MapReduce优化的抽样路径K-匿名算法在大数据隐私保护中的应用
201 浏览量
更新于2024-08-31
收藏 412KB PDF 举报
"基于MapReduce的并行抽样路径K-匿名隐私保护算法"
K-匿名算法是一种用于数据隐私保护的技术,其核心理念是确保每个个人的记录在发布的数据集中至少与另外k-1个记录相同,以此来防止通过数据识别出特定个体。然而,传统的K-匿名算法在处理大规模数据时面临效率低下的问题,因为它们通常涉及到频繁项集的生成和数据表的多次搜索,这些操作在单机环境中执行速度慢且消耗大量资源。
MapReduce是一种由Google提出的分布式计算模型,主要用于处理和生成大规模数据集。它将复杂的计算任务分解成两个主要阶段:Map阶段和Reduce阶段。Map阶段将输入数据分割成键值对,然后分别处理;Reduce阶段则将Map阶段的结果进行聚合,生成最终的输出。MapReduce通过并行处理大量数据,显著提高了处理效率,特别适合于大数据环境。
针对K-匿名算法的局限性,文中提出的基于MapReduce的并行抽样路径K-匿名隐私保护算法融合了这两种方法的优势。首先,它采用了抽样路径泛化策略,这是一种局域泛化算法,通过等概率抽样找到信息损失较小的泛化路径,以降低匿名化过程中的信息丢失。接着,通过MapReduce框架,将抽样路径泛化的过程分布到多个节点上并行执行,极大地提高了处理大数据集的速度。这样既解决了大数据量带来的计算瓶颈,又保证了匿名化的精度。
在实验部分,当数据量增大时,该优化算法表现出显著的性能提升,尤其是在时间效率和数据精度方面。这意味着,相比于传统的K-匿名算法,该方法能够在不显著增加信息损失的情况下,更快地完成大数据集的匿名化处理。
此外,文章还讨论了大数据环境下局域泛化算法面临的挑战,如计算资源的利用效率和信息损失与时间效率之间的平衡问题。通过引入MapReduce,算法不仅解决了计算效率问题,还降低了匿名数据集的信息损失,从而提高了数据的可用性。
总结来说,这篇论文提出的基于MapReduce的并行抽样路径K-匿名隐私保护算法是对传统K-匿名算法的一种有效优化,它适应了大数据时代的需求,为数据隐私保护提供了一个更为高效和精确的解决方案。
基于基于MapReduce的并行抽样路径的并行抽样路径K-匿名隐私保护算法匿名隐私保护算法
K-匿名算法及现存K-匿名改进算法大多使用牺牲时间效率降低发布数据信息损失量的方法实现数据的匿名化,
但随着数据量的急剧增长,传统的数据匿名化方法已不适用于对较大数据的处理。针对K-匿名算法在单机执行
过程中产生大量频繁项集和重复搜索数据表的缺点,将MapReduce模型引入到抽样泛化路径K-匿名算法中对其
进行优化。该方法兼具MapReduce及抽样泛化算法的优点,高效分布式匿名化数据集,降低发布数据集信息损
失量,提高数据的可用性。实验结果表明:当数据量较大时,该优化算法在时间效率及数据精度方面有显著提
高。
0 引言引言
K-匿名模型被提出之后
[1-2]
,国内外学者对此进行了大量研究,提出了众多K-匿名算法。这些算法大致可以分为两类:全域
泛化算法
[3-5]
和局域泛化算法
[6-10]
。全域泛化算法要求待发布的数据表中准标识符属性
[11-14]
泛化到同一层级,往往会造成较
大信息损失。局域泛化较为灵活,允许待发布数据表的属性泛化到不同的级别,使得匿名表具有较小的信息损失。然而,在大
数据的背景下,局域泛化算法也面临着挑战,主要包括2个问题:(1)随着大数据时代的数据体量越来越巨大,单个计算机难以
在可接受的时间内对数据进行有效的局域泛化。因此,如何利用并行分布式计算资源进行快速泛化
[15-16]
是亟待解决的关键问
题。(2)大多数局域泛化算法都是以牺牲时间效率来换取低信息损失量,无法做到两者兼顾
[17]
。
为了克服大数据背景下局域泛化的不足,本文提出在抽样路径局域泛化算法的基础上,对其耗时较大的部分引
入MapReduce技术。MapReduce是一种大型数据处理框架,为大数据应用提供了强大的计算能力
[18-19]
,成功解决了在较大
数据情况下局域泛化算法时间效率低的问题,同时降低了匿名化后的数据表信息损失量。
1 算法算法
1.1 算法设计算法设计
抽样路径泛化算法是一种信息损失量较小的局域泛化K-匿名算法,其思想是引入等概率抽样的方法,使用抽样样本在泛化
格(generalization lattice)
[4,20]
上快速寻找一条信息损失量较小的泛化路径,在已得到的抽样泛化路径上依次对源数据集中未
满足K-匿名的等价类进行泛化,最终得到一个高精度的K-匿名表。
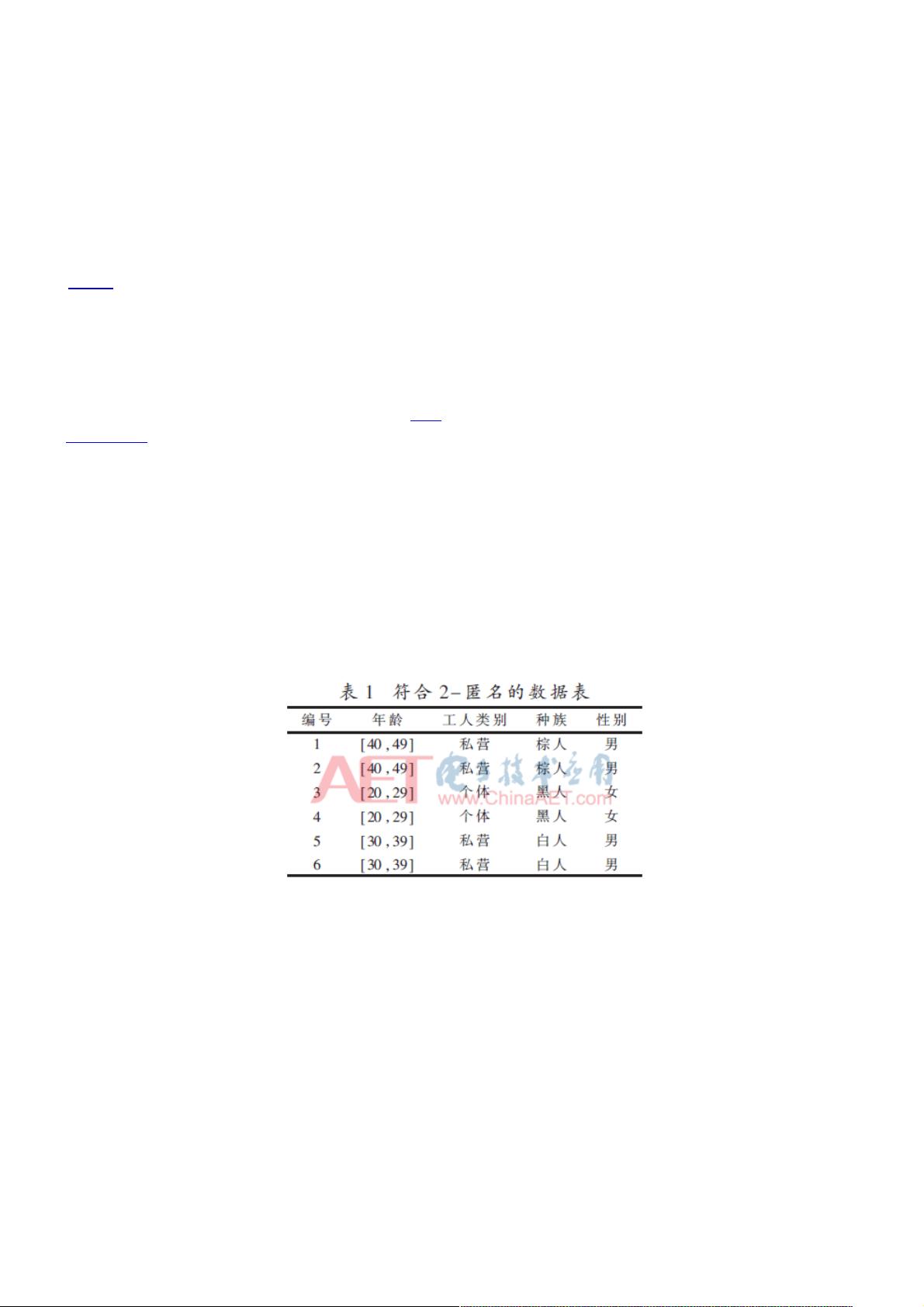
定义1 等价类。数据表T(A
1
,A
2
,…,A
n
),在准标识符集A
1
,A
2
,…,A
j
上的一个等价类是指准标识符属性取值均相同的
元组集合。例如:表1中,ID为1、2的两个元组组成的集合就是一个等价类。
定义2 K-匿名。给定数据表T(A
1
,A
2
,…,A
n
),QI是T的准标识符集。经过匿名化处理后,数据表T每条元组在准标识符集
属性上至少有K-1条与其不可区分的元组,则T满足K-匿名,表1为满足2-匿名。
定义3 抽样泛化路径。以泛化格的根节点为起点,计算其子节点对样本泛化后的信息损失量,将其信息损失量最小子节点插
入路径,自底向上,直至泛化格叶子节点。例如:图1中是由工人类别和性别组成的一个泛化格实例,若用<W1,S0>这个节
点泛化样本比<W0,S1>泛化样本信息损失小,则选取<W1,S0>为路径的第2个节点,以此类推,找到一条如<W0,S0>→
<W1,S0>→…→<W2,S1>抽样泛化路径。在此路径上对源数据表进行局域泛化,得到高精度的K-匿名表。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-08-09 上传
2021-08-15 上传
2021-10-17 上传
2024-03-13 上传
2021-04-10 上传
2021-05-30 上传

weixin_38523728
- 粉丝: 3
- 资源: 973
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
