QTSDB:基于influxdb的分布式时序数据库设计与高性能特性
15 浏览量
更新于2024-08-31
收藏 440KB PDF 举报
分布式时序数据库QTSDB的设计与实现是一篇深入探讨如何基于开源单机时序数据库InfluxDB 1.7构建的分布式解决方案。QTSDB的主要目标是处理大规模的时间序列数据,提供高效的写入性能和磁盘空间管理,同时具备高可用性和扩展性。
QTSDB的特点包括:
1. **专为时间序列设计**:QTSDB采用专门为处理时间序列数据优化的数据存储技术,确保在处理大量写入时,保持性能高效且磁盘空间占用得到有效控制。
2. **SQL查询支持**:它支持类SQL查询语句,使得数据分析更加直观和便捷,能够执行多种统计聚合函数,如求和、平均值、最大值等。
3. **自动数据清理**:系统内置机制能够自动清除过期数据,减轻数据管理负担,保持数据的整洁性和有效性。
4. **连续查询与预设聚合**:QTSDB提供内置的连续查询功能,用户无需手动操作即可完成预设的聚合操作,提高效率。
5. **Golang编写与轻量依赖**:QTSDB采用Golang编写,这使得部署和运维更为简单,降低了基础设施的复杂度。
6. **动态水平扩展**:QTSDB支持节点的动态扩展,随着数据量的增长,可以通过添加更多节点来处理更大的数据存储需求。
7. **副本冗余与故障转移**:通过副本冗余设计,系统能够在节点故障时自动进行故障转移,保证服务的高可用性。
8. **优化写入性能**:针对大数据量写入,QTSDB进行了优化,能够支持高吞吐量,满足实时数据处理的需求。
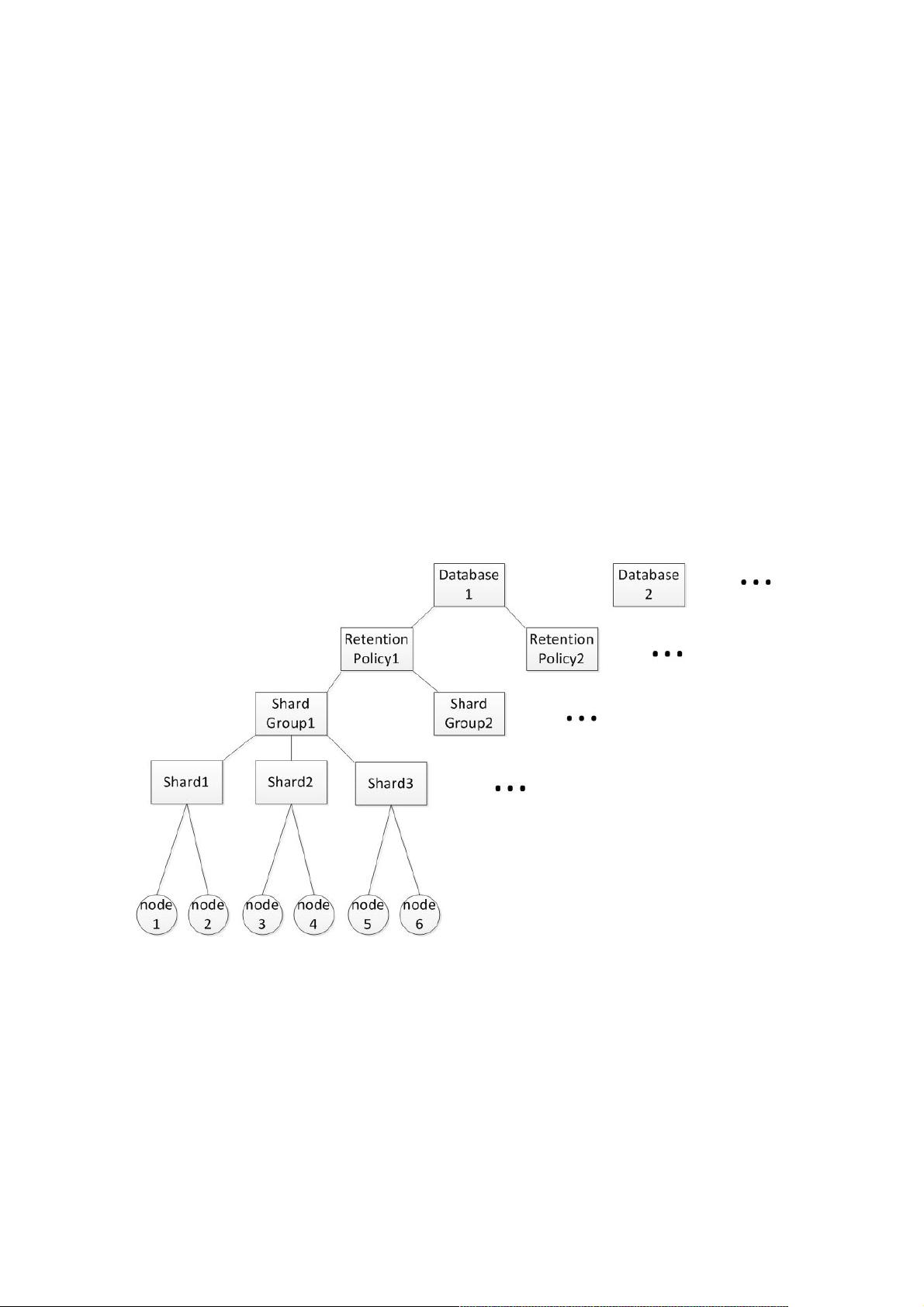
在系统架构方面,QTSDB采用了层次化的逻辑存储结构。首先,数据库层是最顶层,下设基于数据保留期限的不同retention policy,形成多个存储容器。每个retention policy进一步划分为多个shard group,每个时间段的数据存储在一个特定的shard group中。shard group按照数据的生命周期动态创建和删除,以减少存储开销。shard则进一步细化,全球唯一并分布于各个物理节点,每个shard由tsm存储引擎负责存储。
查询时,系统根据请求的database、retention policy和时间段锁定相应的shard group,确保数据的准确访问。整体来说,QTSDB的设计充分考虑了时间和数据管理的关键需求,为大规模时间序列数据提供了一种高效且可靠的分布式解决方案。
分布式时序数据库分布式时序数据库QTSDB的设计与实现的设计与实现
QTSDB 简述
QTSDB是一个分布式时间序列数据库,用于处理海量数据写入与查询。实现上,是基于开源单机时序数据库influxdb 1.7开发
的分布式版本,除了具有influxdb本身的特性之外,还有容量扩展、副本容错等集群功能。
主要特点如下:
为时间序列数据专门编写的高性能数据存储, 兼顾写入性能和磁盘空间占用;
类sql查询语句, 支持多种统计聚合函数;
自动清理过期数据;
内置连续查询,自动完成用户预设的聚合操作;
Golang编写,没有其它的依赖, 部署运维简单;
节点动态水平扩展,支持海量数据存储;
副本冗余设计,自动故障转移,支持高可用;
优化数据写入,支持高吞吐量;
系统架构
逻辑存储层次结构
influxdb架构层次最高是database,database下边根据数据保留时长不同分成了不同的retension policy,形成了database下面
的多个存储容器,因为时序数据库与时间维度关联,所以将相同保留时长的内容存放到一起,便于到期删除。除此之外,在
retension policy之下,将retension policy的保留时长继续细分,每个时间段的数据存储在一个shard group中,这样当某个分
段的shard group到期之后,会将其整个删掉,避免从存储引擎内部抠出部分数据。例如,在database之下的数据,可能是30
天保留时长,可能是7天保留时长,他们将存放在不同的retension policy之下。假设将7天的数据继续按1天进行划分,就将他
们分别存放到7个shard group中,当第8天的数据生成时,会新建一个shard group写入,并将第 1天的shard group整个删除。
到此为止,同一个retension policy下,发来的当下时序数据只会落在当下的时间段,也就是只有最新的shard group有数据写
入,为了提高并发量,一个shard group又分成了多个shard,这些shard全局唯一,分布于所有物理节点上,每个shard对应一
个tsm存储引擎,负责存储数据。
在请求访问数据时,通过请求的信息可以锁定某个database和retension policy,然后根据请求中的时间段信息,锁定某个
(些)shard group。对于写入的情况,每条写入的数据都对应一个serieskey(这个概念后面会介绍),通过对serieskey进行
哈希取模就能锁定一个shard,进行写入。而shard是有副本的,在写入的时候会采用无主多写的策略同时写入到每个副本中。
查询时,由于查询请求中没有serieskey的信息,所以只能将shard group内的shard都查询一遍,针对一个shard,会在其副本
中选择一个可用的物理节点进行访问。
那么一个shard group要有多少shard呢,为了达到最大并发量,又不过分干扰数据整体的有序性,在物理节点数和副本数确定
下载后可阅读完整内容,剩余4页未读,立即下载
140 浏览量
252 浏览量
209 浏览量
120 浏览量
198 浏览量
136 浏览量
157 浏览量
101 浏览量

weixin_38589314
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位instantclient_11_2使用指南及配置教程
- kWSL在WSL上轻松安装KDE Neon 5.20无需额外软件
- phpwebsite 1.6.2完整项目源码及使用教程下载
- 实现UITableViewController完整截图的Swift技术
- 兼容Android 6.0+手机敏感信息获取技术解析
- 掌握apk破解必备工具:dex2jar转换技术
- 十天掌握DIV+CSS:WEB标准实践教程
- Python编程基础视频教程及配套源码分享
- img-optimize脚本:一键压缩jpg与png图像
- 基于Android的WiFi局域网即时通讯技术实现
- Android实用工具库:RecyclerView分段适配器的使用
- ColorPrefUtil:Android主题与颜色自定义工具
- 实现软件自动更新的VC源码教程
- C#环境下CS与BS模式文件路径获取与上传教程
- 学习多种技术领域的二手电子产品交易平台源码
- 深入浅出Dubbo:JAVA分布式服务框架详解
