HBase在阿里搜索:核心存储与高吞吐实践
66 浏览量
更新于2024-08-27
收藏 377KB PDF 举报
"HBase在阿里搜索中的应用实践"
在阿里搜索中,HBase扮演着至关重要的角色,自2010年以来,历经十多个版本的迭代与优化,尤其是在社区版本1.1.3之后,其性能得到了显著提升,避免了1.1.2版本存在的性能问题。目前,阿里搜索的HBase集群规模宏大,节点数超过3000个,最大的单一集群超过1500个,整个阿里集团的节点数更是远超这一数字。在2019年双11期间,阿里搜索离线集群展现了强大的处理能力,每秒访问峰值高达4000万次,单台机器在一秒钟内的吞吐峰值也能达到10万次,即使在CPU使用率超过70%的高压情况下,单个CPU核心仍能支持8000+QPS,显示出HBase卓越的高并发处理能力。
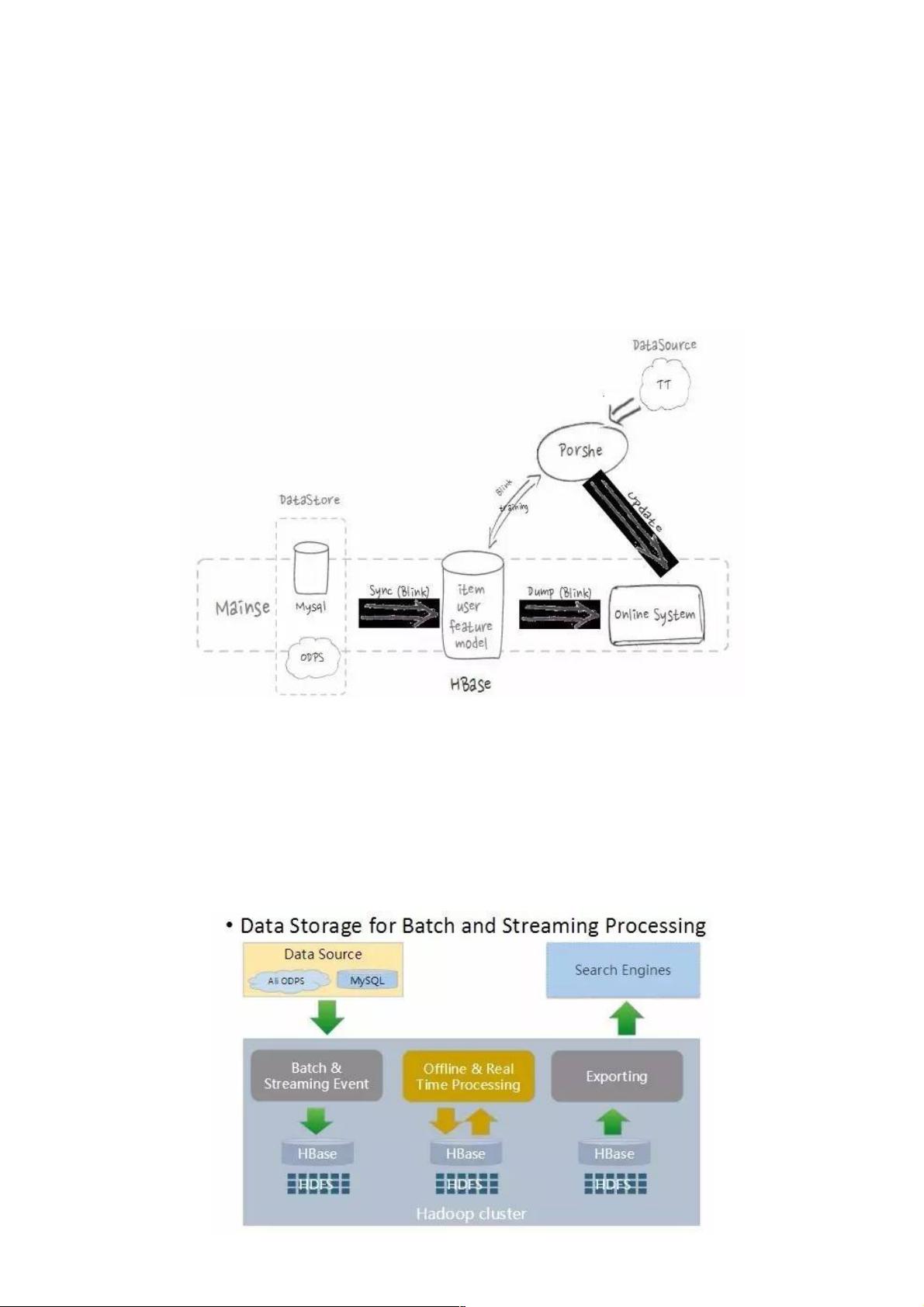
作为阿里搜索的核心存储系统,HBase与计算引擎紧密结合,主要用于支持搜索和推荐业务。在索引构建阶段,HBase接收来自线上MySQL等数据库的商品和用户数据,通过流式处理导入,为搜索引擎构建索引提供数据基础。在推荐环节,Porshe机器学习平台将模型和特征数据存储在HBase,同时实时存储用户点击数据,通过在线训练更新模型,提升推荐系统的准确性和效果。
首先,我们来看HBase在索引构建中的应用。淘宝和天猫的线上数据源丰富多样,包括各个店铺和用户的实时活动。HBase不仅负责夜间全量数据的批量导出,供搜索引擎构建全量索引,还实时接收并更新线上变化的数据,确保增量索引的及时构建,实现搜索结果的秒级更新。这种机制确保了用户能够即时看到库存、新品等信息的变更。
其次,HBase在机器学习场景中也有重要应用。举例来说,在用户搜索三千元手机但未找到满意选项的情况下,机器学习模型会根据用户行为调整搜索结果排序,将符合预算的手机提前展示。这就需要HBase存储和快速响应模型训练及特征数据,确保推荐的实时性和准确性。
总结起来,HBase在阿里搜索的应用实践充分展示了其在大规模数据存储、高并发处理和实时数据更新方面的优势,是支撑阿里搜索和推荐系统高效运作的关键技术之一。通过与流式计算引擎的协同工作,HBase在索引构建和机器学习等场景中发挥着不可替代的作用,确保了阿里巴巴集团在电商领域的快速响应能力和用户体验。
HBase在阿里搜索中的应用实践在阿里搜索中的应用实践
HBase 在阿里搜索的历史、规模和服务能力
历史:阿里搜索于 2010 年开始使用 HBase,从最早到目前已经有十余个版本。目前使用的版本是在社区版本的基础上经过大
量优化而成。社区版本建议不要使用 1.1.2版本,有较严重的性能问题,1.1.3 以后的版本体验会好很多。
集群规模:目前,仅在阿里搜索节点数就超过 3000 个,最大集群超过 1500 个。阿里集团节点数远远超过这个数量。
服务能力:去年双11,阿里搜索离线集群的吞吐峰值一秒钟访问超过 4000 万次,单机一秒钟吞吐峰值达到 10 万次。还有在
CPU 使用量超过 70% 的情况下,单 cpu core 还可支撑 8000+ QPS。
HBase 在阿里搜索的角色和主要应用场景
角色:HBase 是阿里搜索的核心存储系统,它和计算引擎紧密结合,主要服务搜索和推荐的业务。
上图是 HBase 在搜索和推荐的应用流程。在索引构建流程中,会从线上 MySQL 等数据库中存储的商品和用户产生的所有线
上数据,通过流式的方式导入到 HBase 中,并提供给搜索引擎构建索引。
在推荐流程中,机器学习平台 Porshe 会将模型和特征数据存储在 HBase 里,并将用户点击数据实时的存入 HBase,通过在
线 training 更新模型,提高线上推荐的准确度和效果。
应用场景一
索引构建
淘宝和天猫有各种各样的的线上数据源,这取决于淘宝有非常多不同的线上店铺和各种用户访问。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-03-18 上传
2019-08-28 上传
2012-07-15 上传
2013-12-23 上传
点击了解资源详情
点击了解资源详情

weixin_38710557
- 粉丝: 3
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







