机器学习实战:KNN算法应用与参数优化
下载需积分: 13 | DOC格式 | 710KB |
更新于2024-08-04
| 17 浏览量 | 举报
本篇文档主要介绍了机器学习中的KNN分类实验,结合Python库sklearn进行实战操作。实验的目标在于深入理解KNN分类的基本原理,并通过实践掌握如何使用该算法以及调整其参数。首先,实验要求参与者在计算机上实现KNN分类器,通过生成特定分布的数据集来检验归一化方法(最值归一化和均值方差归一化)对数据处理的影响。
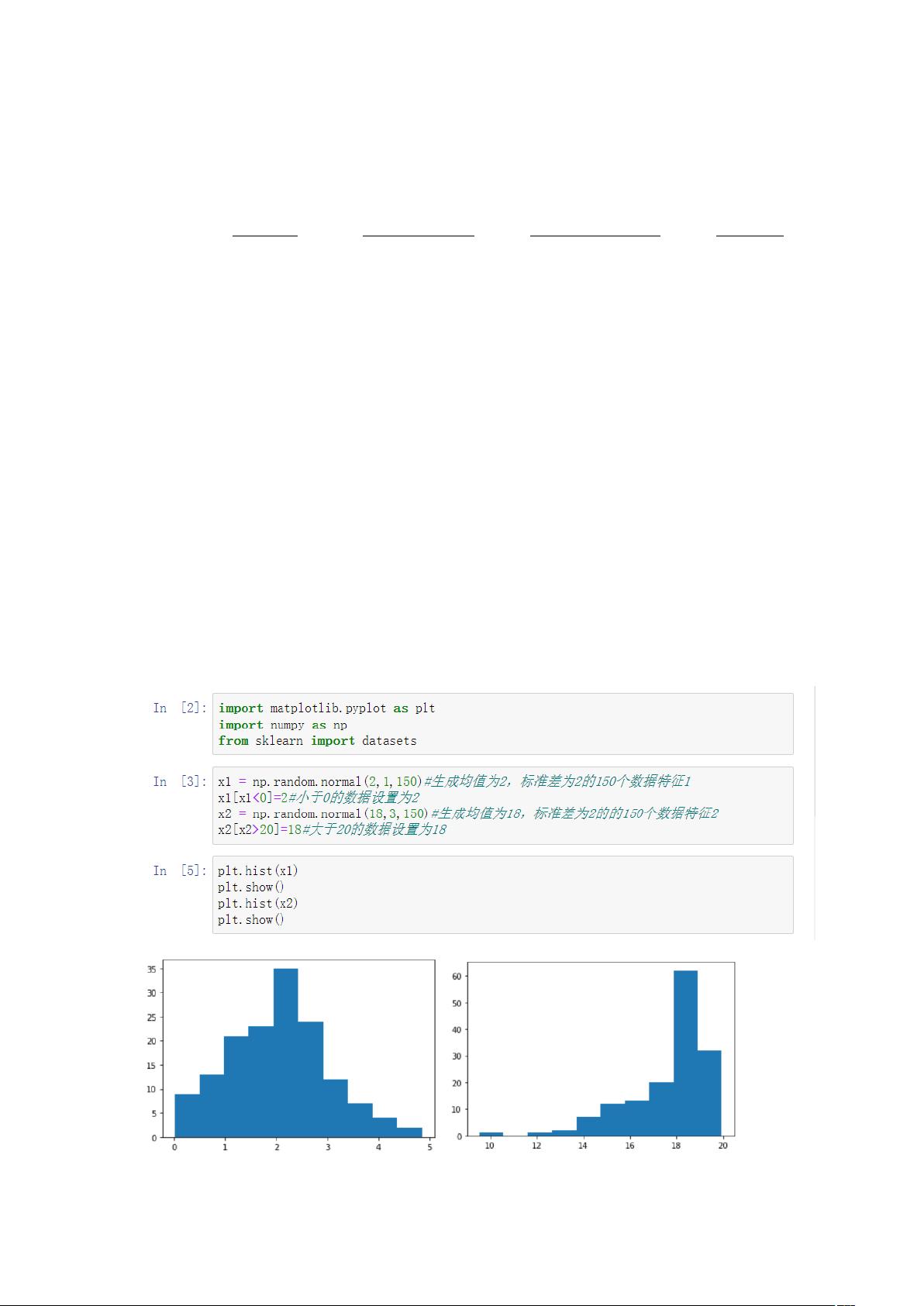
实验的第一部分,创建了两个特征,一个服从均值2,标准差2的分布,另一个服从均值18,标准差2的分布,然后对它们进行了归一化处理,观察了两种方法对数据分布的影响。最值归一化虽然实现了数据标准化,但无法解决特征偏移问题;而均值方差归一化则使数据趋于正态分布,有助于提高模型性能。
接下来,文档指导参与者利用KNN算法对鸢尾花花瓣数据集进行分类,通过改变K值来探索其对分类结果的影响。较小的K值可能导致过拟合,因为模型过于依赖邻近数据点,而较大的K值可能导致欠拟合,无法捕捉数据的细节。实验还比较了不同的距离权重策略,如无权重、均匀权重(distance)和加权距离(曼哈顿距离、区域距离等),这些策略在不同K值下对分类准确性与模型复杂性的影响显著。
总结来说,本实验不仅涉及理论知识的运用,还强调了实践操作和问题分析的重要性,通过实际案例展示了KNN算法的调参技巧和归一化技术对模型性能的影响。参与者将在这个过程中提升对机器学习分类流程的理解,学会如何根据实际问题选择合适的参数和归一化方法。
实验 1 机器学习基础实验
姓名: 赵景潮 班级: 20200512 学号: 2020028120 成绩:
一、实验要求
在计算机上验证和测试 KNN 分类实验,以及 sklearn 里面的 KNN 分类算法。
二、实验目的
1、掌握 KNN 分类的原理
2、能够使用 KNN 分类算法和设置参数;
3、熟练机器学习分类的流程;
三、实验内容
实验步骤
1. 请生成均值为 2,标准差为 2 的 150 个数据特征 1(小于 0 的数据设置为 2),同时
生成均值为 18,标准差为 2 的数据特征 2(大于 20 的数据设置为 18),分别对两个特征进
行最值归一化和均值方差归一化,观察两种归一化带来的差异。
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐




「已注销」
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 揭秘嵌入式Linux性能:深度解析与哲思
- Hibernate开发指南:数据库映射到Pojo的实战教程
- Symbian OS 设计模式全书:智能手机软件基石
- .NET面试必备知识点大全
- 利用CPU时间戳实现高精度计时方法
- Pentium处理器的分支预测策略与优化
- InfoQ中文站:深入浅出Struts2电子书-免费在线学习资源
- CVS并发版本系统中文手册v1.12.9:团队开发必备
- UML初学者教程:实例解析类与关系
- Seam深度集成框架:简化企业级应用开发
- 掌握复杂指针教程:解析与实例
- TestInside 310-065 Java SE 6.0 Programmer题库下载与编程练习
- Java与SAP R/3系统的集成技术探索
- 理解银行家算法:C++实现详解
- C# 3.0编程规范详解:从HelloWorld到结构与接口
- 大规模网络异常检测:滤波与统计方法的融合策略
