分布式文件系统:概念、发展历程与关键技术
分布式文件系统
分布式文件系统是一种先进的数据存储解决方案,它打破了传统本地文件系统的局限,将存储资源通过网络连接,使得多台计算机可以共同访问和管理同一份文件系统。这种系统的设计目标是实现高效、透明、可扩展和高可用性的数据存储,以满足大规模计算和大数据处理的需求。
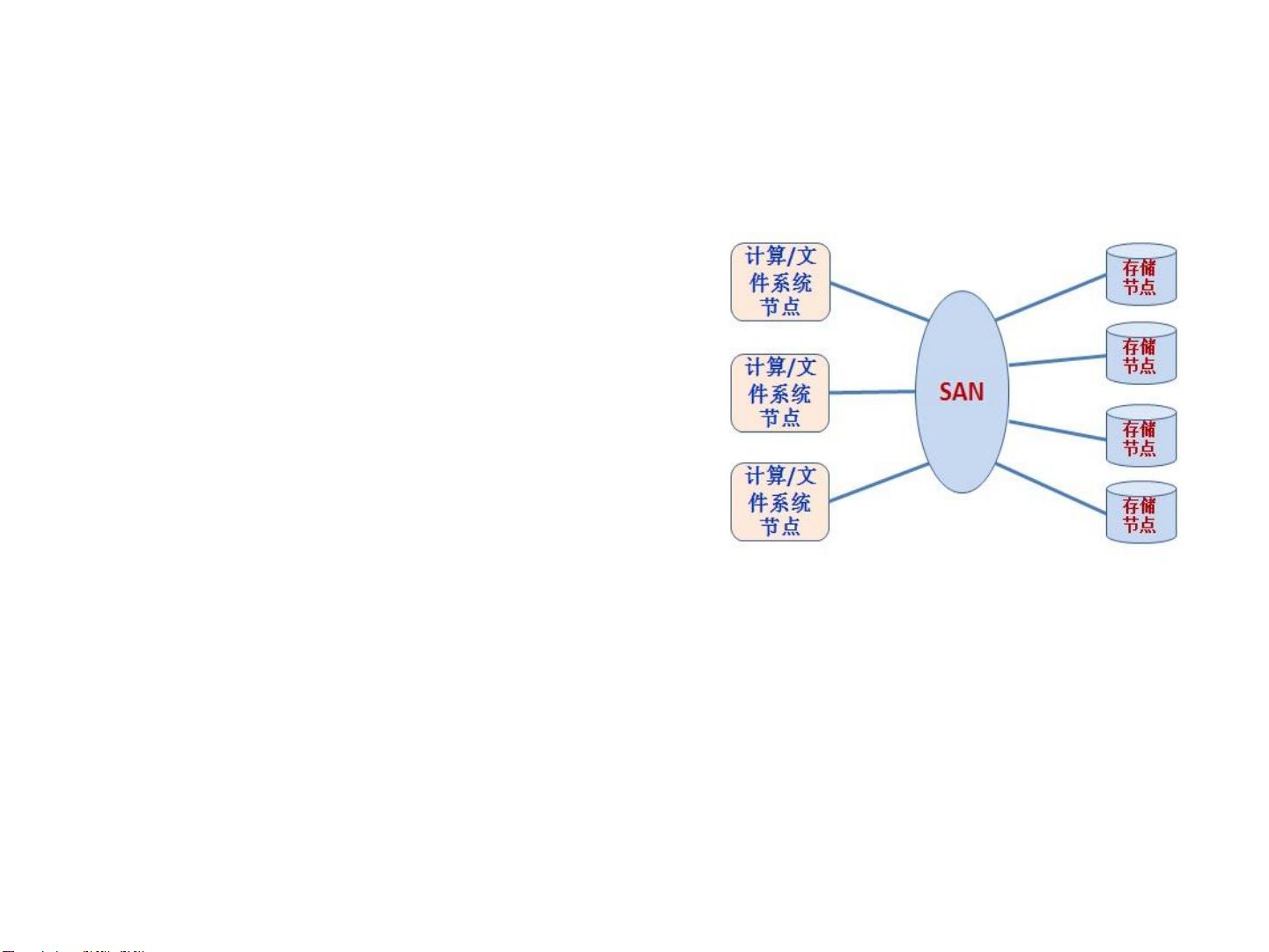
分布式文件系统的发展经历了几个阶段。最初是网络文件系统(1980s),如NFS(Network File System)和AFS(Andrew File System),它们允许不同计算机间的文件共享。接下来是共享SAN(Storage Area Network)文件系统(1990s),这些系统利用高速网络连接存储设备,提供高性能的I/O。进入21世纪,随着并行计算和大数据的发展,出现了面向对象的并行文件系统,如GPFS、Lustre和Panasas,它们特别针对高性能计算和大规模数据处理进行了优化。
系统架构通常包括以下几个核心组件:
1. **元数据服务**:负责文件名、目录结构、权限等元数据的管理和查找,确保文件系统的一致性和完整性。
2. **数据分布模式**:数据在多台服务器之间的分布策略,如复制、分片或条带化,以提高读写性能和容错能力。
3. **访问接口**:提供给用户和应用程序的接口,如POSIX接口或特定API,使用户能够像访问本地文件一样操作分布式文件。
4. **共享语义和共享锁**:确保在多用户环境下对文件的并发访问和修改的正确性,避免数据冲突。
5. **系统扩展性**:通过增加节点数量来扩展存储容量和处理能力。
6. **系统可用性**:通过冗余和故障恢复机制确保服务的持续可用性,即使部分硬件出现故障。
7. **Cache一致性**:在分布式环境中,确保缓存数据的正确性,避免数据不一致。
8. **典型案例**:包括Hadoop HDFS、Google的GFS、Facebook的Haystack、Amazon的S3以及许多开源项目,如Ceph、GlusterFS和FastDFS等。
这些系统各有特点,例如,HDFS是为大数据分析设计的,侧重于高吞吐量读写;而GFS和HDFS都采用了主从结构,一个主节点负责元数据管理,多个从节点存储数据;Ceph则采用更灵活的CRUSH算法进行数据分布,提供高可用性和可扩展性。
在设计分布式文件系统时,必须考虑一致性模型,如CAP理论(Consistency、Availability、Partition Tolerance),根据应用场景选择合适的权衡。此外,安全性也是重要一环,包括用户身份验证、访问控制、数据安全传输和加密。
总而言之,分布式文件系统是现代云计算、大数据和高性能计算领域的基石,它们通过复杂的机制实现了跨地域、跨设备的数据共享和管理,为大规模数据处理提供了强有力的支持。
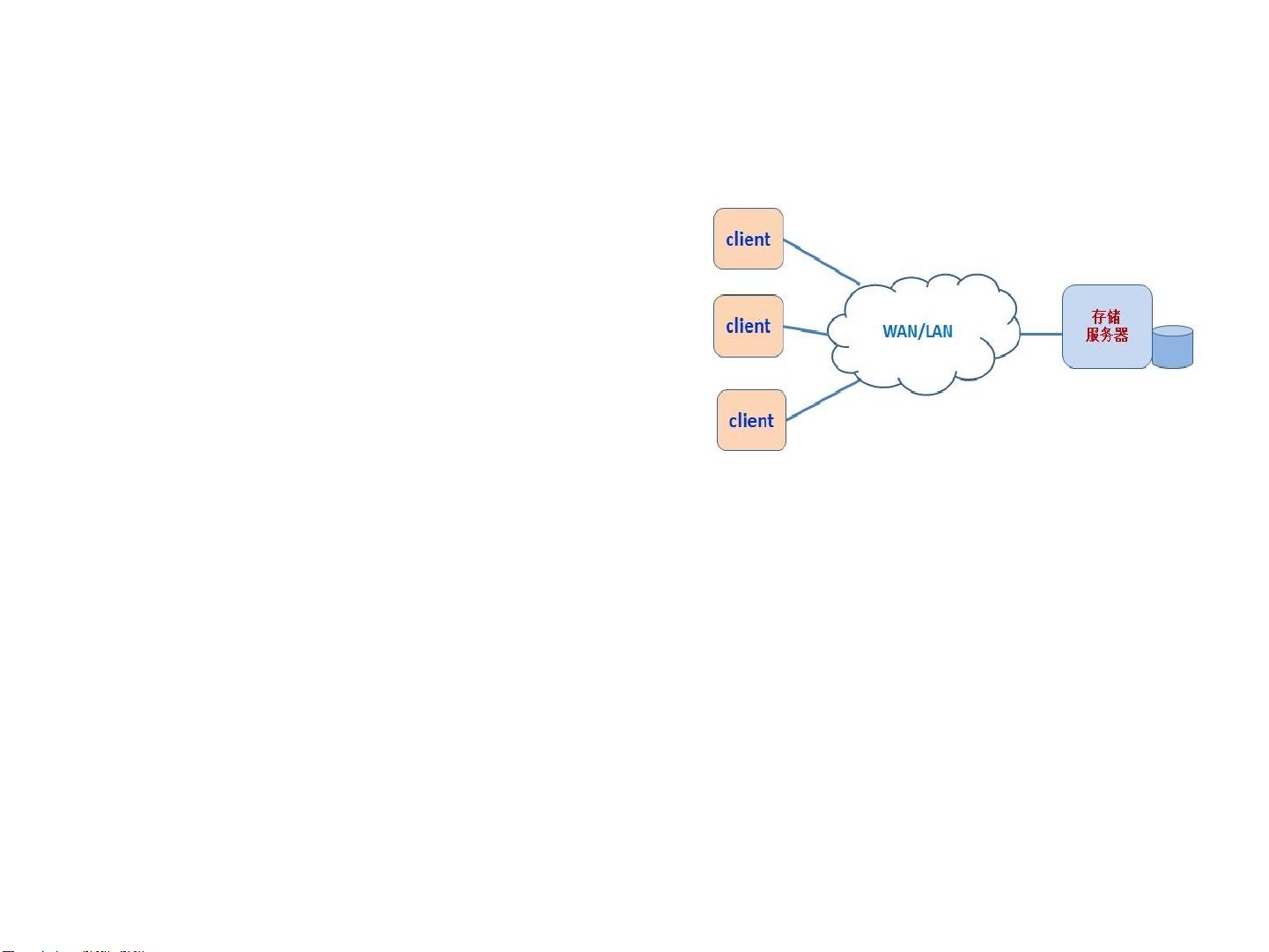
网络文件系统(1980s)
• 历史背景
– 以太网技术蓬勃发展
• 研究重点
– 实现网络环境下的文件共享
– 解决client与文件服务器的交互问题
• 主要成果
– 1981年,IBM发布第一款PC机;
– 1982年,CMU和IBM合作,启动面向PC机资源共享的ITC(Information
Technology Center)项目,研制出了著名的网络文件系统AFS;
– 1983年,Novell发布了网络操作系统Netware;同年,Berkeley发布了支持
TCP/IP的BSD4.2操作系统;
– At&T推出RFS网络文件系统 [H. Chartock, “RFS in SunOS”, USENIX Conference
Proceedings, Summer 1987, 281-290.]
– 1985年,Sun 发布了NFS文件系统 .
• 经典文献
– The ITC distributed file system: principles and design.
– Scale and Performance in a Distributed File System
– Design and Implementation of the Sun Network Filesystem (NFS).
剩余42页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
294 浏览量
180 浏览量
166 浏览量
2021-08-26 上传
173 浏览量
111 浏览量

灵峰
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Wykop Enhancement Suite-crx插件的详细介绍与功能解析
- 易语言项目管理器:源码版本控制与管理
- 适用于Win2003/Win2000的服务器空间开辟工具
- HTK-HMM 3.4.1版本Linux平台压缩包下载指南
- Python实现的票务系统项目概览
- 精通Android NDK:C++编程实战指南
- APM飞控开源项目代码包解析与工具介绍
- anylogic仓储实验案例:简单仿真与叉车运货入库建模
- rcssmonitor-15.1.0:最新版本发布及其功能介绍
- Currency Cop Companion kor-crx插件:韩国PoE网站扩展工具
- 银月服务器工具(SST):Windows平台下便捷的服务器管理方案
- openNAMU:基于Python的Wiki引擎新版本发布
- Android图片凸出效果的实现与应用
- 易语言实现EDB数据库读写操作详解
- 360电脑管家单文件版:全方位电脑管理解决方案
- Java实现MySQL订单与付款表客户分类帐显示方法
