数据挖掘:分类模型与决策树分析
需积分: 20 82 浏览量
更新于2024-07-19
收藏 2.7MB PPT 举报
本文主要探讨了数据挖掘中的分类方法,特别是决策树和模型评估的相关概念。
在数据挖掘领域,分类是一种重要的技术,它利用分类函数(分类模型或分类器)将数据库中的数据映射到预定义的类别中。这个过程通常分为两个步骤:首先,通过训练集构建模型,然后用测试集评估模型的准确性。训练集是由带有类别标记的数据元组组成,而测试集则是用于检验模型预测能力的一组独立数据。
分类模型的构建过程中,有监督学习是最常见的方式,尤其适用于分类任务。在这种学习模式下,模型在知道每个训练样本所属类别的指导下进行训练。常见的有监督学习方法包括决策树、规则归纳以及统计方法如贝叶斯分类、非参数方法等。无监督学习则不依赖于预先知道的类别信息,而是通过聚类算法寻找数据中的内在结构。
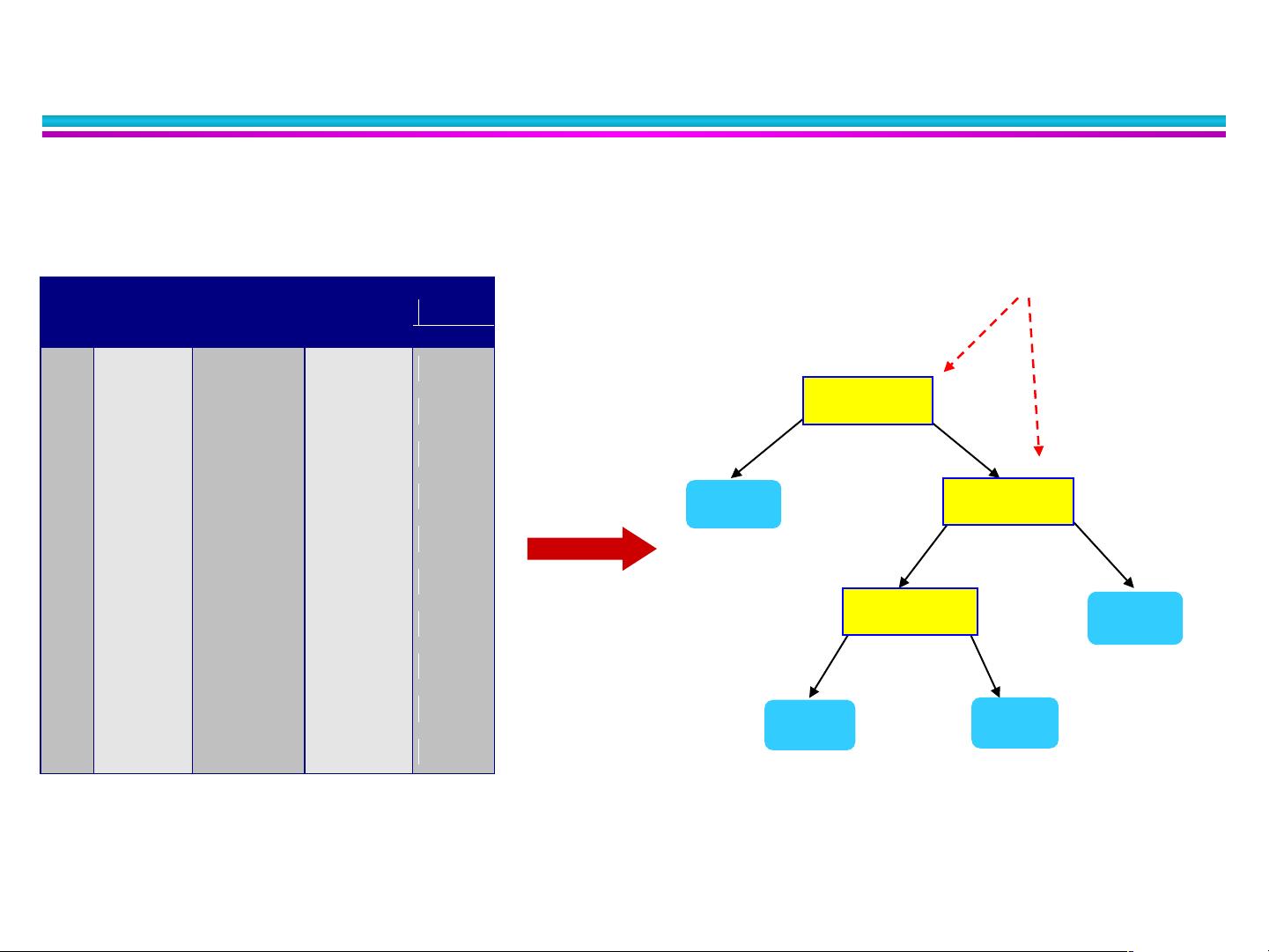
决策树是常用的一种分类模型,它通过一系列规则(节点和分支)来做出预测。例如,一个简单的决策树可能根据婚姻状态(Marital Status)和税务收入(Tax Income)来决定是否给予退款(Refund)。在构建决策树时,通常会根据某些属性(如MarSt和TaxInc)的分裂能力来选择最优的分割点。
模型评估是确保模型泛化能力的关键步骤。准确率是衡量模型性能的常用指标,即模型正确分类测试样本的比例。为了避免过拟合,测试集必须与训练集分离。过拟合发生时,模型过度适应训练数据,导致在未见过的新数据上表现不佳。
总结来说,分类是数据挖掘中的核心任务,涉及有监督学习、决策树构建以及模型评估等多个环节。理解这些基本概念对于理解和应用数据挖掘技术至关重要,特别是在处理分类问题时,决策树作为一种直观且易于解释的模型,经常被优先考虑。

用决策树归纳分类
什么是决策树?
–
类似于流程图的树结构
–
每个内部节点表示在一个属性上的测试
–
每个分枝代表一个测试输出
–
每个树叶节点代表类或类分布
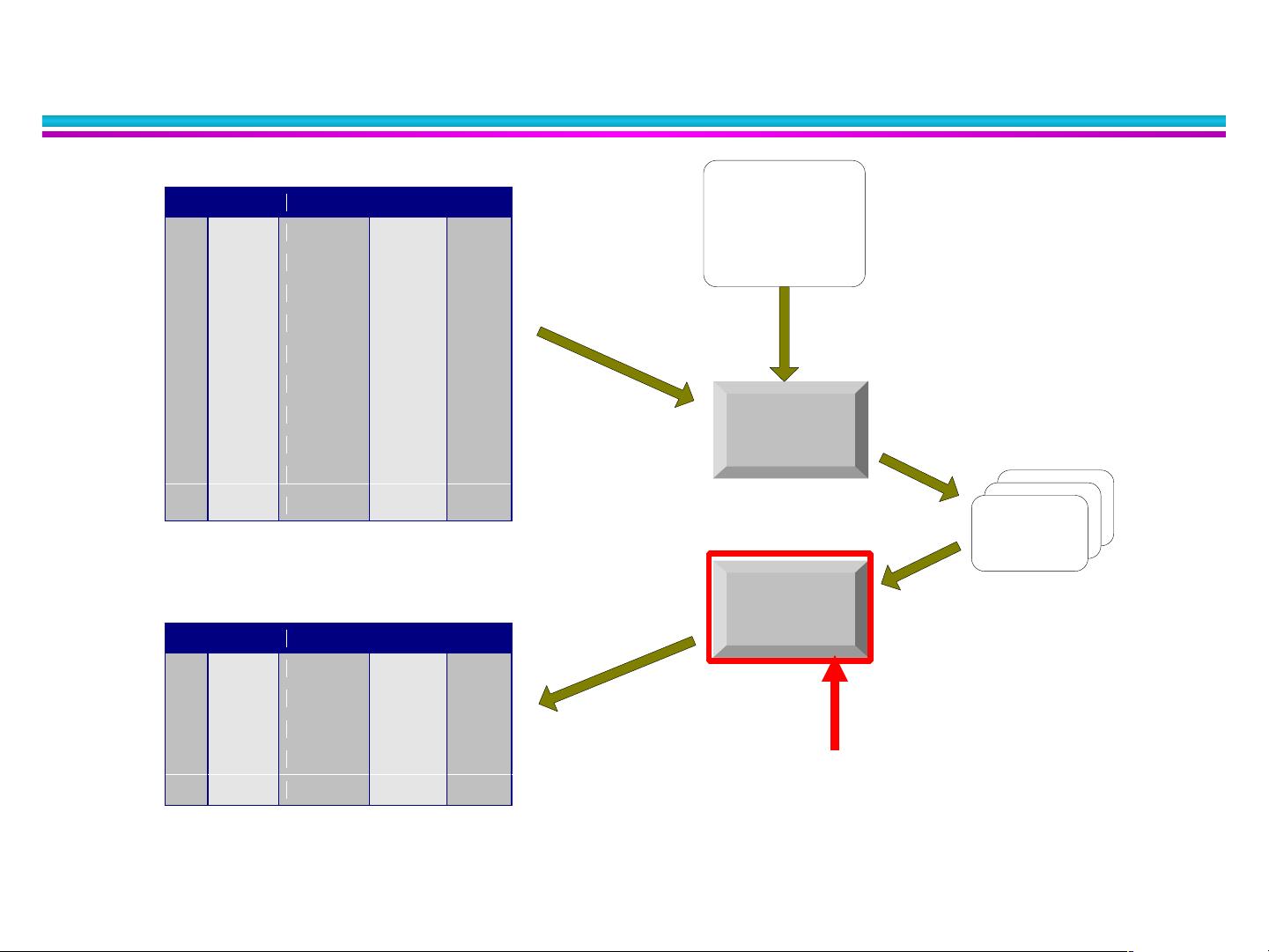
决策树的生成由两个阶段组成
–
决策树构建
开始时,所有的训练样本都在根节点
递归的通过选定的属性,来划分样本 (必须是离散值)
–
树剪枝
许多分枝反映的是训练数据中的噪声和孤立点,树剪枝试图
检测和剪去这种分枝
决策树的使用:对未知样本进行分类
–
通过将样本的属性值与决策树相比较
剩余62页未读,继续阅读
2018-10-22 上传
2014-02-26 上传
2013-05-14 上传
2024-06-22 上传
2024-10-27 上传
2023-06-10 上传
2024-10-28 上传
2023-05-19 上传
2023-06-21 上传

rudy_279150469
- 粉丝: 1
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
