Scala基础入门:Spark大数据处理框架详解与发展历程
需积分: 7 74 浏览量
更新于2024-07-21
1
收藏 4.45MB PDF 举报
Scala基础教程是一本全面介绍Scala编程语言及其在大数据领域中的应用和优势的指南。Scala作为一种多范式编程语言,结合了面向对象编程和函数式编程的特点,尤其适合构建高性能、可扩展的大数据处理系统。本教程的第1章首先概述了Apache Spark,一个重要的分布式计算框架。
Spark的核心理念是基于内存计算,它显著提升了大数据环境下的实时处理能力,同时保持高容错性和可扩展性。它的设计允许在廉价硬件上轻松构建大规模集群,极大地降低了大数据处理的成本。Spark起源于2009年的加州大学伯克利分校AMPLab,并在2010年成为开源项目。随后,Spark经历了快速发展阶段,2013年加入Apache孵化器项目,2014年成为顶级项目,并逐渐取代MapReduce成为首选的大数据处理工具。
Spark生态系统日益壮大,包括SparkSQL(用于SQL查询的模块)、SparkStreaming(实时流处理)和GraphX(图处理库)等多个子项目。这些组件使得Spark能够支持多样化的大数据分析任务,如批处理、迭代计算和SQL查询,性能相比传统方法有显著提升。此外,Pivotal Hadoop、MapR等大数据公司纷纷支持Spark,甚至Cloudera宣布将投入更多资源于Spark,显示其在业界的广泛接受度。
Spark的历史发展中,关键里程碑包括2014年5月Pivotal将Spark整合到Hadoop全栈,以及同年5月发布的Spark 1.0.0版本。Spark峰会在同月举行,进一步推动了技术交流和社区建设。AMPLab和Databricks作为主要开发者,吸引了众多公司如Yahoo!和Intel的参与,以及众多开源爱好者的贡献。
Scala基础教程的第1章为读者揭示了Scala在大数据处理领域的核心价值和Spark框架的发展历程,为后续章节深入探讨Scala语法、API和实际应用案例奠定了坚实的基础。学习者通过这一章节能更好地理解Spark如何通过内存计算实现高效性能,以及如何适应不断扩大的生态系统,从而在大数据处理场景中发挥重要作用。
16
Spark大数据处理:技术、应用与性能优化
在 2013 年,Yahoo! 拥有 72 656 600 个页面,有上百万的商品类别,上千个商品和用户
特征,超过 800 万用户,每天需要处理海量数据。
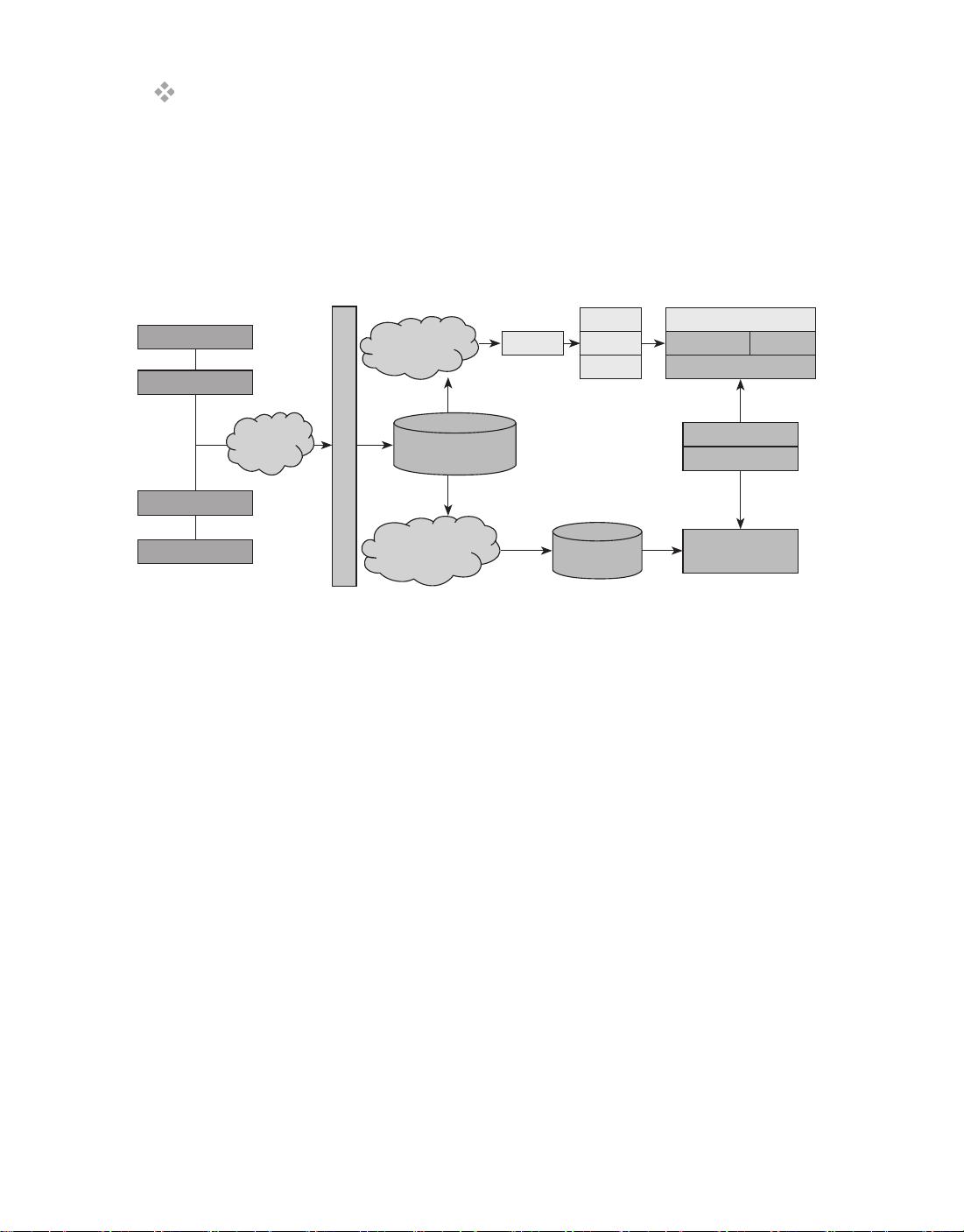
通过图 1-11 可以看到 Yahoo! 使用 Spark 进行数据分析的整体架构。
Mobile App
批处理 / 数据管理
未来的分析栈
Spark
View 1 Shark
Spark/MR Hive
YARN
View 2
View
n
Pixel Server
Ad Server
Web Page
Stream Processing/
Queues
ETL/HDFS
数据传递 & 收集
RDBMS/
NoSQL
Adhoc
BI/OLAP
Staging/
Distribution
Colos
实时 App/
查询
图 1-11 Yahoo! 大数据分析栈
大数据分析平台架构解析如下。
整个数据分析栈构建在 YARN 之上,这是为了让 Hadoop 和 Spark 的任务共存。主要包
含两个主要模块:
1)离线处理模块:使用MapReduce 和 Spark+Shark 混合架构。由于MapReduce 适
合进行 ETL 处理,还保留 Hadoop 进行数据清洗和转换。数据在 ETL 之后加载进 HDFS/
HCat/Hive 数据仓库存储,之后可以通过 Spark、Shark 进行 OLAP 数据分析。
2)实时处理模块:使用 Spark Streaming + Spark+Shark 架构进行处理。实时流数据源
源不断经过 Spark Steaming 初步处理和分析之后,将数据追加进关系数据库或者 NoSQL 数
据库。之后,结合历史数据,使用 Spark 进行实时数据分析。
之所以选择 Spark,Yahoo! 基于以下几点进行考虑。
1)进行交互式 SQL 分析的应用需求。
2)RAM 和 SSD 价格不断下降,数据分析实时性的需求越来越多,大数据急需一个内
存计算框架进行处理。
3)程序员熟悉 Scala 开发,接受 Spark 学习曲线不陡峭。
4)Spark 的社区活跃度高,开源系统的 Bug 能够更快地解决。
5)传统 Hadoop 生态系统的分析组件在进行复杂数据分析和保证实时性方面表现得力


剩余254页未读,继续阅读
2018-12-27 上传
2010-04-09 上传
2018-02-23 上传
2021-02-26 上传
2015-08-25 上传
2008-05-31 上传
2012-04-17 上传
2018-04-25 上传
2018-12-22 上传

sijiyufeng
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
