Python实现K-Means聚类算法:《机器学习实战》Ch10详解
103 浏览量
更新于2024-08-30
收藏 225KB PDF 举报
本篇学习笔记是关于《机器学习实战》中的第十章,着重讲解如何利用K-Means聚类算法对未标注数据进行分组。K-Means是一种基于密度的、无监督的聚类算法,其核心思想是通过迭代过程,将数据集划分为k个互不相交的簇,每个簇由距离其质心(类中心)最近的数据点组成,质心则由该簇内所有数据点的均值确定。
学习过程包括以下几个关键步骤:
1. **K-Means简介**:
- K-Means算法因其简单易用和广泛应用而著名,它从原始数据中随机选择k个点作为初始质心(类中心)。
- 算法的核心在于不断迭代:计算每个数据点到各个质心的距离,将数据点分配给最近的质心,然后更新质心为该簇内所有点的均值,直至簇不再改变或达到预设的迭代次数。
2. **代码实现步骤**:
- **数据集读入**:通过`loadDataSet`函数读取包含两个特征值的文本文件(如testSet.txt),每一行数据被分割成浮点数列表,存储在`dataMat`中。
- **距离计算**:使用欧氏距离公式(`distCal`函数),计算两点之间的距离,这在K-Means算法中至关重要,因为它决定了数据点被分配到哪个簇。
3. **构建随机质心**:初始时,可以选择随机数据点作为质心,或者采用更复杂的方法,如K-Means++,以减少初始质心选择对最终结果的影响。
4. **数据聚类**:对于每个数据点,计算其与所有质心的距离,将其分配到最近的质心所在的簇。这一步骤构成了K-Means的主要迭代循环。
5. **改进算法**:
- 提到了一种优化策略,即采用二分法(二分搜索),用于在找到最优k值时提高效率,但具体实现没有在提供的部分内容中详细说明。
通过对K-Means聚类算法的理解和Python代码的实践,学习者可以掌握如何对未标注数据进行自动分类,并理解聚类算法在数据分析和挖掘中的作用。此外,回顾和实践《机器学习实战》中的案例有助于加深对理论知识的理解和应用能力的提升。
『『ML』利用』利用K-Means聚类算法对未标注数据分组聚类算法对未标注数据分组——《机器学习实战》学习笔记《机器学习实战》学习笔记
((Ch10))
本节用Python实现K-Means算法,对未标注的数据进行聚类。主要参考《机器学习实战》—— Peter Harrington著。
导航导航K-Means简介代码实现(一)数据集读入(二)距离计算(三)构建随机质心(四)数据聚类(五)完整代码改进:采用二分法(一)简介(二)代码最后
K-Means简介简介
这里参考了大三专业课老师的PPT,现在回过头来看,老师当初讲得特别透彻,可惜没好好听,老师dbq (*>﹏<*)。
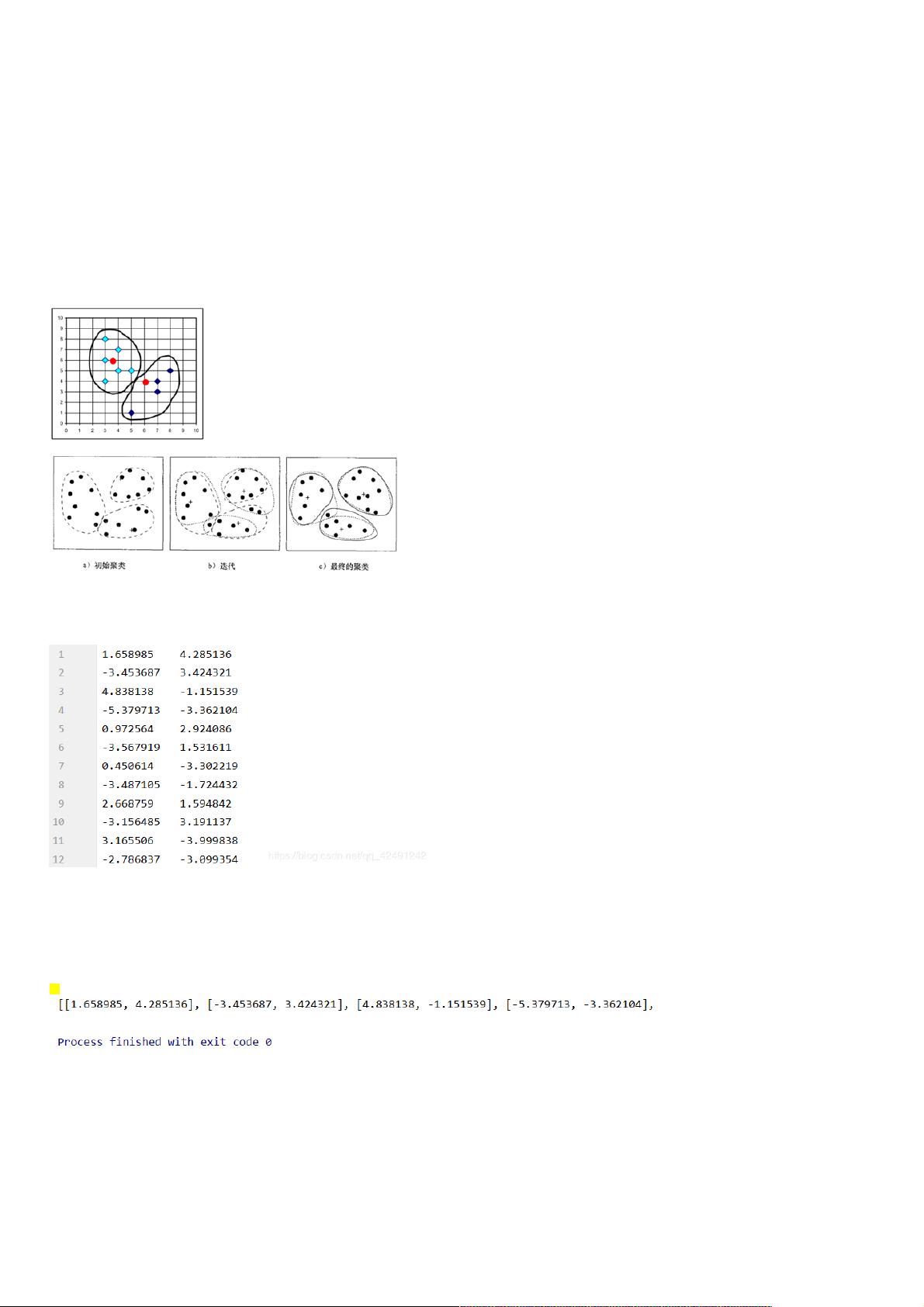
k-means算法,也被称为k-平均或k-均值算法,是一种使用最广泛的聚类算法。根据个体到每个类中心的距离进行划分,而类中心用类中所有个体的均值来度量。
思路及步骤:
随机或按某种策略从n个对象中选择k个对象作为初始的类中心(Centriod,Mean Point);
计算每个对象与这k个类中心的距离;
将每个对象划分/分配到与其距离最近的类中心所在的类中;并重新计算每个类的类中心。
回到第2步,直到和前一次划分/分配结果无差异,停止。
代码实现代码实现
(一)数据集读入(一)数据集读入
先查看一下 testSet.txt 数据集的格式,每一行有两个数据,用空格间隔开。
我们首先要将每一行用空格 split , 用 map 函数进行数值类型转化(转为 float 型),再保存到一个名为 dataMat 的列表中。代码如下所示:
# 读入数据,保存到列表
def loadDataSet(fileName):
dataMat = [] with open(fileName, "r", encoding='utf-8') as fn:
for line in fn.readlines():
curLine = line.strip().split(' ')
fltLine = list(map(float, curLine)) # 数值类型转化,map()会根据提供的函数对指定序列做映射
dataMat.append(fltLine)
return dataMat
注:map ( ) 函数在 Python 2.x 返回列表,在 Python 3.x 返回迭代器,因此代码中用list()进行转换。效果如下:
(二)距离计算(二)距离计算
采用欧式距离进行计算,也可以使用其他计算方法。
# 计算距离
def distCal(vecA, vecB):
return np.sqrt(np.sum(np.power(vecA - vecB, 2)))
# vecA, vecB都为数组的形式,类似于[1 2] # power(x1, x2)数组的元素分别求n次方。x2可以是数字,也可以是数组,但是x1和x2的列数要相同。
(三)构建随机质心(三)构建随机质心
这一步用来随机生成质心。
质心的表示与原数据相同,原数据保存的格式类似为[[1, 4], [-3, 3], [4, -1], ...] ,因此首先获取到每一行的数据有几个,用 shape [1] 来获取,得到 n 为2。
接下来生成 k * n 的矩阵,用来保存 k 个质心。
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
348 浏览量
1636 浏览量
626 浏览量
668 浏览量
9398 浏览量
1497 浏览量
2024-05-30 上传

weixin_38584058
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新冠疫情数据可视化分析展示
- 网页文字闪烁效果实现与Java实战项目源码下载
- Swift开发中用于监控文件变化的微型框架
- 深入理解MiniShell开发与C语言编程实践
- 品牌占据消费者心智的快速方法
- MATLAB相机标定与参数导出实用程序
- 掌握机器学习分类模型,使用scikit-learn实践教程
- 3D图形编程中的Weiler-Atherton算法实现详解
- Discuz插件实现论坛高效管理与互动
- Java实战:JQuery浮动窗口与阿里云服务器上运行Java源码
- Swift中FMDB的基本操作教程:增删改查详解
- 企业文化核心价值与塑造策略解析
- 构建本地API的Android JSON Server实践指南
- Java开发者的Git工具包——java-commons-git-utils
- 粉色商务型企业虚拟网站CSS网页模板下载
- 探索DS实验:深入理解数据结构实践
