Python打造大数据预测可视化集成工具
PDF格式 | 160KB |
更新于2024-09-01
| 201 浏览量 | 举报
"Python制作数据预测集成工具,使用Python的sklearn、numpy、matplotlib、Pillow、Pandas和Tkinter等模块,构建可视化的大数据预测工具,特别适合大数据预测和决策支持。"
在大数据预测领域,Python作为一种强大的编程语言,提供了丰富的库和工具,使得数据预处理、建模、评估和可视化变得更加便捷。本教程主要关注如何利用Python构建一个数据预测集成工具,该工具可以帮助用户进行大数据预测,尤其适用于非结构化数据的处理。
首先,大数据预测的核心在于利用大量的、多维度的数据来提升预测的准确性。相比于传统的小数据集,大数据预测能够处理更多的非结构化数据,提供更全面的视角,从而提高预测效率。大数据预测的思维方式强调实样而非抽样,预测效率而非精确性,以及寻找相关关系而非因果关系。
在实现这个集成工具时,会用到以下Python库:
1. **sklearn**: Scikit-learn 是一个广泛使用的机器学习库,它包含了多种预测模型,如线性回归、决策树、随机森林等。在这个例子中,选择了简单的多元回归作为拟合数据的算法。
2. **numpy**: NumPy 提供了高效的数值计算功能,对于矩阵运算和数据处理非常有用。
3. **matplotlib**: 这是一个用于数据可视化的库,可以帮助我们展示模型的拟合效果,以便于理解和解释预测结果。
4. **Pillow**: 用于加载和处理图像,如果需要在GUI界面中显示图像或图表,Pillow库是必不可少的。
5. **Pandas**: Pandas 提供了高效的数据结构 DataFrame,方便地读取和处理CSV等文件格式的数据。
6. **Tkinter**: Python的标准GUI库,用于创建用户交互界面,使得用户可以方便地选择文件、查看预测结果等。
在实现过程中,首先通过Tkinter的`filedialog.askopenfilename()`函数让用户选择数据文件,然后使用Pandas的`read_excel()`或`read_csv()`函数读取数据。接下来,数据预处理可能包括清洗、缺失值处理、特征工程等步骤。在本例中,选择多元回归模型进行训练,通过sklearn的`fit()`方法拟合数据。训练完成后,可以使用`predict()`方法进行预测,并用matplotlib进行结果可视化。
最后,通过Tkinter创建GUI窗口,展示数据加载、模型训练、预测结果等信息,使用户能够直观地了解预测过程和结果。这种集成工具的创建,极大地简化了大数据预测的流程,提高了工作效率,对于数据分析人员和决策者来说是非常有价值的工具。
Python制作数据预测集成工具(值得收藏)制作数据预测集成工具(值得收藏)
主要介绍了Python如何制作数据预测集成工具,帮助大家进行大数据预测,感兴趣的朋友可以了解下
大数据预测是大数据最核心的应用,是它将传统意义的预测拓展到“现测”。大数据预测的优势体现在,它把一个非常困难的预测问题,转
化为一个相对简单的描述问题,而这是传统小数据集根本无法企及的。从预测的角度看,大数据预测所得出的结果不仅仅是用于处理现
实业务的简单、客观的结论,更是能用于帮助企业经营的决策。
在过去,人们的决策主要是依赖 20% 的结构化数据,而大数据预测则可以利用另外 80% 的非结构化数据来做决策。大数据预测具有更
多的数据维度,更快的数据频度和更广的数据宽度。与小数据时代相比,大数据预测的思维具有 3 大改变:实样而非抽样;预测效率而非
精确;相关关系而非因果关系。
而今天我们就将利用python制作可视化的大数据预测部分集成工具,其中数据在这里使用一个实验中的数据。普遍性的应用则直接从文
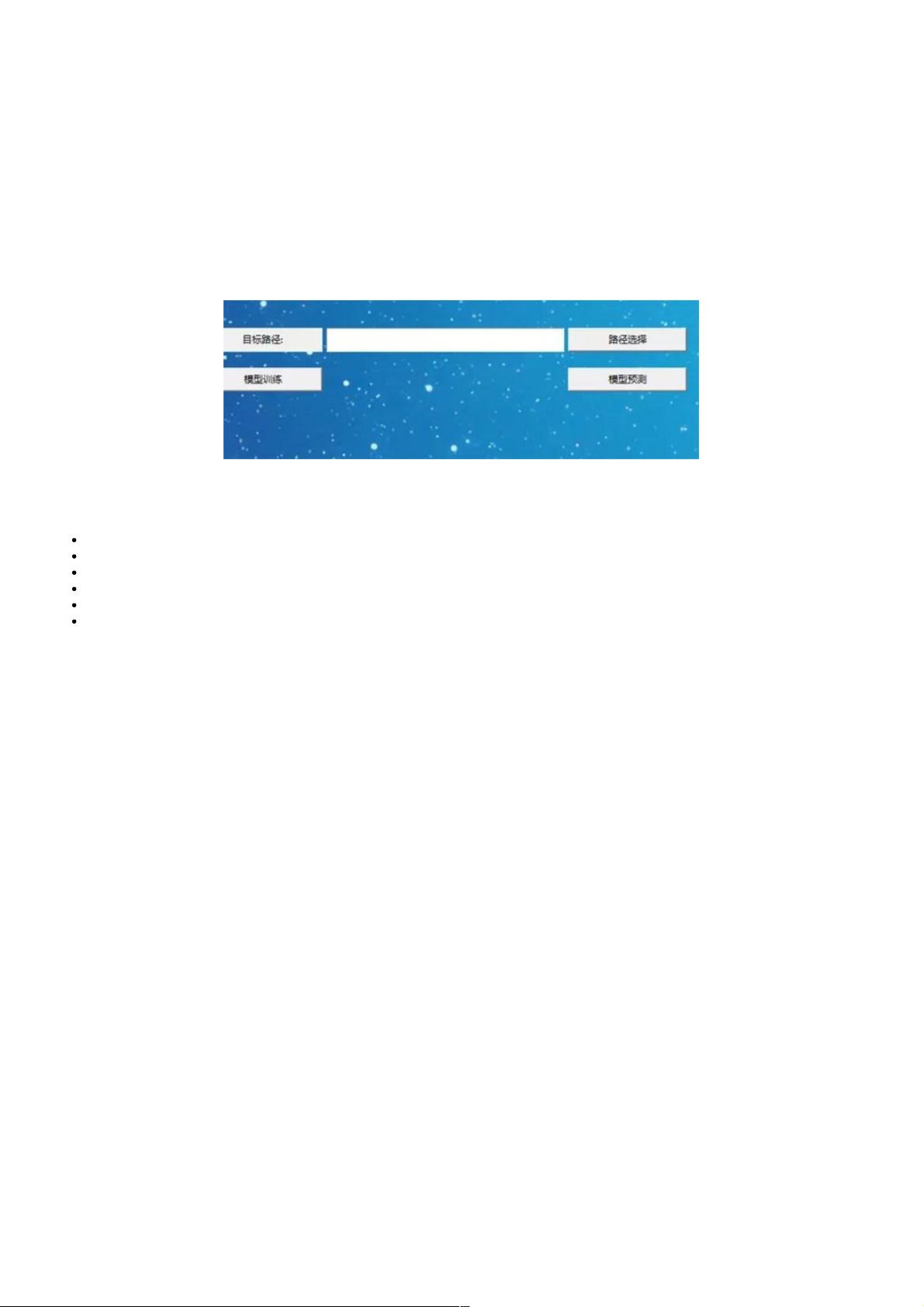
件读取即可。其中的效果图如下:
实验前的准备实验前的准备
首先我们使用的python版本是3.6.5所用到的模块如下:
sklearn模块用来创建整个模型训练和保存调用以及算法的搭建框架等等。
numpy模块用来处理数据矩阵运算。
matplotlib模块用来可视化拟合模型效果。
Pillow库用来加载图片至GUI界面。
Pandas模块用来读取csv数据文件。
Tkinter用来创建GUI窗口程序。
数据的训练和训练的数据的训练和训练的GUI窗口窗口
经过算法比较,发现这里我们选择使用sklearn简单的多元回归进行拟合数据可以达到比较好的效果。
(1)首先是是数据的读取,通过设定选定文件夹函数来读取文件,加载数据的效果:
'''选择文件功能'''
def selectPath():
# 选择文件path_接收文件地址
path_ =tkinter.filedialog.askopenfilename()
# 通过replace函数替换绝对文件地址中的/来使文件可被程序读取
# 注意:\转义后为\,所以\\转义后为\
path_ =path_.replace("/", "\\")
# path设置path_的值
path.set(path_)
return path
# 得到的DataFrame读入所有数据
data = pd.read_excel(FILENAME, header=0, usecols="A,B,C,D,E,F,G,H,I")
# DataFrame转化为array
DataArray = data.values
# 读取已使用年限作为标签
Y = DataArray[:, 8]
# 读取其他参数作为自变量,影响因素
X = DataArray[:, 0:8]
# 字符串转变为整数
for i in range(len(Y)):
Y[i] = int(Y[i].replace("年", ""))
X = np.array(X) # 转化为array
Y = np.array(Y) # 转化为array
root = Tk()
root.geometry("+500+260")
# 背景图设置
canvas = tk.Canvas(root, width=600, height=200, bd=0, highlightthickness=0)
imgpath = '1.jpg'
img = Image.open(imgpath)
photo = ImageTk.PhotoImage(img)
#背景图大小设置
canvas.create_image(700, 400, image=photo)
canvas.pack()
path = StringVar()
#标签名称位置
label1=tk.Label(text = "目标路径:")
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐




weixin_38611388
- 粉丝: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- LoadRunner中配置WebSphere监控指南
- XSLT中文参考手册:元素详解
- C++Builder6实战教程:14章精讲与实例分析
- Zend Framework 1.0 中文教程:入门数据库驱动应用
- C++编程入门:从零开始探索编程世界
- Ruby编程指南:从新手到专业者
- ARM ADS1.2开发详解:从创建工程到AXD调试
- 实时字数统计:输入限制250字
- 在Eclipse中集成Gridsphere框架:开发与调试指南
- SIP协议详解:从基础到应用
- 希腊字根解密:morph与英文单词的故事
- JPA入门指南:快速理解与实战示例
- 数据库分页技术详解与实现
- C语言笔试题目集锦
- 基于实例学习:实例存储与局部逼近的优势与挑战
- ArcGIS Engine应用开发教程
