Python数据分析实战:处理缺失值与统计操作
5 浏览量
更新于2024-07-15
收藏 798KB PDF 举报
"这篇文档是关于使用Python进行数据分析的基础示例,主要展示了如何处理和分析USA.gov通过Bitly收集的匿名用户数据。涉及到的数据包括时区(tz)信息和浏览器、设备与应用(a)信息。文章中展示了如何处理缺失值和空值,以及如何进行数据归一化和创建透视表来获取特定指标的统计结果。"
在Python数据分析中,Pandas库是一个不可或缺的工具。在本示例中,首先导入了json、numpy、pandas和matplotlib.pyplot库。`json.loads()`函数用于解析JSON格式的数据,`pd.DataFrame()`则将解析后的数据转化为DataFrame对象,便于进一步操作。
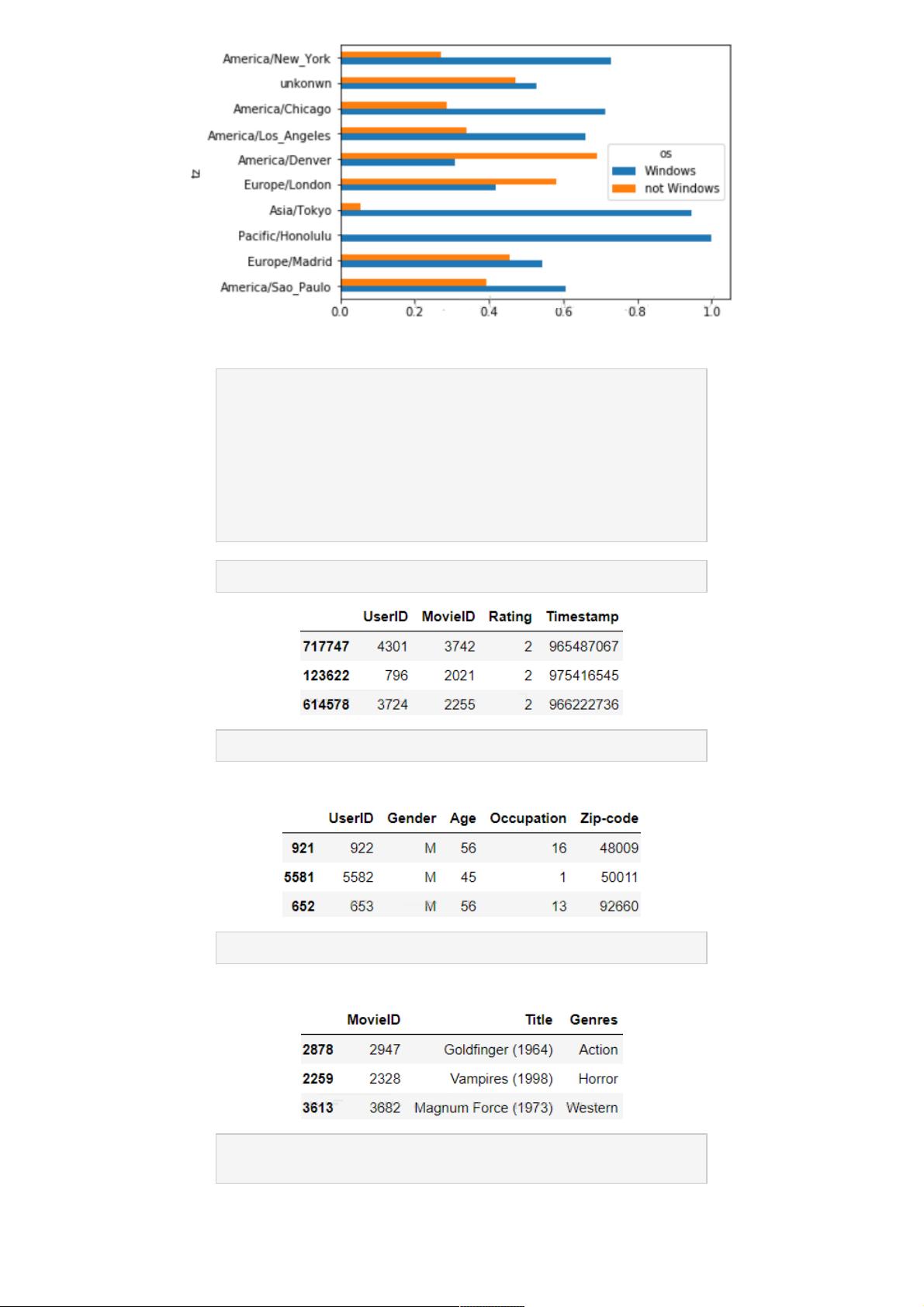
针对tz列(时区信息)的数据清洗,使用了`df.info()`查看数据概况,发现存在缺失值。通过`fillna()`方法填充缺失值,用'missing'表示。然后,使用`value_counts()`统计每个时区出现的频率,发现有空值,将其设置为'unkonwn'。通过`plot.barh()`绘制水平条形图展示前10个最常见时区的分布。
在处理'a'列(浏览器、设备与应用信息)时,首先对数据进行抽样查看,然后为了统计'Windows'与非'Windows'的相关量,使用条件筛选去除缺失值,并创建新列"os"。利用`str.contains()`检查'a'列是否包含'Windows'字符串,通过`np.where()`函数创建"os"列,将满足条件的行标记为'Windows',否则标记为'notWindows'。最后,删除原始'a'列以简化数据结构。
接下来,使用`groupby()`对数据进行分组,按照'tz'和'os'两列进行聚合,然后使用`size()`计算每组的大小,得到tz-os的计数。这为进一步分析提供了基础,例如,可以计算出在不同时区和操作系统组合下的用户数量。
若要探究不同性别对各电影的平均打分,可以使用透视表(pivot table)。Pandas的`pivot_table()`函数可以方便地实现这一操作,它允许我们按指定列进行分组,计算其他列的统计值,如平均分,同时可以处理冷门作品(评价次数较少的电影),提供更为清晰的视角。
这个基础示例展示了Python数据分析的基本流程,包括数据预处理、特征提取、数据可视化和统计分析,是学习和实践数据分析的良好起点。
# MovieLens
rating_col=['UserID','MovieID','Rating','Timestamp']
user_col=['UserID','Gender','Age','Occupation','Zip-code']
movie_col=['MovieID','Title','Genres']
ratings=pd.read_table ('datasets/movielens/ratings.dat',
header=None,sep='::',names=rating_col,engine='python')
users=pd.read_table ('datasets/movielens/users.dat',
header=None,sep='::',names=user_col,engine='python')
movies=pd.read_table ('datasets/movielens/movies.dat',
header=None,sep='::',names=movie_col,engine='python')
ratings.sample(3)
users.sample(3)
movies.sample(3)
data=pd.merge(pd.merge(ratings,users),movies)
data.sample(3)
剩余19页未读,继续阅读
2021-11-12 上传
2016-10-13 上传
2020-12-21 上传
2020-09-17 上传
2020-12-22 上传
2020-12-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情









