深度学习中的卷积神经网络类别不平衡问题研究与方法比较
需积分: 48 133 浏览量
更新于2024-07-17
1
收藏 3.08MB PDF 举报
本文是一篇于2017年发表的综述论文,关注的是卷积神经网络(Convolutional Neural Networks, CNNs)中的类不平衡问题。类不平衡是指在机器学习任务中,各类样本数量差异显著,这在深度学习领域中是一个普遍存在的挑战,尽管在传统机器学习中已受到广泛研究,但在深度学习背景下却相对较少被系统性地探讨。
研究者Mateusz Buda、Atsuto Maki和Maciej Mazurowski针对这个问题进行了深入的研究,他们选择MNIST、CIFAR-10和ImageNet这三个具有不同复杂度的基准数据集来进行实验。这些数据集分别代表了手写数字识别(相对简单)、图像分类(稍具复杂性)和大规模视觉识别(极高复杂性)的不同场景,使得研究结果具有广泛的适用性。
在实验中,他们着重考察了类不平衡对CNNs分类性能的影响,并对比了四种常用的方法来解决这个问题:过采样(Oversampling)、欠采样(Undersampling)、两阶段训练(Two-phase Training)以及阈值补偿(Thresholding)。过采样是通过增加少数类样本数量来平衡类别分布,欠采样则是减少多数类样本;两阶段训练则是在训练过程中先针对少数类优化,再整体调整模型;而阈值补偿则是通过调整决策边界,使得模型更倾向于预测少数类。
他们的研究发现,不同的方法在不同数据集和复杂性级别下表现各异,没有一种通用的最佳解决方案。例如,对于简单的MNIST,某些方法可能效果较好,而在大规模的ImageNet中,可能需要更为复杂的策略。因此,选择合适的处理策略取决于具体的应用场景和数据特性。
此外,论文还讨论了类不平衡问题对模型泛化能力的影响,以及如何权衡过拟合风险和欠拟合问题。通过这些分析,研究人员希望为深度学习社区提供一个理解和应对类不平衡问题的框架,以便更好地设计和优化CNNs在实际应用中的性能。
这篇综述为深度学习领域的研究者和实践者提供了宝贵的参考,强调了在处理高维复杂数据时,理解并有效地解决类不平衡问题对于提高CNNs性能的重要性。同时,它也提醒我们,在实际应用中需要根据具体情况灵活选择和调整处理策略,以达到最佳的分类效果。
3 Experiments
3.1 Forms of imbalance
Class imbalance can take many forms particularly in the context of multiclass classi-
fication, which is typical in CNNs. In some problems only one class might be under-
represented or overrepresented and in other every class will have a different number of
examples. In this study we define and investigate two types of imbalance that we believe
are representative of most of the real-world cases.
The first type is step imbalance. In step imbalance, the number of examples is equal
within minority classes and equal within majority classes but differs between the majority
and minority classes. This type of imbalance is characterized by two parameters. One is
the fraction of minority classes defined by
µ =
|{i ∈ {1, . . . , N } : C
i
is minority}|
N
, (1)
where C
i
is a set of examples in class i and N is the total number of classes. The other
parameter is a ratio between the number of examples in majority classes and the number
of examples in minority classes defined as follows.
ρ =
max
i
{|C
i
|}
min
i
{|C
i
|}
(2)
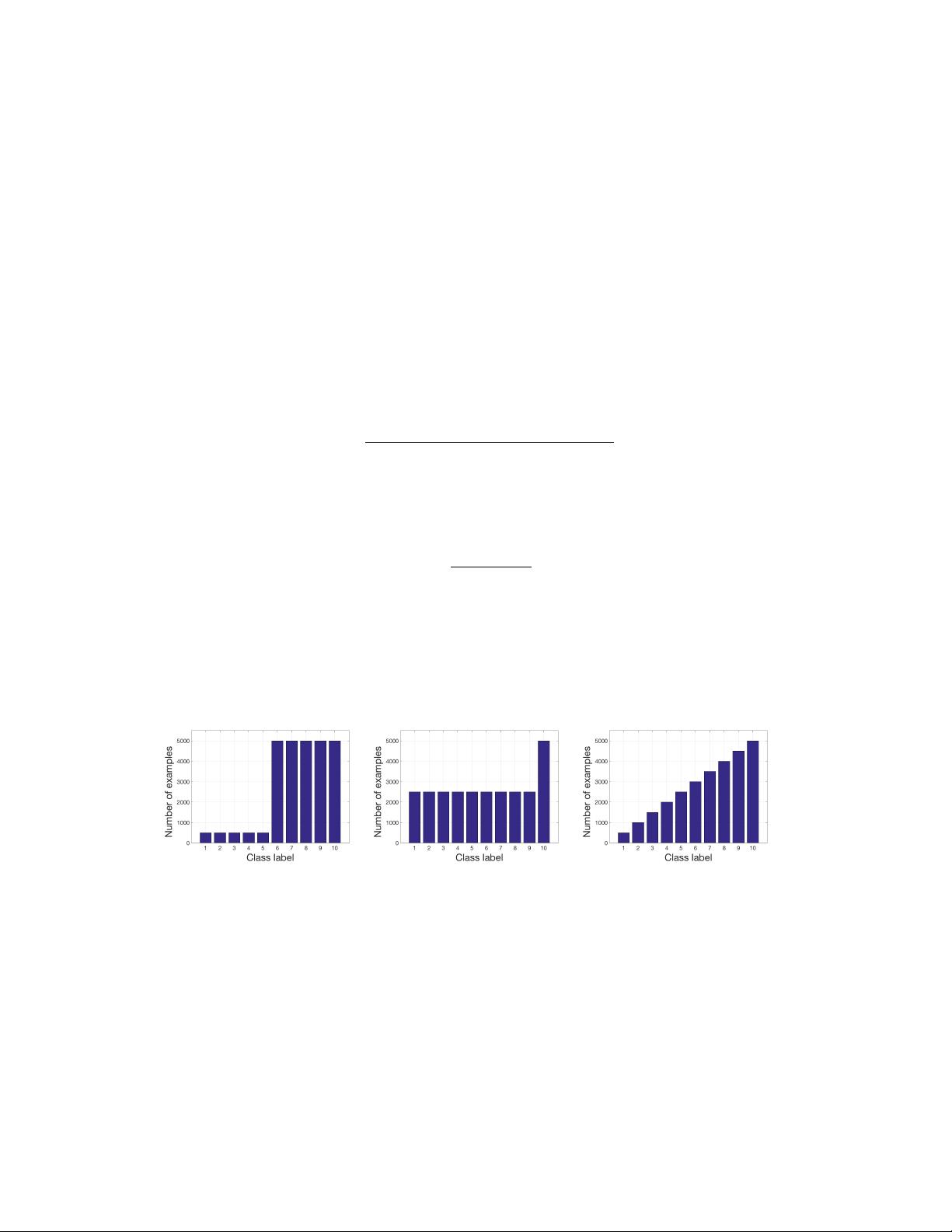
An example of this type of imbalance is the situation when among the total of 10 classes,
5 of them have 500 training examples and another 5 have 5 000. In this case ρ = 10 and
µ = 0.5, as shown in Figure 1a. A dataset with the same number of examples in total
that has smaller imbalance ratio, corresponding to parameter ρ = 2, but more classes
being minority, µ = 0.9, is presented in Figure 1b.
(a) ρ = 10, µ = 0.5 (b) ρ = 2, µ = 0.9 (c) ρ = 10
Figure 1: Example distributions of imbalanced set together with corresponding values of param-
eters ρ and µ for step imbalance (a - b) and ρ for linear imbalance (c).
The second type of imbalance we call linear imbalance. We define it with one param-
eter that is a ratio between the maximum and minimum number of examples among all
classes, as in Equation 2 for imbalance ratio in step imbalance. However, the number of
examples in the remaining classes is interpolated linearly such that the difference between
consecutive pairs of classes is constant. An example of linear imbalance distribution with
ρ = 10 is shown in Figure 1c.
5
剩余22页未读,继续阅读
276 浏览量
358 浏览量
234 浏览量
2021-09-26 上传
2021-09-25 上传
点击了解资源详情
2021-09-01 上传
2021-09-25 上传
2021-09-25 上传

tianrolin
- 粉丝: 99
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易二维码签到系统:会议活动签到解决方案
- Ceres库与SDK集成指南:C++环境配置及测试程序
- 深入理解Servlet与JSP技术应用与源码分析
- 初学者指南:掌握VC摄像头抓图源代码实现
- Java实现头像剪裁与上传的camera.swf组件
- FileTime 2013汉化版:单文件修改文件时间的利器
- 波斯语话语项目:实现discourse-persian配置指南
- MP4视频文件数据恢复工具介绍
- 微信与支付宝支付功能封装工具类介绍
- 深入浅出HOOK编程技术与应用
- Jettison 1.0.1源码与Jar包免费下载
- JavaCSV.jar: 解析CSV文档的Java必备工具
- Django音乐网站项目开发指南
- 功能全面的FTP客户端软件FlashFXP_3.6.0.1240_SC发布
- 利用卷积神经网络在Torch 7中实现声学事件检测研究
- 精选网站设计公司官网模板推荐
