用交叉验证进行参数调优,并确保本地验证集(CV)的结果与线上测试集(LB)的一致性,防止过拟合和切榜抖动。
三、顶级方案亮点
虽然没有具体列出顶级团队的详细方案,但可以推测这些团队可能采取了以下策略:
1. 深度学习模型的创新:可能使用了更复杂的神经网络架构,如Transformer、RNN或BERT等,以捕捉会话中的序列信息和上下文依赖。
2. 多目标优化:由于比赛要求同时优化三种行为的recall@20,团队可能采用了多目标优化技术,平衡不同类型的推荐效果。
3. 冷启动处理:对于新用户或新商品,可能使用基于内容的推荐方法或者利用社交网络信息来填补数据空白。
4. 异常检测与噪声处理:对训练数据进行清洗,剔除异常点击和无效行为,提高模型的训练质量。
5. 迁移学习与预训练:可能利用了预训练模型,如商品描述的语义理解模型,以增强对商品的理解和推荐的准确性。
6. 动态更新:在比赛中可能实时监控LB成绩并调整策略,如动态调整模型权重,以适应线上环境的变化。
四、经验总结
作者强调了理论与实践相结合的重要性,通过参与此类竞赛,能更好地理解推荐系统在实际场景中的运作,以及如何解决现实问题。OTTO比赛提供了稳定的数据反馈,有助于团队避免过度担忧切榜波动,并能有效学习和验证新方法。
这份文档为想要深入了解推荐系统竞赛和实际应用的人提供了宝贵的经验和启示,涵盖了从数据理解到模型构建、优化和评估的全过程。
剩余19页未读,继续阅读
2023-12-06 上传
2023-12-04 上传
2023-12-02 上传
2023-12-02 上传
2023-12-06 上传
2023-12-04 上传
2023-12-06 上传
2023-12-06 上传
2023-12-02 上传


白话机器学习
- 粉丝: 1w+
- 资源: 7670
 我的内容管理
展开
我的内容管理
展开







最新资源
- 我2
- canvas:画布动画
- Deathmatch Game Server-开源
- 简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- CBDialog:一个快速创建对话框的工具类库
- 创意手绘灯泡公开课PPT模板
- github-slideshow:由机器人提供动力的培训资料库
- Fenerbahçe SK Anasayfa-crx插件
- eslint-config
- jfBroadcast:VoIP / SIP自动拨号器-开源
- DragonDB:文档存储
- Tiktoker.club-crx插件
- topbar:小巧美观的全站点进度指示器
- hlyfxs.github.io:hlyf的个人主页
- 带搜索的国际区号选择框.zip
- yiiShop:yiiShop-基于yii 1.1.12的在线商店
