TensorFlow on Yarn:深度学习与大数据整合实践
需积分: 9 113 浏览量
更新于2024-07-17
收藏 2.42MB PDF 举报
"这篇资料是QCON2017软件大会上关于深度学习和大数据的一份PPT,重点探讨了TensorFlow技术及其在Yarn上的应用。由李远策分享,内容包括TensorFlow的使用现状、痛点,以及在Yarn上的设计和实施细节,同时还涉及深度学习平台的演进和SparkFlow的介绍。"
深度学习是一种模仿人脑工作原理的机器学习方法,近年来在图像识别、语音处理、自然语言处理等领域取得了显著成果。TensorFlow是由Google开发的一个开源库,它提供了构建和部署大规模机器学习模型的工具,广泛应用于深度学习领域。
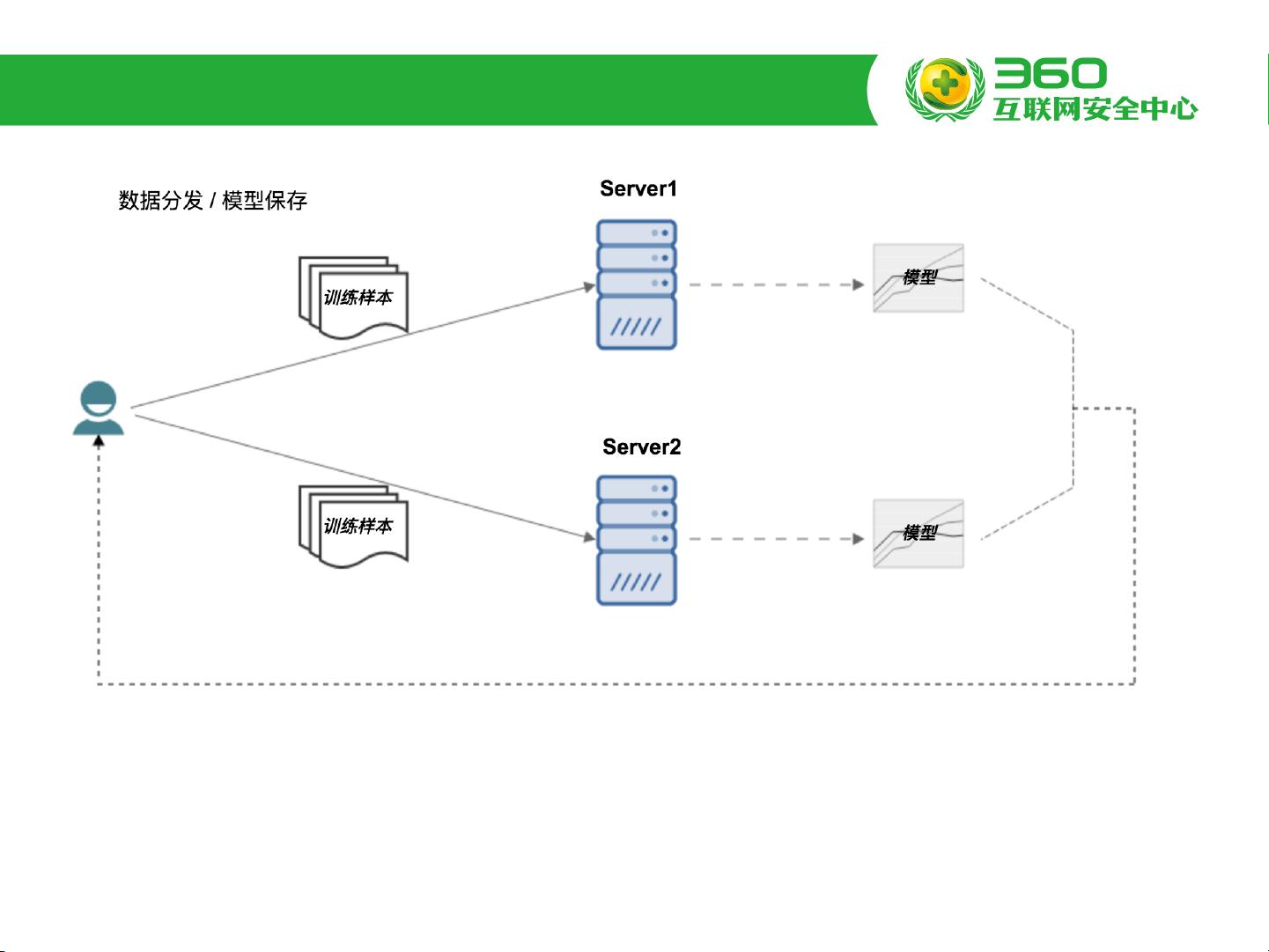
在当前的深度学习环境中,TensorFlow面临一些挑战和痛点。首先,手动指定机器和端口配置在分布式环境下非常繁琐,容易导致端口冲突和机器负载不均衡。其次,训练样本和模型需要手动分发和拉取,增加了操作复杂性。此外,多用户多服务器的使用可能导致资源划分混乱,缺乏有效的GPU资源管理和调度,进一步加剧了集群资源的负载不均。作业管理和状态跟踪不便,日志查看也不够便捷。
为了解决这些问题,Yarn(Hadoop的资源管理系统)被引入到TensorFlow中,形成了TensorFlow on Yarn的设计。Yarn能够提供对单机和分布式TensorFlow程序的支持,并实现了GPU资源的管理和调度。通过Yarn,用户不再需要手动配置ClusterSpec,只需指定worker和parameter server(ps)的数量。训练数据和模型可以基于HDFS进行统一存储,作业结束时,包括work、ps和Tensorboard在内的进程将自动回收。这一设计保持了训练效果和性能,同时极大地简化了运维流程,提高了效率。
深度学习平台的演进也提到了SparkFlow,这是结合了Spark和深度学习的一种框架,旨在优化数据处理和模型训练的流程。通过这样的集成,用户可以更好地利用大数据处理能力与深度学习的强大学习能力,实现更高效的数据驱动的决策。
TensorFlow on Yarn通过整合大数据管理和深度学习框架,解决了资源管理、作业调度和监控等问题,提升了深度学习在大规模环境下的实用性和易用性。对于企业而言,这样的解决方案有助于加速深度学习技术的落地应用,促进业务创新。

TensorFlow使用现状及痛点
tf.train.ClusterSpec({
“worker”: [
“worker0.example.com:2222”,
“worker1.example.com:2222”,
“worker2.example.com:2222”
],
“ps”: [
“ps0.example.com:2222”,
“ps1.example.com:2222”
]})
分布式版本ClusterSpec定义:
带来的问题:
•手动指定机器很繁琐
•端口冲突
•机器负载不均
剩余32页未读,继续阅读
点击了解资源详情
点击了解资源详情
125 浏览量
410 浏览量
227 浏览量
126 浏览量
点击了解资源详情
点击了解资源详情
209 浏览量

沙漠之鹰007
- 粉丝: 46
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows 2000驱动开发全攻略:环境、PnP与内核模式详解
- 51单片机实现多功能时钟程序
- NS手册中文精译版:网络模拟与实践指南
- MSA2.0远程访问服务规划与设计指南
- S3C4510B平台下的uClinux入门与应用开发
- Oracle9i&10g数据库体系结构深度解析
- VC++实战指南:从基础到高级应用
- 电子商务基础与影响:从概念到未来发展
- 工作流技术详解:从概念到历史
- USB接口详解:连接、协议与拓扑结构
- 理解AT&T汇编语言格式与GCC内嵌汇编
- NRF9E5射频芯片驱动的无线耳机系统设计与优析
- OpenGL高级图形编程技术探索
- Linux ASM:入门与嵌入式优化的关键
- Ant入门教程:构建Java项目的利器
- C++编程规范与最佳实践
