地统计学与机器学习结合:空间半监督学习新框架
62 浏览量
更新于2024-06-18
收藏 21.56MB PDF 举报
"本文主要探讨了地球科学领域中如何运用空间半监督学习框架进行空间预测。随着遥感技术和传感器网络的发展,尽管辅助变量可以获得全面观测,但目标变量的测量仍然有限。在这种背景下,传统的监督学习方法无法充分利用无标签数据。作者提出了一种新的方法,将地统计学与机器学习相结合,利用无标签数据点的地理邻近性和目标变量的空间自相关性生成伪标签。通过地统计条件模拟,他们创建了一组伪标签,以反映伪标记过程的不确定性,并用这些伪标签增强有标签数据,构建伪训练数据集。接着,使用这些伪训练数据集训练监督机器学习模型,从而提高空间预测的准确性。这种方法旨在解决在有限有标签数据条件下,如何更有效地进行空间预测的问题。"
在地球科学中,人工智能的应用日益广泛,特别是对于空间预测任务,如气候变化、地质灾害等的预测。监督学习是一种常用的方法,但它依赖于充足且有标签的数据,这在地球科学实践中往往难以满足。半监督学习作为一种扩展,允许模型在有标签和无标签数据共同作用下学习,尤其适用于数据稀疏的情况。然而,传统半监督学习忽视了空间数据的特性,即空间自相关性和地理分布。
本文提出的地统计学半监督学习框架弥补了这一空白。地统计学在这里起到了关键作用,它利用空间自相关性来估计未观测到的目标变量值。通过条件模拟,可以生成一系列可能的伪标签,这些标签不仅反映了目标变量的空间结构,还包含了不确定性。这些生成的伪标签随后被用来扩展有标签数据集,形成多个伪训练数据集。每个伪训练数据集都会训练一个监督学习模型,最终通过集成学习或投票策略得到一个综合预测结果,提高了模型的泛化能力和预测精度。
此外,该框架强调了无标签数据的潜在价值,尤其是在大规模空间数据中。通过有效利用这些数据,科学家和研究人员可以更高效地进行预测模型的构建,减少对昂贵实地测量的依赖,同时也能够处理更大的数据集,提升预测的覆盖率和可靠性。
这个框架为地球科学研究提供了一个强大的工具,有助于解决因数据采集限制而导致的预测难题。通过结合地统计学的理论和机器学习的算法,它为未来地球科学领域的空间预测研究开辟了新的路径,有望推动相关领域的进步。
165
0
地球科学中的人工智能3(2022)162–178
0
F.Fouedjio和H.Talebi
0
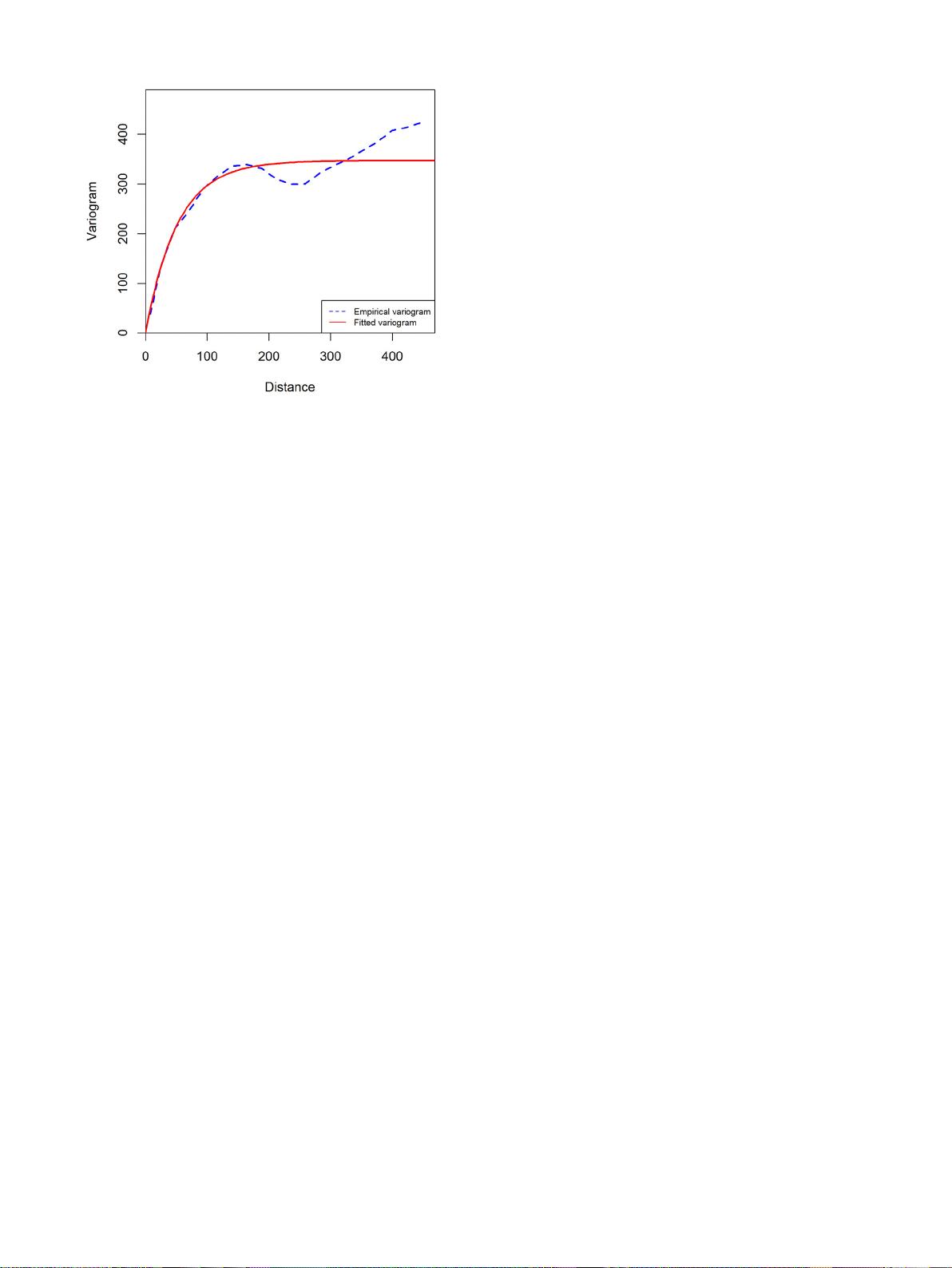
图3.
合成案例研究-原始训练数据集(=1,000)中目标变量的实验和拟合变程图。拟合的变程模型对应于具有
实际范围和坎的各向同性指数模型,分别等于155.010和346.489。
0
ensembleofsimulated(pseudo)labelsisaugmentedbytheobserved
(true)labelstocreateanensembleofpseudotrainingdatasets.A
0
然后在每个伪训练数据集上训练监督机器学习模型,然后对训练好的模型进行聚合
。作为副产品,提供了目标变量的预测不确定性。所提出的地统计半监督学习方法
在合成空间数据上进行了说明,该数据的真实情况在研究区域内随处可得。它被应
用于地球化学制图的实际空间数据。其预测性能与一些经典的监督和半监督学习方
法进行了比较。本文的其余部分组织如下。第2节描述了所提出的地统计半监督学
习方法的不同要素和步骤。第3节说明了所提出的半监督机器学习方法在合成空间
数据上的应用。在第4节中给出了一个真实空间数据的应用示例。第3节和第4节还
包括与经典的监督和半监督学习方法的比较。结论摘要在第5节总结。
0
2.方法论
0
设{()∶∈}为定义在固定连续空间域R(∈N)上的目标变量(连续)。在空间域中穷
尽已知的有个预测(辅助或解释)变量{()=(X1(),…,X())∶∈}。假设我们有标记的
空间数据(1,…,)={((1),(1)),…,((),())},其中{∈}=1,…,表示目标变量的采样位置。(1,
…,)描述了原始的训练数据集。除了标记的空间数据,还有未标记的空间数据(+1,
…,)={(+1),…,()}可用。数据位置{∈}=1,…,将指代标记数据位置,而{∈}=+1,…,将
表示未标记数据位置。我们处理的情况是有相对较少的标记空间数据可用,但有大
量的未标记空间数据可用()。目标是利用标记和未标记的空间数据,试图改进目
标变量在空间域上的空间预测。本节描述了实施所提出的地统计半监督学习用于空
间预测的不同步骤和要素。实施是在R平台上进行的(R核心团队,2021年)。
0
2.1.生成伪训练数据
0
利用未标记数据的基本方法首先是预测它们的标签,并将最有信心的预测标签添加
回标记数据。这个过程在经典的半监督学习方法中被称为伪标记,比如自训练和协
同训练(VanEngelenand
Hoos,2020年)。在这些方法中,伪标记包括首先在标记数据上训练监督机器学
习模型。然后,使用训练好的机器学习模型的预测结果生成额外的标记数据。最后
,原始的标记数据(观察到的)和伪标记数据(生成的)被合并用于最终模型的重
新训练。之所以使用伪标记这个术语,是因为这些伪标签不是真实的(观察到的)
标签。我们采用了一种不同的策略来生成伪标签。在空间上下文中,可以利用目标
变量的空间自相关性在未标记数据位置生成更有信心的伪标签。空间自相关性是指
地理学的Tobler第一定律(Tobler,1970年),意味着一切都与一切相关,但附
近的事物比远处的事物更相关。在存在空间自相关性的情况下,更接近的事物往往
更可预测,变化性更小。相反,较远的事物往往更难预测,相关性更小。因此,并
非所有未标记数据位置都能以高置信度标记。对于距离标记数据位置太远的未标记
数据位置的伪标签的不准确性可能会引入错误到机器学习模型中,并导致其退化。
因此,并非所有未标记数据位置对模型训练都有益。我们的方法
剩余16页未读,继续阅读
2021-05-26 上传
2021-05-06 上传
2018-12-16 上传
2021-09-24 上传
2021-02-15 上传
点击了解资源详情

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
