数据仓库上游系统调研与贴源层分析
需积分: 50 67 浏览量
更新于2024-09-05
收藏 2.4MB PPTX 举报
"该文档是2019年8月28日关于数据仓库贴源层的演示,主要内容涉及数据仓库入仓表的分析规则,上游系统现状的调研,以及如何选择适合入仓的业务表。文档提到了缓冲存储层的作用,数据质量检验的策略,以及入仓系统的初步筛选标准。"
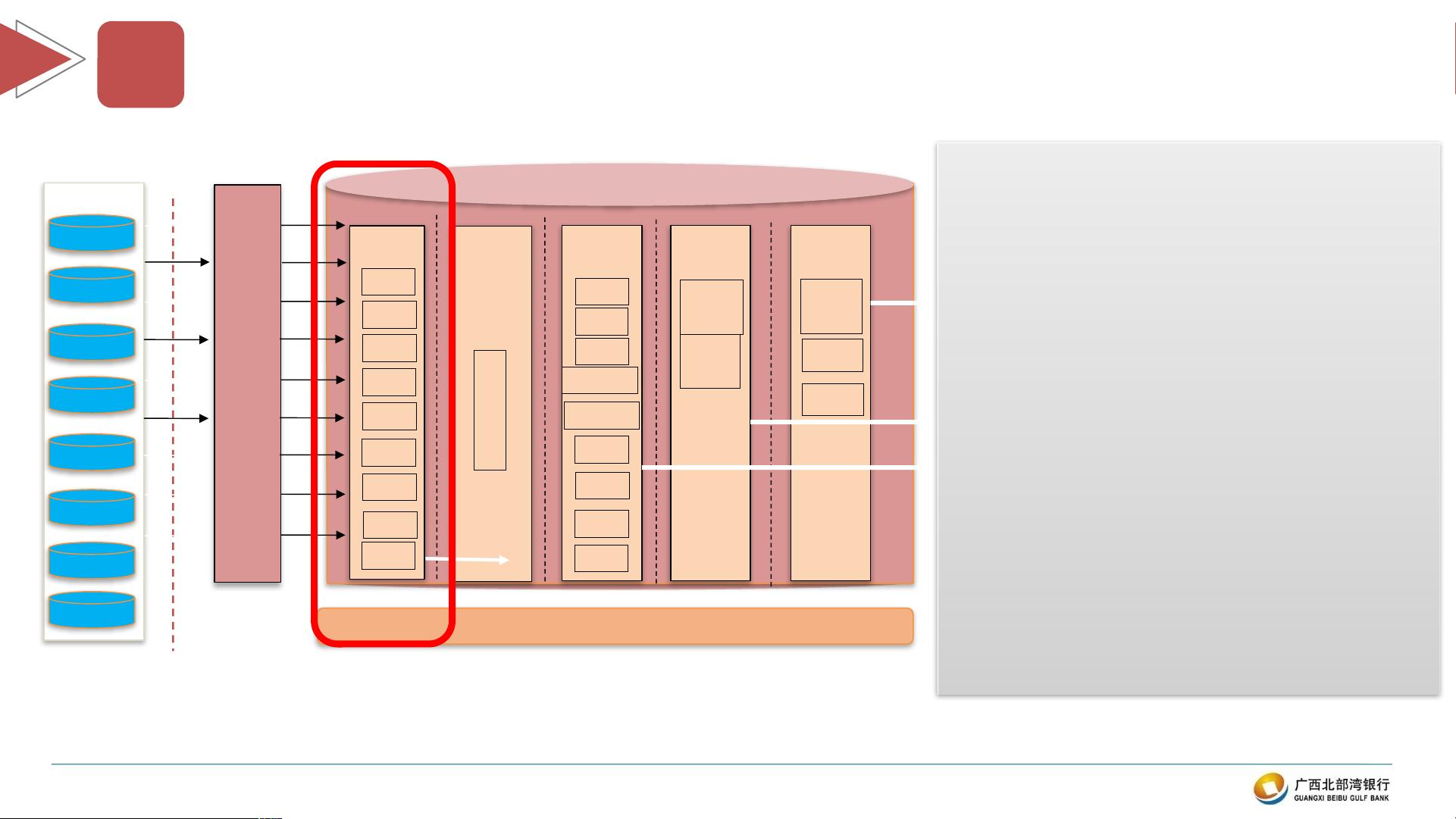
数据仓库是存储和管理大量结构化数据以支持业务智能、数据分析和决策制定的系统。在数据仓库的设计中,贴源层或近源层扮演着重要角色,它位于数据源和数据仓库的其他层次之间,旨在提供一个可供查询的、快速访问的数据副本,同时保护原始数据源不受频繁读取和误操作的影响。
贴源层的设计目的是减少对上游系统的性能负载,允许数据重跑,并且通常保持与源系统相似的表结构,添加额外的信息如源系统标识、ETL日期和供数方式。在数据质量检验方面,包括成功标识、系统名校验、表校验、字段对比、数据量、分区和历史缓慢变化维的检查,确保数据的准确性和一致性。
文档中提到的首批九个入仓系统名单,以及后续的约41个入仓系统的选择过程,展示了数据仓库构建过程中严谨的系统评估。在选择入仓系统时,需要考虑系统的字典版本、数据库连接信息、系统是否仍在运行、数据字段的用途和必要性等因素。例如,字段级的分析排除了无意义的字段(如空字段、固定值字段、加载时间等)、业务上不使用的长文本、流程控制字段、中间计算结果、未启用字段、冗余字段和非结构化数据。
对于上游系统表的业务含义和下游用途的理解至关重要。数据仓库系统定位为提供服务给各类内部应用、OLAP分析、BI系统,重点关注那些关键业务数据、保留粒度较细的表,如信息表、业务明细、交易流水、映射关系表、维度表和参数代码类型表。同时,需要排除内部控制、业务流程控制表,以及中间的、临时的、备份的、冗余的、预留的数据,以及无活动的表。
规划的下游系统模型主题涵盖了金融行业的多个领域,包括监管报告、风险管理、对账、营销、客户关系管理、绩效考核等多个业务场景,表明数据仓库在银行业务中的核心地位,为各类业务决策提供数据支持。
这份演示文稿详细阐述了数据仓库贴源层的设计原则和上游系统调研的关键点,提供了选择合适入仓数据的框架,为构建高效、稳定的数据仓库体系提供了指导。
海纳百川 开拓未来
核心
前置
网银
手机银行
信贷
国结
票据
…
E
T
L
抽
取
数 据 交 换 平 台
标
准
数
据
接
口
统一监管
支付信息统计
PISA
…..
固定
报表
多维
分析
即席
查询
报表平台
SmartBI
数据仓库
DWO
核心
前置
网银
手银
信贷
国结
票据
…
DWF
客户
存款
贷款
银行卡
产品
渠道
…
DWI
轻度
汇总
指标
层
DW
S
数
据
标
准
化
机构
资金
财务
DM
报表
集市
……
……
老
ODS
数
据
接
口
管理会计信息系统
人行报送大集中
电话营销
现金报送
综合积分系统
缓冲存储可供查询的、快速访问的、源
系统业务原貌的数据
屏蔽干扰,避免频繁读取、误操作数据
源,避免对上游增加性能负载
允许重跑载入
表结构几乎与源结构一致,保有核查
信息:源系统、 ETL_DATE 、供数
方式
数据质量检验( OK 检查):成功标识、
系统名校验、表校验、字段对比、数据
量、分区、历史缓慢变化维
01
贴源层位置特征
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
102 浏览量
2021-09-29 上传

tot286969
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java实现推箱子小程序技术解析
- Hopp Doc Gen CLI:打造HTTPS API文档利器
- 掌握Pentaho Kettle解决方案与代码实践
- 教育机器人大赛51组代码展示自主算法
- 初学者指南:Android拨号器应用开发教程
- 必胜客美食宣传广告的精致FLASH源码解析
- 全技术领域资源覆盖的在线食品商城购物网站源码
- 一键式FTP部署Flutter Web应用工具发布
- macOS下安装nVidia驱动的简易教程
- EGOTableViewPullRefresh: GitHub热门下拉刷新Demo介绍
- MMM-ModuleScheduler模块:MagicMirror的显示与通知调度工具
- 哈工大单片机课程上机实验代码完整版
- 1000W逆变器PCB与原理图设计制作教程
- DIV+CSS3打造的炫彩照片墙与动画效果
- 计算机网络基础与应用:微课版实训教程
- gvim73_46:最新GVIM编辑器的发布与应用
